
AutoRT ・ SARA-RT ・ RT-Trajectory の概要

以下の記事が面白かったので、かるくまとめました。
1. はじめに
ロボットに「家を片付けて」とか「健康的な食事を作って」といった簡単なリクエストをするだけで、それらの仕事が完了する未来を想像してみてください。 人間にとっては簡単なこれらのタスクは、ロボットにとって世界についての高度な理解を必要とします。
「AutoRT」「SARA-RT」「RT-Trajectory」は、Google DeepMindの「Robotics Transformers」に基づいて構築されており、ロボットがより迅速に意思決定を行い、環境をよりよく理解してナビゲートします。
2. AutoRT
「AutoRT」は、「LLM」(Large Language Model) や「VLM」(Visual Language Model) などの大規模な基盤モデルとロボット制御モデル (RT-1 または RT-2) を組み合わせて、学習データを収集できるシステムを作成します。「AutoRT」は、それぞれに「ビデオカメラ」と「エンドエフェクタ」を備えた複数のロボットを同時に指示して、さまざまな設定でさまざまなタスクを実行できます。 各ロボットについて、システムは「VLM」を使用してその環境と視界内のオブジェクトを理解します。次に、「LLM」は、「スナックをカウンタートップに置く」など、ロボットが実行できる創造的なタスクのリストを提案し、ロボットが実行する適切なタスクを選択する意思決定者の役割を果たします。
7か月にわたる広範な実世界での評価において、このシステムは、さまざまなオフィスビルで最大20台のロボット、合計で最大52台のユニークなロボットを同時に安全にオーケストレーションし、6,650 のユニークなタスクにわたる 77,000 件のロボットトライアルからなる多様なデータセットを収集しました。

(1) 自律走行型ロボットが複数の物体がある場所を見つける。
(2) VLMはシーンとオブジェクトをLLMに記述。
(3) LLMは、ロボットにさまざまな操作タスクを提案し、ロボットが支援なしで実行できるタスク、人間による遠隔制御が必要なタスク、不可能なタスクを選択する前に決定。
(4) 選択したタスクが試行され、経験データが収集され、データの多様性/新規性がスコア付けされる。
(1)〜(4)を繰り返す。
3. SARA-RT
「SARA-RT」(Self-Adaptive Robust Attention for Robotics Transformers) は、「Robotics Transformers」 (RT) をより効率的なバージョンに変換します。
RTニューラルネットワーク アーキテクチャは、最先端の「RT-2」を含む最新のロボット制御システムで使用されています。最良の「SARA-RT-2」モデルは、短い画像履歴が提供された後、「RT-2」よりも10.6%精度が高く、14%高速でした。
Transformerは強力ですが、意思決定を遅らせる計算上の要求によって制限される可能性があります。Transformerは二次複雑さのアテンションモジュールに大きく依存します。つまり、ロボットに追加のセンサーや高解像度のセンサーを与えるなどして、RTモデルの入力が 2 倍になると、その入力を処理するために必要な計算リソースが4倍に増加し、意思決定が遅くなる可能性があります。
「SARA-RT」は、「up-training」と呼ばれる新しいモデルファインチューニング方法を使用して、モデルをより効率的にします。 「up-training」は二次計算量を単なる線形計算量に変換し、計算要件を大幅に削減します。この変換により、元のモデルの速度が向上するだけでなく、その品質も維持されます。

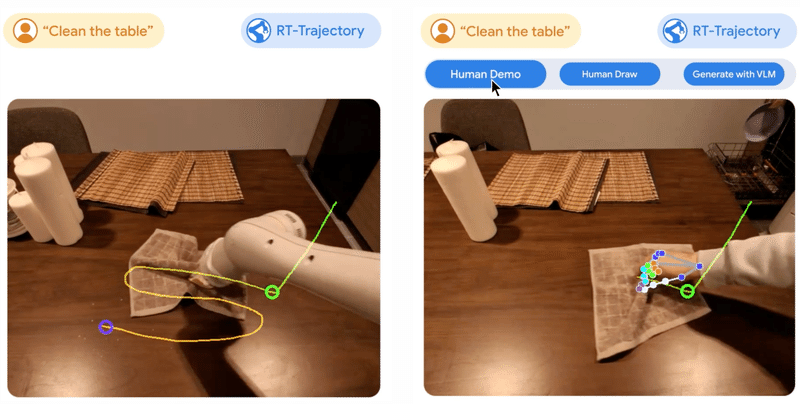
4. RT-Trajectory
「RT-Trajectory」は、学習ビデオにロボットの動きを説明する視覚的なアウトラインを追加するモデルです。学習データセット内の各ビデオを取得し、タスクを実行するロボットアームのグリッパーの 2D 軌道スケッチをオーバーレイします。これらの軌跡は、RGB イメージの形式で、モデルがロボット制御ポリシーを学習する際に、低レベルで実用的な視覚的なヒントを提供します。
学習データには見られない41のタスクでテストしたところ、「RT-Trajectory」 によって制御されたアームは既存の最先端の「RTモデル」のパフォーマンスを2倍以上に向上させました。タスクの成功率は 63% でした。
従来、ロボット アームの学習は、抽象的な自然言語 (「テーブルを拭く」) を特定の動作 (グリッパーを閉じる、左に移動、右に移動) にマッピングすることに依存しており、モデルを新しいタスクに一般化することが困難でした。 対照的に、「RT-Trajectory」を使用すると、動画やスケッチに含まれるような特定のロボットの動きを解釈することで、「RTモデル」がタスクの「やり方」を理解できるようになります。
関連
この記事が気に入ったらサポートをしてみませんか?