
金投資を考える

サブテーマ:S&P500と金の最適な保有割合って??
1 初めに
今回、安全資産の代表格である金(Gold)の投資について検証します。前回、株式(S &P500)と債券(長期米国債)の組み合わせを検証した際と同じPYTHONコードで実行してみた結果です。こちらもかなり有益な情報になってますので、単独でご報告します。
結論は下記の通りS&P500と金を両方持っておくことは非常に有効です。このチャンネルでは、今後も投資・PYTHONの活用法に有益な情報を発信していきます。応援よろしくお願いします!!
今回の結論:金を25〜50%程度の組み合わせはアリ!!
積立時: 25%で劇的効果!!
取崩し時:元本割れの確率Down!! 推奨:50%!


知人よりプログラム部分が難しくてよくわからないとご指摘をいただきました。そのためこのチャンネルでは、PYTHONを使った米国株投資に関わるさまざまな調査の結果OUTPUTにこだわった記事にします。投資に関わる身近な疑問にも答えていきますので、投資リテラシー向上にお役立ちを目指します!!
なお、全ての解析データは引き続き、PYTHONを活用してコード全文も掲載します。Googleコラボならまずは”コピペ”でチャレンジできます。これから勉強始めたい方にも、プログラミングで何ができるのかを知る良いチャンスとなればと思っていますので応援お願いします!!
2 豆知識
1)金投資とは?
金投資は古来から価値保存の手段として利用されてきました。金は物理的な価値を持ち、通貨としての歴史もあります。近年では、金を保有することはインフレーション対策や市場の不確実性に対するヘッジとして見られています。金価格は一般的に経済が不安定な時に上昇する傾向があり、これは金がリスクオフの資産として投資家に認識されているためです。また、金は他の資産と低相関であることが多いため、ポートフォリオの分散を図る上で重要な役割を担います。
2)株式と金を組み合わせる意味って?
金とS&P 500(代表的な株式指数)を組み合わせることで、ポートフォリオのリスクを有効に分散できます。株式は経済成長に伴う収益の可能性が高い一方で、市場の変動によるリスクも大きいです。一方、金は経済的な不確実性やインフレの期間中に価値が増す可能性があります。このため、金を含むポートフォリオは市場の急激な変動から保護する効果が期待でき、長期的な安定した成長を目指す投資戦略に適しています。金と株式の両方を含むことで、相補的な資産配分を実現し、全体的な投資リスクの低減を図ることができます。
3 実践
1)調査内容
今回、対象はS&P 500ETFであるSPYと、金価格に連動するETFであるGLDです。株式と金を25%づつ割合を変更した場合の下記①から④の確認を行います。
①時系列チャートでトレンド確認
②リスクとリターン、最大ドローダウンとシャープレシオの計算
③積立時のシミュレーション
④取崩し時のシミュレーション
2)時系列チャートでトレンド確認
Yahoo Financeから過去20年分の株価データを取得し、月毎のデータに変換しリターンとリスク(標準偏差)を計算します。今回、比率をSPY:GLDを、100〜0%まで25%づつウエイトを定義し、それぞれのトレンドとリターン等の指標を計算しています。その後、時系列プロットとしてはじめの日を100としたグラフと、変化率を正確に表示するため対数軸メモリとした2つのグラフをプロットしています。
pip install japanize-matplotlib
import yfinance as yf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import japanize_matplotlib # 日本語表示に対応
# 対象のティッカーシンボル
tickers = ['SPY', 'GLD']
# データの取得
data = yf.download(tickers, start="2004-04-01", end=pd.Timestamp.now().strftime('%Y-%m-%d'))['Adj Close']
# ティッカーの順序を正確に指定
data = data[['SPY', 'GLD']]
# ウェイトを定義
weights = [(1.0, 0.0), (0.75, 0.25), (0.5, 0.5), (0.25, 0.75), (0.0, 1.0)]
portfolio_metrics = pd.DataFrame()
portfolio_time_series = pd.DataFrame(index=data.index)
# 各ウェイトに基づいてポートフォリオラベルのリストを生成
portfolio_labels = [f"SPY {weight[0]*100}% : GLD {weight[1]*100}%" for weight in weights]
# リスクフリーレートの設定
risk_free_rate = 0.01
# 各ポートフォリオに対して計算を実行
for weight in weights:
portfolio_label = f"SPY {weight[0]*100}% : GLD {weight[1]*100}%"
# 月次リターンの計算
returns = data.pct_change().dot(weight)
cum_returns = (1 + returns).cumprod()
cum_returns.iloc[0] = 1 # 最初のNaNを補完
portfolio_time_series[portfolio_label] = cum_returns
# 年次リターン
annual_returns = (1 + returns).resample('Y').prod() - 1
avg_annual_return = annual_returns.mean()
# 年次換算標準偏差
annual_std = returns.std() * np.sqrt(252)
# 最大ドローダウンの計算
rolling_max = cum_returns.cummax()
drawdown = (cum_returns - rolling_max) / rolling_max
max_drawdown = drawdown.min()
# シャープレシオの計算
sharpe_ratio = (returns.mean() * 252 - risk_free_rate) / annual_std
# 結果の保存
portfolio_metrics[portfolio_label] = [avg_annual_return, annual_std, max_drawdown, sharpe_ratio]
# データフレームの列をこのラベルリストに基づいて順序付け
portfolio_metrics = portfolio_metrics[portfolio_labels]
portfolio_time_series = portfolio_time_series[portfolio_labels]
# メトリクスのインデックス名を設定
portfolio_metrics.index = ['年次リターン', '年次換算標準偏差', '最大ドローダウン', 'シャープレシオ']
# カラーマップを生成
colors = cm.viridis(np.linspace(0, 1, len(portfolio_labels))) # グラデーションカラーマップ生成
# 軸の範囲を動的に調整
max_std = portfolio_metrics.loc['年次換算標準偏差'].max() * 1.2
max_return = portfolio_metrics.loc['年次リターン'].max() * 1.2
plt.xlim(0, max_std)
plt.ylim(0, max_return)
# 対数スケールに変換
y_values = [50, 100, 200, 300, 400, 500, 1000]
log_y_values = np.log10(y_values)
# 時系列グラフのプロット
fig, axes = plt.subplots(2, 1, figsize=(9, 9))
# 通常の時系列グラフ
colors = cm.viridis(np.linspace(0, 1, len(portfolio_labels))) # グラデーションカラーマップ生成
portfolio_time_series.plot(ax=axes[0], color=colors)
axes[0].set_title('通常の時系列グラフ')
axes[0].set_ylabel('累積リターン')
axes[0].grid(True)
# スタートを100に固定し対数軸メモリ
normalized_portfolio = portfolio_time_series.divide(portfolio_time_series.iloc[0]) * 100
log_portfolio = np.log10(normalized_portfolio.replace(0, np.nan).dropna())
log_portfolio = log_portfolio[portfolio_labels] # 正しい順序で再割り当て
log_portfolio.plot(ax=axes[1], color=colors)
axes[1].set_title('対数スケールの正規化された時系列グラフ(開始値を100に設定)')
axes[1].set_ylabel('インデックス化されたリターン(対数スケール)')
axes[1].set_yticks(log_y_values) # Y軸のメモリ位置を設定
axes[1].set_yticklabels(y_values) # Y軸のメモリラベルを設定
axes[1].grid(True)
plt.tight_layout()
plt.show()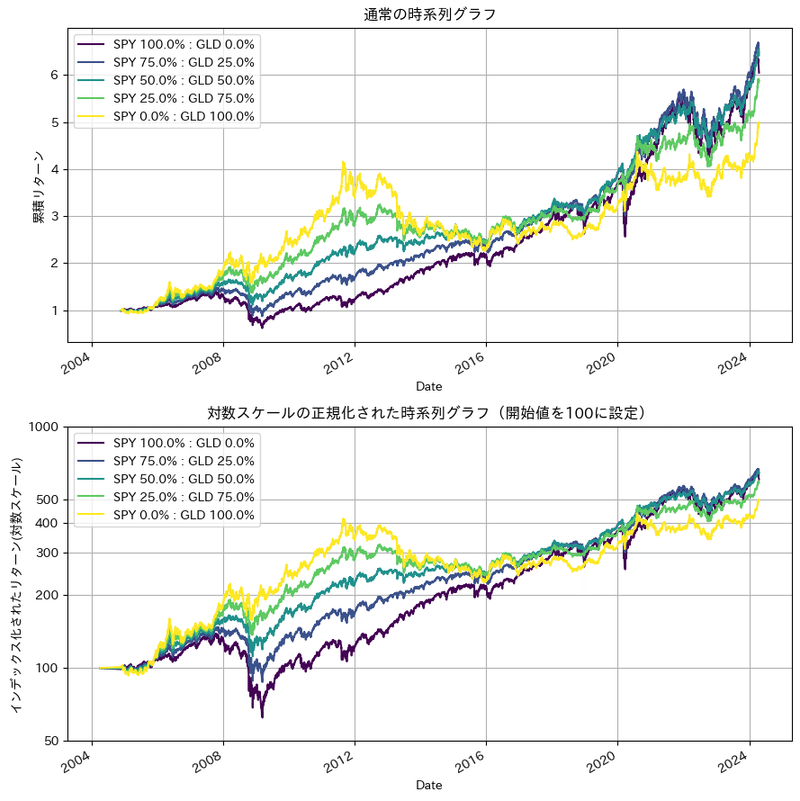
時系列にプロットした結果、2008年以降リーマンショック、2020年のコロナショック後の傾向が顕著です。株式100%では落ち込みが大きいですが、金の保有率が高くなるにつれ落ち込み幅は小さくなります。債券と異なり下落しないわけではないまた各ショック後の上昇時には株価以上の割合で資産が増加しています。
これは金と株式は相関係数としてはマイナスではなく0に近い挙動を示しています。この相関係数については次回以降の記事で深掘りできればと考えてます。
3)リスクとリターン、最大ドローダウン、シャープレシオの出力
次に、各割合を変更した際のリスクとリターン及び最大ドローダウン、シャープレシオを出力します。
# 散布図をプロット
plt.figure(figsize=(7, 4))
for idx, label in enumerate(portfolio_labels):
annual_return = portfolio_metrics.loc['年次リターン', label]
annual_std_dev = portfolio_metrics.loc['年次換算標準偏差', label]
plt.scatter(annual_std_dev, annual_return, color=colors[idx], label=label)
plt.xlabel('年次換算標準偏差')
plt.ylabel('年次リターン')
plt.title('年次換算標準偏差 vs 年次リターンの散布図')
plt.legend(title="ポートフォリオ", bbox_to_anchor=(1.05, 1), loc='upper left')
plt.grid(True)
リターン、リスク(標準偏差)を散布図でプロットすると、株式100%をスタートした”く”の字の形状になっています。株式:金=1:1である、くの折り返し点に置いてリターンの割にリスクが小さいことを示しています。

これらをテーブルとして出力し比較します。
・年次リターン 良 株式100%>0% 悪
・リスク(標準偏差) 良 最小値 株式50%
・最大ドローダウン 良 最小値 株式25%
・シャープレシオ 良 最小値 株式50%
まとめると、株式100%ではリターンが最大になるが、最大ドローダウンも大きくリスクが高い。金を50%では、リスク、シャープレシオが最小値となり投資効率が良いことがわかります。
3)積立シミュレーション
前回と同じく先ほど計算したリスクとリターンを使って20年間の積立シミュレーションをしてみます。今回は初期投資額200万として月々10万円を積みたてを1000回実施した際の資産額をヒストグラムで表示させてみます。
import numpy as np
import matplotlib.pyplot as plt
# パラメータ設定
initial_investment = 200 # 初期投資額
monthly_investment = 10 # 月次積立額(10万円)
investment_duration = 240 # 投資期間(月)
simulations = 1000 # シミュレーション回数
# シミュレーションの実行と結果の収集
all_final_values = []
for label in portfolio_labels:
# portfolio_metrics から月次リターンの平均と標準偏差を取得
monthly_return_mean = portfolio_metrics.loc['年次リターン', label] / 12
monthly_return_std = portfolio_metrics.loc['年次換算標準偏差', label] / np.sqrt(12)
final_values = np.zeros(simulations)
for simulation in range(simulations):
total_value = initial_investment
for month in range(investment_duration):
monthly_return = np.random.normal(monthly_return_mean, monthly_return_std)
total_value += monthly_investment
total_value = total_value * (1 + monthly_return)
final_values[simulation] = total_value
all_final_values.append(final_values)
# 全シミュレーション結果からビンの範囲を決定するための配列を生成
flat_all_final_values = [value for sublist in all_final_values for value in sublist]
min_value = min(flat_all_final_values)
max_value = max(flat_all_final_values)
bins = np.linspace(min_value, max_value, 200)
# 投資元本の計算(初期投資額 + 月次積立投資額の合計)
total_investment = initial_investment + monthly_investment * investment_duration
# x_maxをシミュレーション結果の最大値を基に設定
x_max = total_investment*6
# グラフの描画
fig, axes = plt.subplots(len(portfolio_labels), 1, figsize=(9, 3 * len(portfolio_labels)), sharex=False)
for i, label in enumerate(portfolio_labels):
ax = axes[i]
ticker_final_values = all_final_values[i]
median_value = np.median(ticker_final_values)
Q1 = np.percentile(ticker_final_values, 25)
Q3 = np.percentile(ticker_final_values, 75)
# ヒストグラムをプロット(ここでカラーマップの色を使用)
n, bins, patches = ax.hist(ticker_final_values, bins=bins, alpha=0.75, color=colors[i], label=f'{label} 最終資産額')
# Q1からQ3の間を透明な色で塗りつぶす(透明度調整で同じカラーを使用)
ax.fill_betweenx([0, max(n)], Q1, Q3, color=colors[i], alpha=0.3)
# 投資元本、中央値、Q1、Q3の線を追加
ax.axvline(x=total_investment, color='r', linestyle='--', label=f'投資元本: {total_investment:.0f}')
ax.axvline(x=median_value, color='green', linestyle='--', label=f'中央値: {median_value:.0f}')
ax.axvline(x=Q1, color='blue', linestyle='--', label=f'Q1: {Q1:.0f}')
ax.axvline(x=Q3, color='purple', linestyle='--', label=f'Q3: {Q3:.0f}')
ax.set_title(f'{label} - 最終資産額の分布')
ax.set_xlabel('最終資産額')
ax.set_ylabel('頻度')
ax.legend(loc='upper left', bbox_to_anchor=(1.05, 1), borderaxespad=0.)
ax.grid(True)
ax.set_xlim(0, x_max)
plt.tight_layout()
plt.show()
上から株式100%で下が0%ですが、それぞれどちらか単独で保有するより組合せた場合の方が、中央値もQ 1,Q3点も資産が増加した傾向です。また元本割れの確率も低下しており、この組み合わせは有効であることが示されています。
4)取崩しシミュレーション
同様に、取崩しのシミュレーション効果を確認します。今回5000万円の元手に対し、月々25万円(年300万円:年率6%)の定額取り崩しの際の資産額の推移をシミュレーションし、時系列で表示します。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# パラメータ設定
initial_investment = 5000 # 初期投資額(5000万円)
withdrawal_amount = 25 # 月次取り崩し額(25万円)
investment_duration = 360 # 投資期間(月)
simulations = 1000 # シミュレーション回数
# portfolio_metrics からデータを抽出
monthly_returns = portfolio_metrics.loc['年次リターン'] / 12 # 年次リターンを月次に変換
monthly_std_devs = portfolio_metrics.loc['年次換算標準偏差'] / np.sqrt(12) # 年次標準偏差を月次に変換
# 時系列グラフのプロット
fig, axes = plt.subplots(len(portfolio_labels), 1, figsize=(8, 3 * len(portfolio_labels)), sharex=False)
for i, label in enumerate(portfolio_labels):
monthly_values_all_simulations = []
for simulation in range(simulations):
monthly_values = []
total_value = initial_investment
for month in range(investment_duration):
monthly_return = np.random.normal(monthly_returns[label], monthly_std_devs[label])
total_value = total_value * (1 + monthly_return) - withdrawal_amount
monthly_values.append(max(total_value, 0))
monthly_values_all_simulations.append(monthly_values)
# Q1、中央値、Q3の計算
median_values = np.median(monthly_values_all_simulations, axis=0)
q1_values = np.percentile(monthly_values_all_simulations, 25, axis=0)
q3_values = np.percentile(monthly_values_all_simulations, 75, axis=0)
# サブプロットにプロット
ax = axes[i]
ax.plot(median_values, label=f'{label} 中央値', color=colors[i])
ax.fill_between(range(investment_duration), q1_values, q3_values, color=colors[i], alpha=0.2)
ax.axhline(y=initial_investment, color='grey', linestyle='--', label='初期投資額') # 初期投資額の線
ax.set_ylim(0, initial_investment * 2) # Y軸の範囲を設定
ax.set_title(f'{label}')
ax.set_ylabel('資産額 (万円)')
ax.legend()
ax.grid(True)
# X軸のラベルは最下部のサブプロットのみに表示
axes[-1].set_xlabel('月')
plt.tight_layout()
plt.show()
取崩しの場合においても株式や金を単独で保有するより、組み合わせて保有している方が、元本割れの期間の確率が低くかつむしろ資産が増加する確率が増すことが示されています。
4 まとめ
今回、S&P500に対し、金ETFを割合で変更した際の各種指標の変化、積立及び取崩しのシミュレーションを実施しました。その結果、株式のみの場合と比べ下落率の低減が可能であり、株価上昇局面において同等か同等以上の資産価値増加の効果があります。
次回以降、それぞれ最適な保有割合について深掘りしたり、株式と金、債券などさらに複数の場合など、わかりやすく示していきたいと考えてますので、引き続き応援よろしくお願いします。
補足)
今回の調査結果を参考にした投資先として、日興アセットマネジメントより投資信託”Tracers S&P500ゴールドプラス”という商品がありますので簡単に紹介してみます。
この商品は、元本100%に対し、先物商品を組み合わせ、S&P500を100・金を100 合計200%分の投資をする商品です。その割に信託手数料も年率0.2%程度です。ある意味レバレッジ商品であるため、NISA対象商品ではありませんので、NISA枠以上の資産がある方が特定口座で運用する商品としては魅力的です。今回の記事を見て金投資に興味がある方はぜひ見てみてください。(案件ではありません。)
*今回の結果は、それぞれの割合で購入した仮想の投資信託商品のようなシミュレーションです。個々の商品で運用するなら厳密にはリバランスを考慮した積立や取崩しシミュレーションが必要です。ややこしくなるため省略していますが全体感の把握には今回の結果がわかりやすいと考えて記事にしています。
*今回の結果も、過去20年の実績をもとにシミュレーションした結果です。今後の結果を保証するものではありません。実際の投資判断はご自身にてお願いいたします。
以下、過去記事、AI時系列予測等のご紹介
他サイトですがココナラで、A I(LSTM)を使った株価予測の販売もやってます。こちらではFREDから、失業率や2年10年金利、銅価格等結果も取得しLSTMモデルで予測するコードとなってますので興味があれば見てみてください。またその他2件も米国株投資とは直接関係はありませんがプログラム入門におすすめですのでみてみてください。
チャンネル紹介:Kota@Python&米国株投資チャンネル
過去の掲載記事:興味があればぜひ読んでください。
グラフ化集計の基礎:S &P500と金や米国債を比較してます。
移動平均を使った時系列予測
この記事が気に入ったらサポートをしてみませんか?