
統計検定1級受検体験記とその意義

Image by Freepik
この記事の概要
この記事はpaiza Advent Calendar 2023の12/6の記事になります。
この記事の前半には統計検定1級の受験体験記と関連参考書の主観的評価について、後半には学習を経てデータをどう捉えるようになったかの参考事例が書かれています。
対象読者
データを客観的に捉えるための力を養いたい人
統計検定を受検しようか悩んでいる人
自身の執筆スタンスとしては、事前情報がなくても読み切れる記事を目指していますが、今回の記事の後半部分は統計検定2級相当の知識がない(あるいは持っていたとしても)と難しいかもしれません。
統計検定1級を受けてきました
2023年11月19日(日曜日)に統計検定1級試験がありまして、学習院大学に赴きました。
2019年に適当に勉強して2級をとって以来の勉強となりました。
勉強の目的としては以下の3つで、下記3つが満たされるなら不合格でも構わないというスタンスで挑みました。
統計モデルを自在に構成できるだけのセンスを磨く
統計理論の適用限界(数理的前提)を理解する
数学(確率、解析、線型代数etc)を勉強し直す
実際のところ、統計検定1級は上記目的に対する非常に良いターゲットとして機能しました。
統計応用のほうは勉強量が足りずダメそうですが、統計数理の方はワンチャン可能性がある感じの出来になりました。
勉強に使ったもの
来年また受けるかどうかわからない自分のためにも軽くまとめることにします。
下記に挙げる本だけだと、理工学を選択する場合、実験計画法や時系列解析などに対して脆弱なので、真面目に対策するならもう2,3冊は足してもいいかもしれません。
(2023年の統計応用の理工学は、統計数理のさらに難しい版という感じだったので、来年受けるなら理工学選択から逃げるかもしれません。ぼくは人文科学に鞍替えするんだ。)
日本統計学会公式認定 統計検定準1級対応 統計学実践ワークブック
元々準1級から受けるつもりだったのですが、これから始めたのはあらゆる意味で失敗でした。わかりやすさの面でも下の書籍からはじめたほうがよいです。
現代数理統計学の基礎 (共立講座 数学の魅力)
有名な書籍であり、推薦図書にも指定されています。統計検定1級の統計数理分野に対する標準的な書籍だと言えます。
あくまで数理統計学の基礎であり統計学の基礎ではないので、重量級の数学が何食わぬ顔をして飛んでくるし、プログレスバーが全く進みません。
数力が足りないと間違いなく枕か積読になるので他の本を迂回することになります。(やはり大学では数学を勉強すべきですね。)
日本統計学会公式認定 統計検定1級対応 統計学
この本はワークブックよりはるかに良いです。
多変量正規分布の条件付き期待値の導出などは上の本には載ってなかったと思います。
この本も導出はないか非常に手薄ですが、要点が手短にまとまっているので復習本として役に立ちました。
統計1級過去問
今思うとこれをさっさと開いて解くべきでした。
90分の試験と考えると過酷すぎるものも含まれていますが、設問として問われるべきものが問われている感覚もあります。
私は2週間前ぐらいから解き始めましたが、普通に遅すぎたので前日に一夜漬けすることになりました。
詳解演習 確率統計
これは、比較的簡単な問題が答え付きでまとめられています。
私はあまりに数学力がなまっていたので、これを通読しながら頭の中で計算するようなトレーニングを積むことから始めました。
勉強に使ってないけど持ってるもの
回帰分析(新装版)
この本は結局受検後に読み始めましたが、現代数理統計学の基礎ではカバーしきれていない回帰分析の詳細が緻密に書かれているので、とても良い本です。要求数学レベルもかなり高いですが、議論を追うだけでいいなら必要に応じて読み飛ばすのもありかと思います。
現代数理統計学
こちらも推薦図書になっています。結局時間不足で読むことができなかったですが、時間があるときに目を通したいところですね。
その他
いろいろ持ってますが割愛
バイアスなのか、ガタつきなのか
ある日、社内slackを見ていると高校生の身長に関する以下の投稿が話題になっていました。
元々は3学年分出していたんですが、読みづらすぎたんですよね
— ところてん (@tokoroten) December 4, 2023
最後まで高2のデータを出すか、高3のデータを出すか迷っていた覚えがある https://t.co/epXLQEhStm pic.twitter.com/uvzg7bJJWn
このポストのグラフを見た時、私は「2年前ぐらいに自分が描いたグラフと似ている」と気づきました。
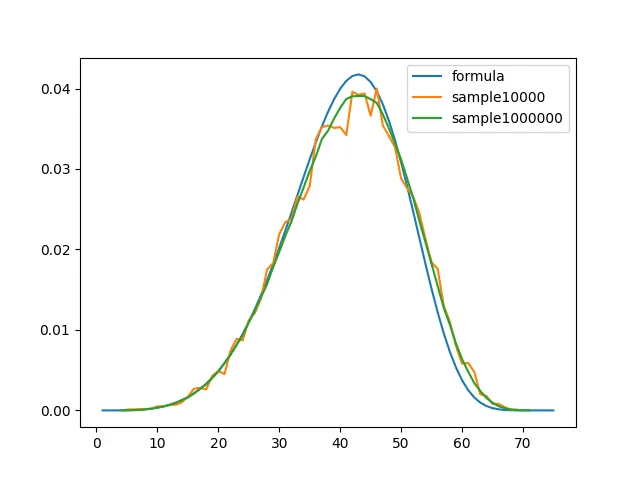
具体的には分布の中心部のガタつきが大きく、分布の裾にいくにつれて滑らかになるといった感じでした。
2年前に私が書いたグラフは、完全に数学的なプロセスに基づくサンプリングであり、そこに人の感情の介入余地(バイアス)はなかったはずです。
身長の分布についても全く同じようなガタつきがあり、このガタつきの解釈次第では判断を誤る可能性があるわけです。
2年前の自分ではこのガタつきが気になっていましたが、適切な説明を与えることができませんでした。
しかし数理センスが高まった今の自分であれば、このガタつきに対する説明を与えられるのではないかと考えました。
これがこの記事のもうひとつのメイントピックです。
ヒストグラムの数理モデルとその分散
問題を具体的にするため上記の高校生男子の身長の事例を想定します。
サンプルサイズを$${N}$$(人)とします。
身長が$${h-0.5}$$cm ~ $${h+0.5}$$cmの区間$${B_h}$$に含まれる確率を$${p(h)}$$とします。(これは身長が正規分布に従うとして平均と分散が分かると数値積分すれば具体値を求めることができます。)
ヒストグラムはそれぞれの区間に何人の高校生が含まれるか(これを確率変数$${Y_h}$$とする)を計数していくことで描き出すことができます。
例えば高校生が$${B_{169}}$$(168.5cm~169.5cmの区間)に含まれる確率は上述の通り$${p(169)}$$、そうでない確率は$${1-p(169)}$$となります。
$${N}$$人の高校生について区間に含まれる、含まれないというような独立な振り分けを行うので、$${Y_h}$$は二項分布$${Bin(N, p(h))}$$に従うことがわかります。(ビンの全体としては多項分布に従うわけですが、この議論ではその前提は不要です。)
二項分布に従う$${Y_h}$$の期待値$${E[Y_h]}$$と分散$${V[Y_h]}$$は統計の初等的な教科書にも記述されている通り、$${E[Y_h] = Np(h)、V[Y_h]=Np(h)(1-p(h))}$$となります。
また観測確率を表す$${Y_h/N}$$について同様に期待値と分散を計算すると、
$${E[Y_h/N] = Np(h)/N = p(h)}$$
$${V[Y_h/N] = Np(h)(1-p(h))/N^2 = p(h)(1-p(h))/N}$$
となります。
データを客観的に捉える
我々が確かに観測した縦方向のガタつきは、数理統計的に解釈すると結局のところ観測確率$${Y_h/N}$$の分散$${V[Y_h/N]}$$です。
これは$${p(h)}$$に対する2次関数であり、$${p}$$の増加に対し2次関数的に増加していくことがわかり、またサンプルサイズ$${N}$$が増加すると減少することがわかります。
$${p(h)}$$は分布の中心に近づくにつれて(例えば$${h=170}$$)大きくなり、分布の裾に行くにつれて(例えば$${h=190}$$)小さくなるので、170cmの区間に含まれる人数は190cmの区間に含まれる人数よりもばらつきが大きく、ガタつくのは必然であるというわけです。
これが私のプロットでも高校生の身長のプロットでも現れた中心部でのガタつきの正体というわけです。
与えられたグラフからは、サンプルサイズ$${N}$$及び分散の読み取りが困難(煩雑)なためこれ以上の分析は諦めますが、偶然の可能性が高い(帰無仮説を棄却できない)のではないかと考えます。
(身長が正規分布に従うことを仮定し平均、分散を推定し、それに基づきpをベルカーブに対して数値積分して求め、期待度数と観測度数に対するカイ二乗分布を用いた適合度検定を適用するか、素直に正規分布近似してそのデータが何σに相当するかを調べることになります。
ちなみに中央部については以上で良いと思いますが、裾の部分ではあまり良くなさそうです。裾部ではビンに入るデータ数が小さく二項分布を正規分布で近似できるという前提があやしいものとなるからで、そうした感覚も試験では問われることがあります。)
統計の学習と統計センス
ここまでの議論で必要だったことは、実は二項分布$${Bin(n,p)}$$の分散が$${np(1-p)}$$であるという2級相当の知識でしかありません。
さらに任意の分布についてヒストグラムを描けば上記の理由により必ず中心部(確率密度関数が大きいところ)ががたつくわけなので、専門家の間では常識化していてもおかしくない話でもあります。
しかしそれを誘導なく数理モデルを構成し説明(論証)しきれる力が身についたことにはかなり自信がつきました。
これは2級相当の自分からしたらおまじないや神秘主義で雑に片付けていたであろう部分です。
正規分布の話をしているのに、ヒストグラムのモデリングにはその区間確率についての二項分布が現れるというのは、昔の自分では自律的にそれを発見するのが難しかったでしょう。
私はいわゆる判断型の人間であり、ストーリーベースで思考しがちなので、データからいろいろな発見を見出してしまう(アノマリーを誤認識する)のでしょう。
しかし改めて数学と統計を学び直したことにより、より客観的で堅牢な思考能力が身についたと思います。
また機械学習の書籍を読む上である程度通用する数学リテラシーも身についたかと思います。
2ヶ月ぐらいかなりしんどかった時もありましたが、最後は勉強してよかったなと思います。
天下り的なもののように見えていた統計理論が、見事に数理と論証の積み重ねであると実感したい人にはとても適切な検定試験だと感じました。
この記事が気に入ったらサポートをしてみませんか?