
HuggingFace での Flash Attention 2 の使い方

以下の記事が面白かったので、かるくまとめました。
【注意】 この機能は実験的なものであり、将来のバージョンでは大幅に変更される可能性があります。「Flash Attendant 2 API」は近い将来「BetterTransformer API」に移行する可能性があります。
1. Flash Attention 2
「Flash Attendant 2」は、Transformerベースのモデルの学習と推論の速度を大幅に高速化できます。
リポジトリのインストールガイドに従って、「Flash Attendant 2」をインストールしてください。これをインストールすることで、HuggingFaceの「Flash Attention 2」の機能も利用できるようになります。
次のモデルは 「Flash Attendance 2」をネイティブにサポートしています。
・Llama
・Falcon
「Flash Attention 2」は、モデルのdtypeが「fp16」または「bf16」であり、NVIDIAのGPUで実行される場合にのみ使用できます。
2. 使い方
モデルで「Flash Attention 2」を有効にするには、from_pretrained() に「use_flash_attention_2=True」を指定します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
use_flash_attention_2=True,
)このモデルをファインチューニング・推論に使用します。
3. 予想される高速化
「Flash Attention 2」は、特に長いシーケンスの場合、ファインチューニング・推論の大幅な高速化の恩恵を受けることができます。
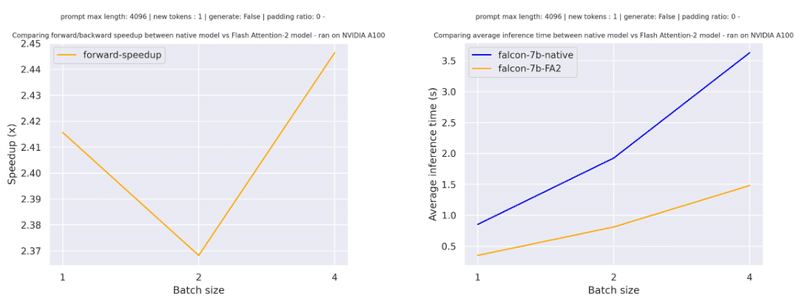
3-1. Falconの高速化
以下は、「tiiuae/falcon-7b」のシーケンス長4096・paddingトークンなし・様々なバッチサイズでの単純な前方パスで予想される高速化です。
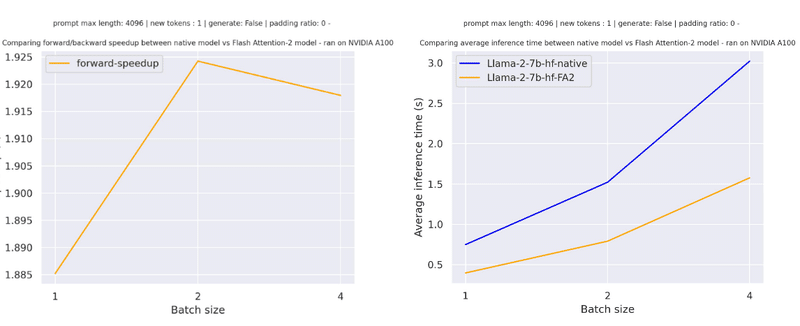
3-2. Llamaの高速化
以下は、「meta-llama/Llama-7b-hf」のシーケンス長4096・paddingトークンなし・様々なバッチサイズでのでの単純な前方パスで予想される高速化です。
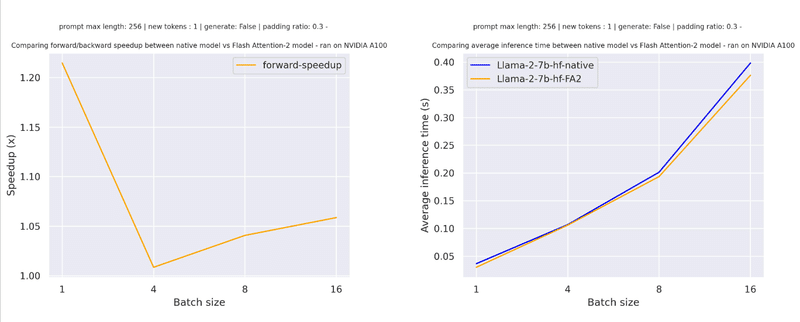
3-3. paddingトークンを含むシーケンス
paddingトークンを含むシーケンスの場合、Attentionスコアを正しく計算するには、入力シーケンスのpadding/padding解除が必要になります。比較的短いシーケンス長の場合、純粋な前方パスでは、これによりオーバーヘッドが発生し、速度向上はわずかです (入力の30%以下がpaddingトークンで埋められています)。
しかし、シーケンス長が長い場合は、高速化の恩恵を受けることができます。
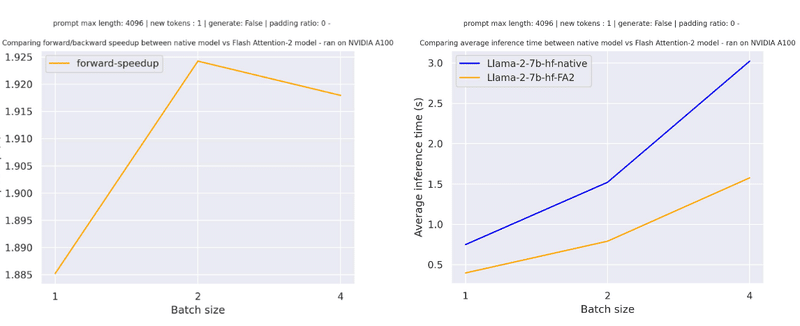
「Flash Attention」を使用すると、Attentionの計算のメモリ効率が向上します。つまり、CUDA OOM の問題に直面することなく、はるかに長いシーケンス長で学習できることになります。詳しくは、公式リポジトリを参照してください。
4. 高度な使い方
「Flash Attention 2」を多くの既存の機能と組み合わせてモデルを最適化できます。
4-1. Flash Attendant 2 + 8bit量子化
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
use_flash_attention_2=True,
)4-2. Flash Attendant 2 + 4bit量子化
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
use_flash_attention_2=True,
)4-3. Flash Attendant 2 + PEFT
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaForCausalLM
from peft import LoraConfig
model_id = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
use_flash_attention_2=True,
)
lora_config = LoraConfig(
r=8,
task_type="CAUSAL_LM"
)
model.add_adapter(lora_config)
# train your model関連
この記事が気に入ったらサポートをしてみませんか?