Google Colab で Falcon-7B-Instruct を試す

「Google Colab」で「Falcon-7B-Instruct」を試したので、まとめました。
【注意】「Google Colab Pro/Pro+」で使えるA100で動作確認してます。
1. Falcon
「Falcon」は、アラブ首長国連邦の首都アブダビに拠点を置く研究機関「Technology Innovation Institute」が開発したオープンソースのLLMです。商用利用可能なライセンスで公開されています。「Open LLM Leaderboard」でLlama系のモデルを抜いて1位を獲得したことで話題になりました。
2. Falconのモデル
「Falcon」の言語モデルは、次の4種類のモデルが公開されています。
・tiiuae/falcon-40b
・tiiuae/falcon-40b-instruct
・tiiuae/falcon-7b
・tiiuae/falcon-7b-instruct
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) メニュー「編集→ノートブックの設定」で、「ハードウェアアクセラレータ」で「GPU」で「A100」を選択。
(2) パッケージのインストール。
# パッケージのインストール
!pip install transformers accelerate einops(3) トークナイザーとパイプラインの準備。
今回は、「Falcon-7B-Instruct」を指定しています。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
# トークナイザーとパイプラインの準備
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b-instruct")
pipeline = transformers.pipeline(
"text-generation",
model="tiiuae/falcon-7b-instruct",
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto",
)(4) 推論の実行。
プロンプト書式は特定のものはないらしいということで、QAプロンプトで動作確認しました。日本語は精度的にイマイチだったので、英語を使ってます。
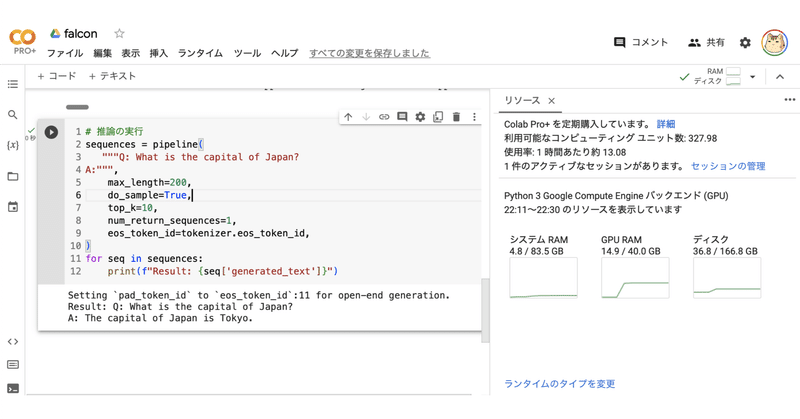
# 推論の実行
sequences = pipeline(
"""Q: What is the capital of Japan?
A:""",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")Result: Q: What is the capital of Japan?
A: The capital of Japan is Tokyo.関連
この記事が気に入ったらサポートをしてみませんか?