
Rayによる強化学習のハイパーパラメータのチューニング

以下の記事が面白かったので、ざっくり訳してみました。
・Using Ray for Reinforcement Learning - aureliantactics - Medium
1. 強化学習にRayを使用する
過去数週間、私は強化学習(RL)の「Ray」を調査してきました。Rayは「高性能分散実行エンジン」を提供し、「RLlib」(Scalable Reinforcement Learning)と「Ray Tune」(Hyperparameter Optimization Framework)が付属しています。
Rayには、RLアルゴリズムApe-X(DDPGおよびDQN)、PPO、A3C、ES、およびPGが含まれています。これらのアルゴリズムは、GymおよびAtari環境(パッケージの例を参照)、カスタム環境(Retro Gymなど)を訓練できます。
「Ray」の雰囲気をつかむために、簡単な訓練を行いました。
2. Rayの注意事項
注意事項がいくつかあります。
・「pip install ray」は機能しますが、git cloneインストールを使用した方が良いです。パッケージは頻繁に更新されているため、サンプルスクリプトと衝突するインスタンスがいくつかありました。
・「Ray」には、アルゴリズムのCPUおよびクラスターの使用状況を示すJupyterノートブックスクリプトがあります。
・「Ray」は結果をTensorBoardに出力します。「tensorboard — logdir=~/ray_results」と入力して、結果を視覚化します。ハイパーパラメータのチューニングには、より多くの視覚化オプションが付属しています。
・「train.py」は、ワーカーの数、ワーカー1つあたりのCPUとGPU、およびアルゴリズムの特定の引数の様々なようにカスタマイズオプションでアルゴリズムを訓練することができます。訓練(およびチェックポイントに保存オプションを選択)後、「rollout.py」を使用すると、訓練済みのモデルをロードし、実行中のモデルのレンダリングを確認できます。
・「Ray」は、より一般的な機械学習の使用にも使用できます。「MNIST」や「CIFAR10」のような古典的なML問題のハイパーパラメータのチューニング方法の例もあります。
3. ハイパーパラメータのチューニング
「Ray」で最も興味深かったのは、ハイパーパラメータのチューニングです。この必要でありながら退屈で時間のかかるプロセスは、「Ray」を使用することではるかに簡単になります。ただし、チューニングアルゴリズムと引数を理解する必要があります。
私は「Bust A Move」と呼ばれるレトロジムゲームのハイパーパラメータを見つけるために、いくつかの簡単なハイパーパラメータのチューニングの実験を行いました。しかし残念なことに、良い結果を得るにはいくつかの問題があり、99のうちレベル8までしか到達できませんでした。
以下の作成したスクリプトは、他のRLの試みに役立つと思います。
4. Grid Search
Example scripts: Sonic, Bust A Move, MNIST
「Grid Search」では、テストするハイパーパラメータごとにすべてのオプションを個別のリストに設定します。実験を実行すると、これらのハイパーパラメータリストのすべての可能な組み合わせが実行されます。
私が見た講義(StanfordビジョンクラスとBerekely Deep RLクラス)や読んだもの(Deep Learning本など)から察するに、「Random Search」より劣ると思います。
「Grid Search」スクリプトを作成しましたが、実際には完全な実験を実行しませんでした。時間がかかりすぎたためです。
「Grid Search」は、理解と実装が簡単です。また、経験豊富なDeep RL講師とのQ&Aを見て、彼が使用するハイパーパラメータ検索について尋ねられたとき、彼は「Grid Search」と言いました。彼は、問題に対する直観を集め、結果をよりよく理解するのに役立つので、それを使うと言っていました。
5. Random Search
Example scripts: Bust A Move
基本的に、「Grid Search」のリストを、ハイパーパラメータで選択できる分布に置き換えます。
【例】[0.0,0.1、... 1.0] → random.uniform(0.0, 1.0)
「Random Search」は、多くの場合、「Hyperband」や「Population Based Training」(PBT)などのより高度なアルゴリズムと組み合わせて使用します。
今回は「Grid Search」よりも優先しました。ハイパーパラメータの範囲を最小値と最大値の設定は必要ですが、妥当な時間で実験を終了できるからです。「Grid Search」では、試してみたい600以上の組み合わせがありましたが、これには時間がかかりすぎていました。代わりに、「Random Search」の場合、実験の数と時間の予算を組んだ、各実験の長さを設定します。
6. Hyperband Tuning
Examples: the paper, MNIST, Bust A Move
一連の試行を実行し、結果に基づいて、パフォーマンスの低い試行を停止し、パフォーマンスの高い試行を続行することを決定します。著者は、アルゴリズムをマルチバンディット探索問題と比較しています。
ユーザーはアルゴリズムのハイパーパラメータをチューニングして、各試行に割り当てるリソースの量と、パフォーマンスの低い短時間の試行を積極的に削減する方法を決定します。
7. Population Based Training
Examples: blog, the paper, Humanoid (PPO)
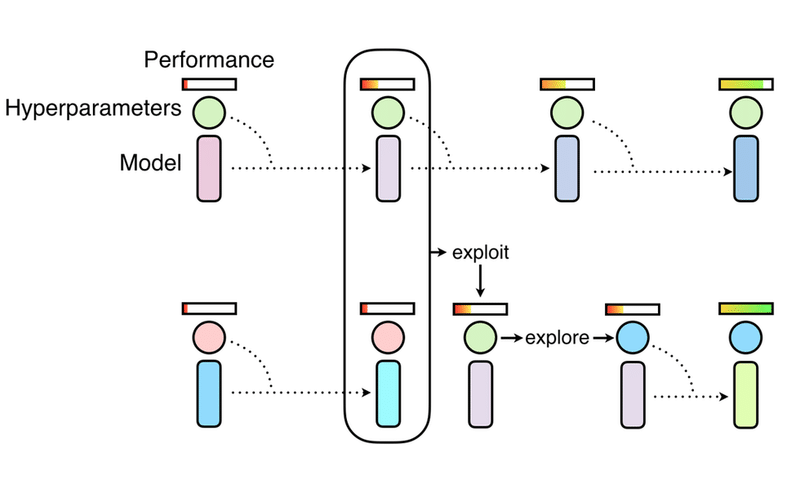
「Random Search」の並列訓練と厳選された最適化手法を組み合わせて、ハイパーパラメータおよびハイパーパラメータースケジュールを効率的に見つけます。訓練の進行に合わせてモデル間で結果を共有し、探索および活用手法を使用します。
この記事が気に入ったらサポートをしてみませんか?