
DQN & Double Q-Learning & Prioritized Replay & Dueling DQN : DQNな強化学習アルゴリズム

以下の記事が面白かったので、ざっくり訳してみました。
1. はじめに
私たちは、公開された結果と同等のパフォーマンスで強化学習アルゴリズムを再現するため、「OpenAI Baselines」をオープンソース化しています。今後数か月にわたってアルゴリズムをリリースします。本日のリリースには、「DQN」とその3つのバリアント(亜種)が含まれています。
2. OpenAI Baselines
強化学習の結果は再現するのが困難です。パフォーマンスは非常にノイズが多く、アルゴリズムには微妙なバグを許容する多くの可動部分があり、多くの論文では必要なトリックをすべて報告していません。
既知の適切な実装(およびそれらを作成するためのベストプラクティス)である「OpenAI Baselines」をリリースすることにより、明らかなRLの進歩が既存のアルゴリズムのバグのあるバージョンまたは未調整バージョンとの比較によるものではないことを保証したいと思います。
この投稿には、正しいRLアルゴリズムの実装に使用するいくつかのベストプラクティスと、最初のリリースの詳細が含まれています。
3. ベストプラクティス
(1) ランダム行動と比較して確認
以下のビデオ(本家のページ参照)では、エージェントがゲーム「H.E.R.O」でランダム行動を採っています。訓練の初期段階でこの動作を見た場合、エージェントが学習していると信じ込ませるのは非常に簡単です。したがって、エージェントのパフォーマンスがランダム行動よりも優れていることを常に確認する必要があります。
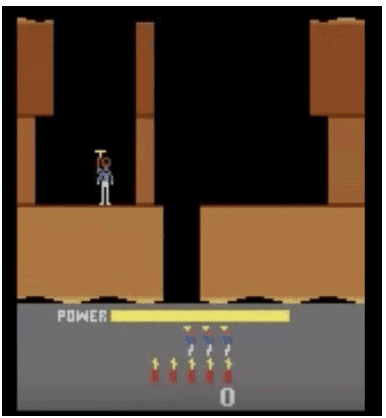
(2) 非破壊的なバグに注意
10個の一般的な強化学習アルゴリズムの再実装のサンプルを調べたところ、コミュニティメンバーや著者によって確認された微妙なバグがあることに気付きました。
勾配を無視した軽度のバグから、誤って因果たたみ込みを実装したものから、真の結果よりも高いスコアを報告した深刻なものまで、様々なバグがありました。
(3) エージェントが行動する世界を確認
ほとんどのディープラーニングアプローチと同様に、DQNの場合、環境の画像をグレースケールに変換して、訓練中に必要な計算を削減する傾向があります。これにより、独自のバグが発生する可能性があります。
SeaquestでDQNアルゴリズムを実行すると、実装のパフォーマンスが低下していることがわかりました。環境を調べたところ、この写真が示すように、後処理された画像に魚が含まれていなかったことが原因であることがわかりました。

スクリーン画像をグレースケールに変換するとき、緑色の値の係数を誤って較正していたため、魚が消えていました。バグに気付いた後、色の値を微調整し、アルゴリズムは魚を再び見ることができました。
将来このような問題をデバッグするために、Gymにはplay機能が含まれるようになりました。これにより、研究者はAIエージェントと同じ観察結果を簡単に確認できます。
(4) バグを修正してからハイパーパラメータを確認
デバッグ後、ハイパーパラメータの調整を開始しました。最終的に、探索速度を制御するハイパーパラメータであるεのアニーリングスケジュールを設定すると、パフォーマンスに大きな影響を与えることがわかりました。
最終的な実装では、εは最初の100万ステップで0.1に減少し、その後、次の2400万ステップで0.01に減少します。実装にバグが含まれていた場合、まだ診断されていない障害に対処するために、異なるハイパーパラメータ設定が考えられます。
(5) 論文の解釈の再確認
DQN Natureの論文では、著者は次のように書いています。
We also found it helpful to clip the error term from the update [...] to be between -1 and 1.
このステートメントの解釈は2つあります。「目的をクリップ」か、「勾配を計算するときに乗法項をクリップ」します。前者はより自然に見えますが、1つのDQN実装で見られるように、誤差が大きい遷移では勾配がゼロになり、パフォーマンスが最適化されなくなります。後者は正確であり、単純な数学的解釈があります。
予想どおりにグラデーションが表示されることを確認することで、このようなバグを見つけることができます。これは、「compensor_gradients」を使用してTensorFlow内で簡単に実行できます。
この投稿のバグの大半は、コードを何度も調べて、各行で何がうまくいかないかを考えることで発見されました。各バグは明らかなように見えますが、経験豊富な研究者でさえ、実装内のすべてのバグを見つけるのに必要な作業量を過小評価する傾向があります。
4. Deep Q-Learning
「Python 3」と「TensorFlow」を使用します。
このリリースには以下が含まれます。
◎ DQN
Q-Learningとディープニューラルネットワークを組み合わせて、ビデオゲームやロボット工学などの複雑な高次元環境でRLを機能させる強化学習アルゴリズムです。
◎ Double Q-Learning
特定の行動に関連付けられた価値を過大評価しないように、DQNアルゴリズムの傾向を修正しました。
◎ Prioritized Replay
本当の報酬が予想報酬と大きく異なる記憶を再生することを学習することにより、DQNのエクスペリエンスリプレイ機能を拡張し、エージェントが誤った仮定の展開に応じて自分自身を調整できるようにします。
◎ Dueling DQN
ニューラルネットワークを2つに分割します。1つはタイムステップごとに値の推定値を提供することを学習し、もう1つは各行動の潜在的な利点を計算し、2つを組み合わせて単一の行動アドバンテージQ関数にします。
開始するには、次を実行します。
$ pip install baselines
# モデルを訓練し、結果をcartpole_model.pklに保存
$ python -m baselines.deepq.experiments.train_cartpole
# cartpole_model.pklに保存されたモデルを読み込み、学習したポリシーを視覚化
$ python -m baselines.deepq.experiments.enjoy_cartpoleまた、訓練済みのエージェントも提供しています。
これは、次を実行することで取得できます。
$ python -m baselines.deepq.experiments.atari.download_model --blob model-atari-prior-duel-breakout-1 --model-dir /tmp/models
$ python -m baselines.deepq.experiments.atari.enjoy --model-dir /tmp/models/model-atari-prior-duel-breakout-1 --env Breakout --dueling
5. ベンチマーク
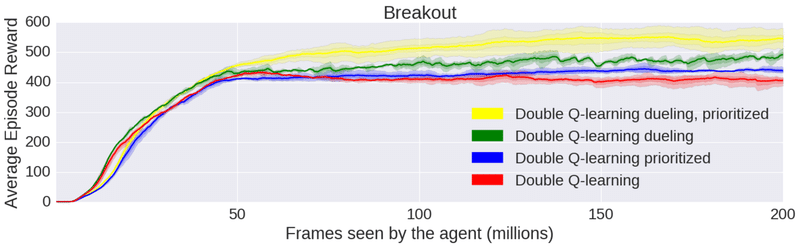
AtariゲームでのDQN実装のパフォーマンスを示すiPythonノートブックが含まれています。さまざまなアルゴリズムのパフォーマンスを比較できます。
・Dueling Double Q-LearningとPrioritized Replay(黄色)
・Double Q-LearningとPrioritized Replay(青)
・Dueling Double Q-Learning(緑)
・Double Q-Learning(赤)
AIは経験的な科学であり、より多くの実験を行う能力が進歩と直接相関します。Baselinesを使用すると、研究者は既存のアルゴリズムを実装する時間を短縮し、新しいアルゴリズムを設計する時間を増やすことができます。
https://www.amazon.co.jp/dp/4862464505?tag=note0e2a-22&linkCode=ogi&th=1&psc=1
この記事が気に入ったらサポートをしてみませんか?