
Code Llama の概要

以下の記事が面白かったので、かるくまとめました。
・Introducing Code Llama, a state-of-the-art large language model for coding
1. はじめに
「Code Llama」は、コードと自然言語の両方からコードとコードに関する自然言語を生成できる最先端のLLMです。研究および商用利用が可能で、無料で利用できます。
「Code Llama」は「Llama 2」ベースで、次の3つのモデルを提供します。
・Code Llama : 基本的なコード生成モデル。
・Code Llama - Python : Pythonに特化したコード生成モデル。
・Code Llama - Instruct : 自然言語の指示を理解できるようにファインチューニングしたモデル。
ベンチマークテストではコードタスクにおいて、公的に入手可能な最先端のLLMよりも優れたパフォーマンスを示した。
2. Code Llama の概要
2-1. Llama2ベース
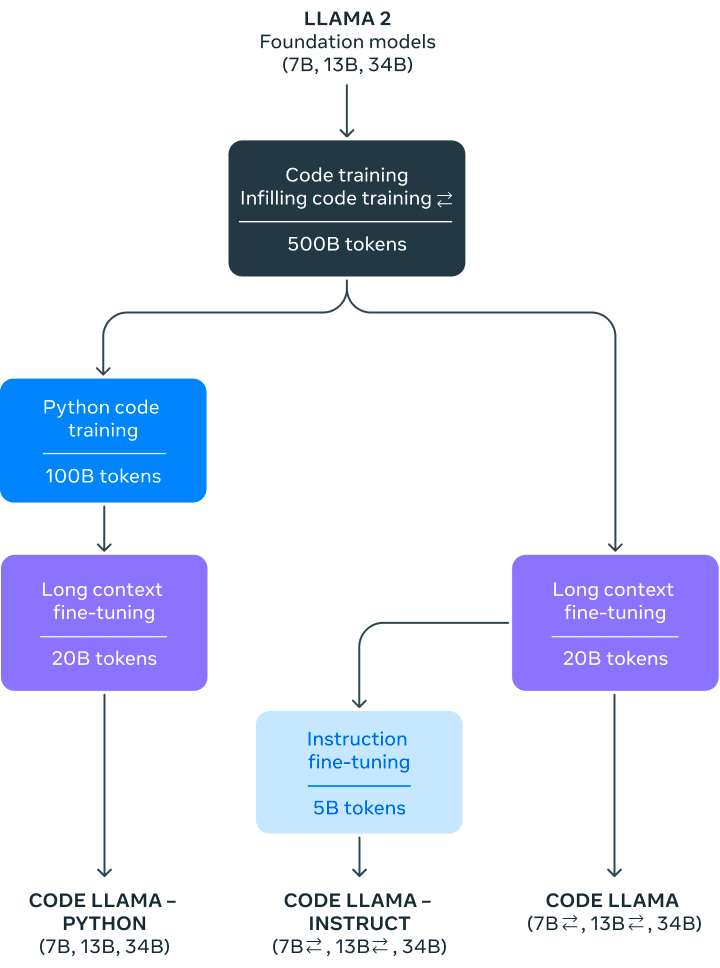
「Code Llama」は、「Llama 2」をコードに特化したバージョンで、コード固有のデータセットで「Llama 2」を追加学習し、同じデータセットからより多くのデータを長時間サンプリングすることによって作成されました。コードと自然言語の両方から、コードとコードに関する自然言語を生成できます (例: 「フィボナッチ数列を出力する関数を書いてください」)。 コード補完やデバッグにも使用できます。Python、C++、Java、PHP、Typescript (Javascript)、C#、Bash など、現在使用されている一般的な言語の多くをサポートしています。
2-2. モデルサイズ
7B、13B、34Bの3つのサイズの「Code Llama」をリリースしました。 これらの各モデルは、500B トークンのコードおよびコード関連データを使用して学習されます。 7B、13B のベースおよび指示モデルは、fill-in-the-middle (FIM) 機能でも学習されており、既存のコードにコードを挿入できるため、すぐにコード補完などのタスクをサポートできます。
3つのモデルは、さまざまなサービス提供要件とレイテンシー要件に対応します。 たとえば、7B モデルは単一のGPU で実行できます。 34Bモデルは最良の結果を返し、より優れたコーディング支援を可能にしますが、より小型の 7B および 13B モデルは高速であり、リアルタイム コード補完などの低遅延を必要とするタスクにより適しています。
2-3. コンテキスト長
「Code Llama」は、最大 100,000トークンのコンテキスで、安定したコード生成を提供します。 すべてのモデルは 16,000 トークンのシーケンスで学習され、最大 100,000 トークンの入力まで改善が見られます。
2-4. バリエーション
「Code Llama」をさらにファインチューニングしたバリエーション、「Code Llama - Python」と 「Code Llama - Instruct」も提供しています。
「Code Llama - Python」は、言語に特化したモデルです。Python コードの100Bトークンに基づいてさらにファインチューニングされています。
「Code Llama - Instruct」は、自然言語の指示を理解できるようにファインチューニングしたモデルです。指示チューニングは学習プロセスを継続しますが、目的は異なります。モデルには「自然言語指示」入力と期待される出力が供給されます。これにより、人間がプロンプトから何を期待しているのかをよりよく理解できるようになります。
3. Code Llama の評価
「Code Llama」を評価するために、「HumanEval」と「Mostly Basic Python Programming」(MBPP) という2つのベンチマークを使用しました。「HumanEval」は、ドキュメント文字列に基づいてコードを完成させるモデルの能力をテストし、「MBPP」は、説明に基づいてコードを記述するモデルの能力をテストします。
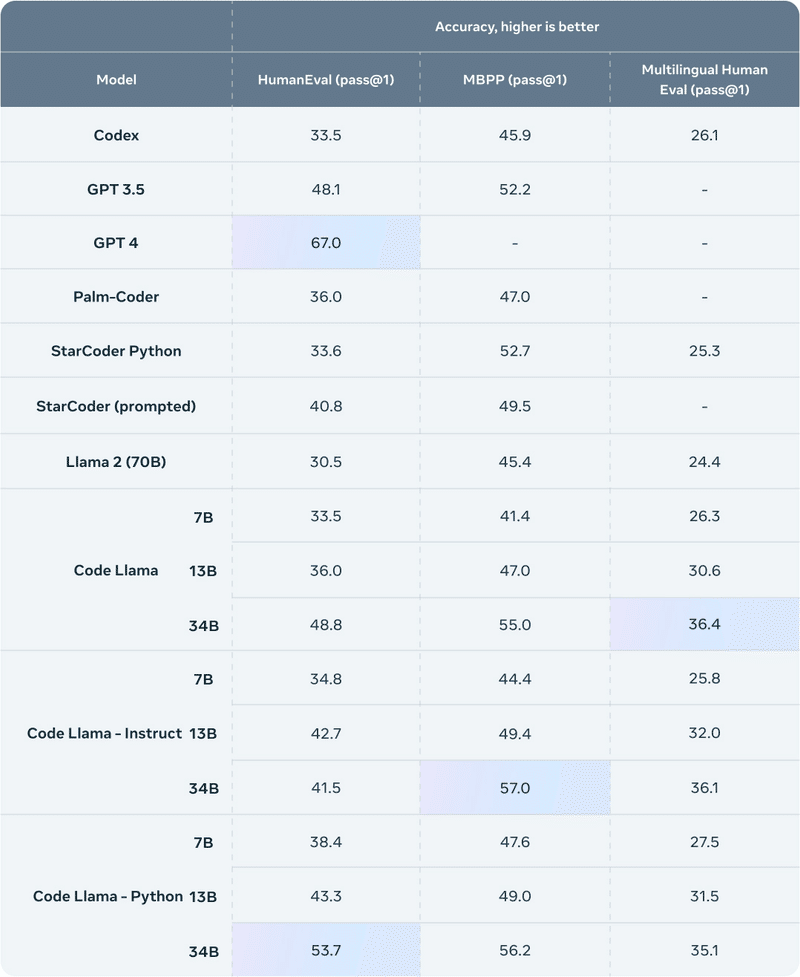
「Code Llama 34B」のスコアは、「HumanEval」で 53.7%、「MBPP」で 56.2% であり、他の最新バージョンと比較してもっとも優れていました。 最先端のオープン ソリューションであり、ChatGPT と同等になります。
関連
この記事が気に入ったらサポートをしてみませんか?