
データ駆動型ロボティクスのためのフレームワーク

以下の記事が面白かったので、ざっくり訳してみました。
・A Framework for Data-Driven Robotics
1. はじめに
『大規模な機械学習』は、過去10年間で人工知能の最大の成果の1つです。
成功するためのレシピには、通常次のな要素が含まれています。
・大規模でディープなネットワーク
・大規模でキュレーションされたデータセット
・大量の計算能力
これらにより、「画像理解」「音声認識」、そして囲碁、Dota、StarCraftなどの「ゲームプレイ」など多くの分野でパフォーマンスが大きく飛躍しました。このシンプルでありながら革新的なレシピを、『ロボット工学』にどのようにもたらすことができるでしょうか?
多くの課題が残っていますが、この研究は次に進むための最初のステップになります。
【動画】A Framework for Data-Driven Robotics

これは、強化学習を使用したロボット操作を行うための、実践的なシステムフレームワークの提案です。人間のデモおよびロボットの行動は全てストレージに蓄積し、そのデータを使って報酬曲線(動画に対する報酬遷移のアノテーション)を作成し、そこから学習するという形態を採ります。この研究では、ピクセルからの真相強化学習によるロボット操作に焦点を当てます。

ディープRLはロボット工学のコンテキストでは困難です。「多くのデータ」と「正確な報酬信号」が必要だからです。
私たちのフレームワークはこれらの問題に対処します。

中心的なアイディアは、新しいタスクを学ぶ時に「履修データ」を保存して再利用することです。2番目の重要な機能は、効率的な人間のアノテーションを通じて「報酬関数」を学習することです。数100時間の「履修データ」と学習した「報酬関数」を組み合わせることで、「バッチRL」の力を活用できます。

私たちのフレームワークは、以下に示すステップで構成されています。
ここで、ロボットにブロックを積み重ねるように教えたいとします。

ステップ1では、ディープRLのデータを収集するために、1つのロボットが実行する全てを記録します。ブロックの持ち上げ、並び替え、移動、ランダムポリシー、さらには失敗した実験まで全てです。
このオフタスクデータはすべて、最終的なパフォーマンスに不可欠になります。最初に望ましい動作を実証するために、人間がロボットを遠隔操作します。

ステップ2では、報酬アノテーションをタスクに付加します。保存した履修データから、いくつかの成功した軌道と、いくつかの他の例を取り出します。そして、アノテータ(人間)が報酬のスケッチを描画して、タスクの進行状況を示します。

ステップ3では、アノテーションを付加したデータを使用して、報酬モデルを学習します。そして、このモデルを適用して、すべての履修データにアノテーションを付加します。

ステップ4・5では、数百時間のビデオとアノテーションを使用して、完全にオフラインのプロセスである「バッチRL」を実行します。「バッチRL」を選択することで、実際のロボットを使わずにポリシーを訓練できます。さまざまな履修データは、オフポリシートレーニングで優れたパフォーマンスを得るために不可欠です。
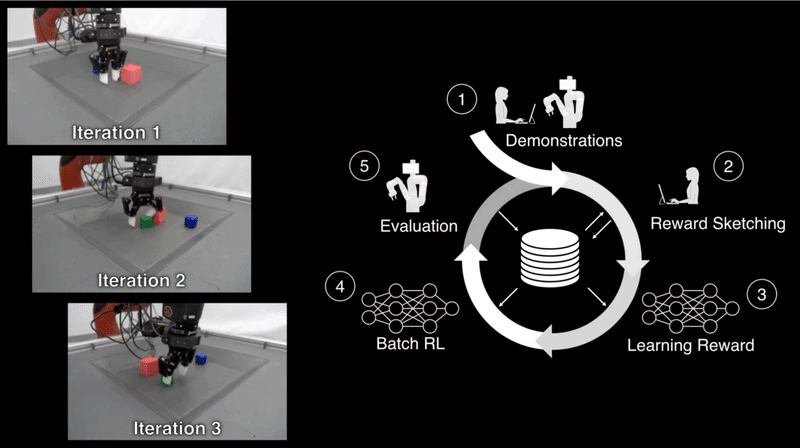
すべての手順を完了しても、最初のポリシーはあまり良くないかもしれません。そんな時は、このプロセスを再度繰り返し、より多くのエピソードと報酬のアノテーションを収集します。反復ごとに、ポリシーのパフォーマンスと堅牢性が向上します。

ロボットは人間の妨害にも関わらず、目標を達成しました。
そして、ディープRLの汎化性能。新しいオブジェクトに対処し、ミスから回復し、未知の初期状態で開始できるようにします。

エージェントは、訓練中中に観察した人間のデモンストレーションよりも高速である必要があります。

このフレームワークは非常に汎化性能が高く、他のタスクも解決できます。
パイプラインを再度実行すると、ロボットは、特徴/報酬エンジニアリングなしで、見えない変形可能なオブジェクトを持ち上げることができます。
2. データ駆動型ロボティクスのためのフレームワーク
スクリプト化されたポリシーと人間の遠隔操作から始めて、ロボットエクスペリエンスのデータセットを構築します。特定のタスクを解決するために、人間の好みを収集する新しい手法である「報酬スケッチ」を使用して、対応する「報酬関数」を学習します。「報酬関数」を「NeverEndingストレージ」全体に適用して、すべてのデータに自動的にラベルを付けします。結果のラベル付きデータセットは、ロボットから追加のデータを必要とせずに、ピクセルからエンドツーエンドで制御ポリシーを学習できます。
つまり、試行錯誤の学習はロボットの「心」で行われるため、現実世界で行動するロボットを作ることから解放されます。ロボットが解決するタスクが多いほど、収集するデータが多くなり、新しいスキルを学習するときにすべてが有用になります。

私たちのデータ駆動型ロボティクスのためのフレームワークは、次のポリシーをもたらします。
(1)人間よりも高速。
(2)敵対的干渉に対して堅牢。
(3)変形可能を含む多様なオブジェクトに汎化可能。
3. 報酬スケッチ
「報酬スケッチ」インタフェースはシンプルで効率的です。
以下で、自分で試すことができます。
これはスクショなので本家のページで試してください。

上の領域では、ロボットのパフォーマンスのビデオを表示します。
中央の領域は、報酬をスケッチします。マウスでドラッグで、ロボットの評価を書き込みます。上の方が報酬が高く、緑色部分は、タスク(緑ブロックを赤ブロックに積み重ねる)が完了したことを示します。
下の領域は、訓練中の報酬モデルの報酬予測を表示します。
4. 【実験】緑ブロックを赤ブロックに積み重ねる
◎妨害への対処
このビデオでは、人間のオペレーターがロボットがタスクを達成できないように妨害しています。ロボットは、そのようにミッションを妨害しようとするのを見たことはありません。それでも、忍耐力で、任意のタスクを解決します。
◎オブジェクトの種類を増やす
このビデオでは、ロボットが各エピソードで新しいオブジェクトを積みます。オブジェクトには、訓練データセットではめったに見られない多様な形状と外観があります。それでも、ロボットは新しい試行ごとに成功しています。
◎布を積み重ねる
エージェントも報酬も明示的なオブジェクト追跡を必要としないため、同じフレームワーク内で変形可能なオブジェクト(布など)を等しく効率的に学習できます。
5. 【実験】USBの挿入
論文の付録に記載したように、私たちは、「人間のデモンストレーション」から「エージェント」と「報酬関数」を同時に訓練しました。まっさらな状態から、1日以内に、ピクセル入力のみで、USBの挿入を覚えました。
ポリシーは視覚のみであり、行動は手首フレームで定義されるため、訓練中に使用されない位置の変化に対して堅牢です。
この記事が気に入ったらサポートをしてみませんか?