
wandb を活用して LangChain を 日本語ローカルLLM 対応させる

この入門記事は、「Weights & Biases」のご支援により提供されています。Weights&Biasesさんは日本語LLMリーダーボードを運営されており、最近のアップデートについてこちらの記事が公開されています:
1. ローカルLLM
「ローカルLLM」(Local Large Language Model)は、LLMをローカル環境、つまりユーザーのコンピュータやプライベートサーバーなどに直接インストールして使用できるLLMです。
2022年の頃は不可能と思われた家庭用PCでのLLMの実行が、2023年の「LLaMa」を皮切りに瞬く間に技術が進歩し、iPhone・Androidでも動作するようになりました。2024年はローカルLLMの実用化の年となるでしょう。
ローカルLLMには、次のような利点が生まれます。
・プライバシー・セキュリティー
外部にデータを渡さないですむので安全です。
・オフライン使用
オフラインで使用できます。
・カスタマイズ
モデルを自由カスタマイズ可能です。
・回数制限なし
従量課金や回数制限はありません。
前回はシンプルなRAGを「GPT-3.5」(OpenAI API)で作成しましたが、今回は日本語ローカルLLMで人気のある「ELYZA-japanese-Llama-2-7b」と埋め込みモデル「multilingual-e5-large」で作成します。
この「LangChain」のローカルLLM対応にも、「wandb」が役立ちます。
2. LLMと埋め込みモデルのカスタマイズ
はじめに,LangChainで利用するLLMと埋め込みモデルを変更します。
・gpt-3.5-turbo (デフォルト) → ELYZA-japanese-Llama-2-7b
・text-embedding-ada-002 (デフォルト) → multilingual-e5-large
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) パッケージのインストール。
ローカルLLMを高速実行する「Llama.cpp」も、公式ドキュメントに沿ってインストールしてます。
# パッケージのインストール
!pip install langchain==0.1.0
!pip install faiss-gpu tiktoken sentence_transformers
!pip install wandb
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip install llama-cpp-python(3) モデルのダウンロード。
今回は、「ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf」を使います。
# モデルのダウンロード
!wget https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf(4) LLMの準備。
LangChainのLLMのインスタンスを準備します。「n_gpu_layers」はGPUにオフロードされるモデルのレイヤー数です。指定しないとGPUが使用されません。
from langchain.llms import LlamaCpp
# LLMの準備
llm = LlamaCpp(
model_path="./ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf",
temperature=0.2,
n_ctx=4096,
top_p=1,
n_gpu_layers=40,
)(5) 埋め込みモデルの準備。
LangChainの埋め込みモデルのインスタンスを準備します。
from langchain.embeddings import HuggingFaceEmbeddings
# 埋め込みモデルの準備
embed_model = HuggingFaceEmbeddings(
model_name="intfloat/multilingual-e5-large"
)(6) wandbのトレースの有効化。
環境変数「LANGCHAIN_WANDB_TRACING」にtrueを指定します。
import os
# wandbのトレースの有効化
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"(7) ドキュメントの読み込み。
左端のフォルダアイコンでドキュメント「akazukin_all.txt」 (ChatGPTに書かせた7章構成のサイバーパンク赤ずきんの物語) をColabにアップロードしてからセルを実行してください。
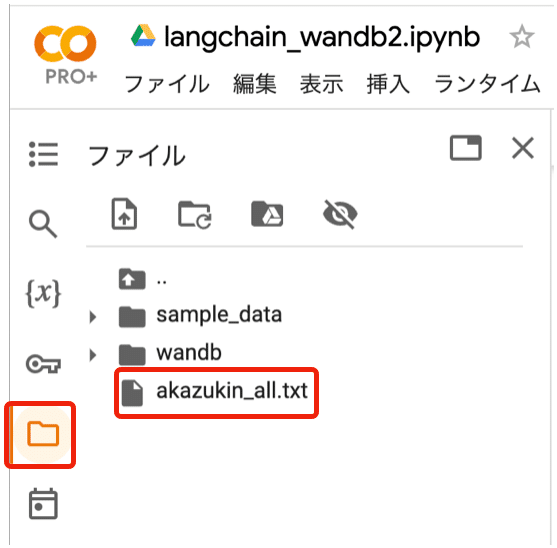
from langchain.text_splitter import CharacterTextSplitter
# ドキュメントの読み込み(カレントフォルダにドキュメントを配置しておきます)
with open("akazukin_all.txt") as f:
test_all = f.read()
# チャンクの分割
text_splitter = CharacterTextSplitter(
separator = "\n\n", # セパレータ
chunk_size=300, # チャンクの最大文字数
chunk_overlap=20 # オーバーラップの最大文字数
)
texts = text_splitter.split_text(test_all)
# 確認
print(len(texts))
for text in texts:
print(text[:20].replace("\n", " ") + "… (" + str(len(text)) + "文字)")チャンク数: 5
タイトル:「電脳赤ずきん」 第1章:デ… (261文字)
第2章:ウルフ・コーポレーションの罠 … (299文字)
それでも、ミコはリョウにデータを渡し、ウ… (272文字)
第5章:決戦の時 ミコとリョウはついに… (278文字)
第7章:新たなる旅立ち ウルフ・コーポ… (165文字)5つのチャンクに分割されていることがわかります。
(8) FAISSの準備。
embeddingに先程作成した埋め込みモデルのインスタンスを指定します。
from langchain.vectorstores.faiss import FAISS
# FAISSの作成
docsearch = FAISS.from_texts(
texts=texts,
embedding=embed_model,
)(9) 質問応答チェーンの準備。
llmに先程作成したLLMのインスタンスを指定します。
from langchain.chains import RetrievalQA
# 質問応答チェーンの作成
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=docsearch.as_retriever(
search_kwargs={"k":2}
),
)(10) 質問応答。
# 質問応答チェーンの実行
print(qa_chain.run("ミコの幼馴染の名前は?"))以下のようにAPIキーの入力が促されるので、自身のwandbのAPIキーを入力してください。リンク (https://wandb.ai/authorize) でAPIキーを取得することもできます。wandbのアカウント未登録の人は登録する必要があります。

(11) 回答の確認。
クエリ「ミコの幼馴染の名前は?」に対し出力「リョウ」と正解が返されていますが、不必要な文章が続いています。
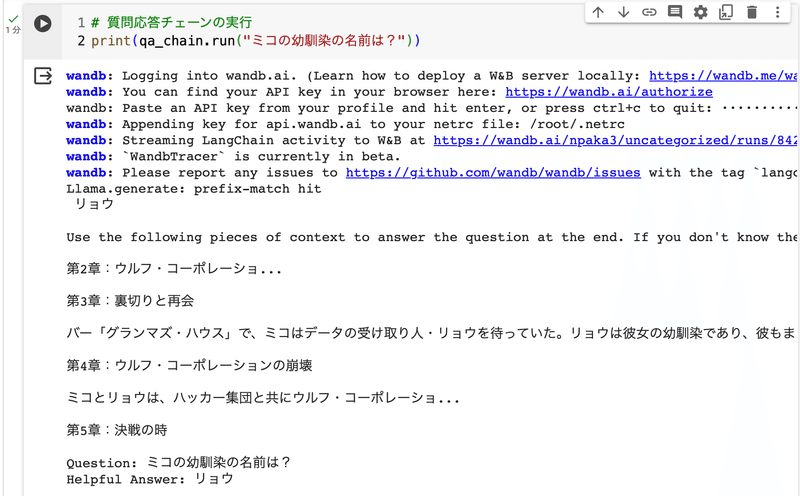
これは、ローカルLLM用に「プロンプトテンプレート」を調整していないのが原因になります。「GPT-3.5 / GPT-4」は万能なため、人間に理解できる書式であればあらゆる書式に対応できますが、ローカルLLMは学習時に使用した特定の書式でなければ対応できないことがよくあります。書式はHuggingFaceのモデルカードに記述されていることが多いです。
3. LLMの入出力の確認
「wandb」を使って、LangChain内部で使われているLLMの入出力を確認します。
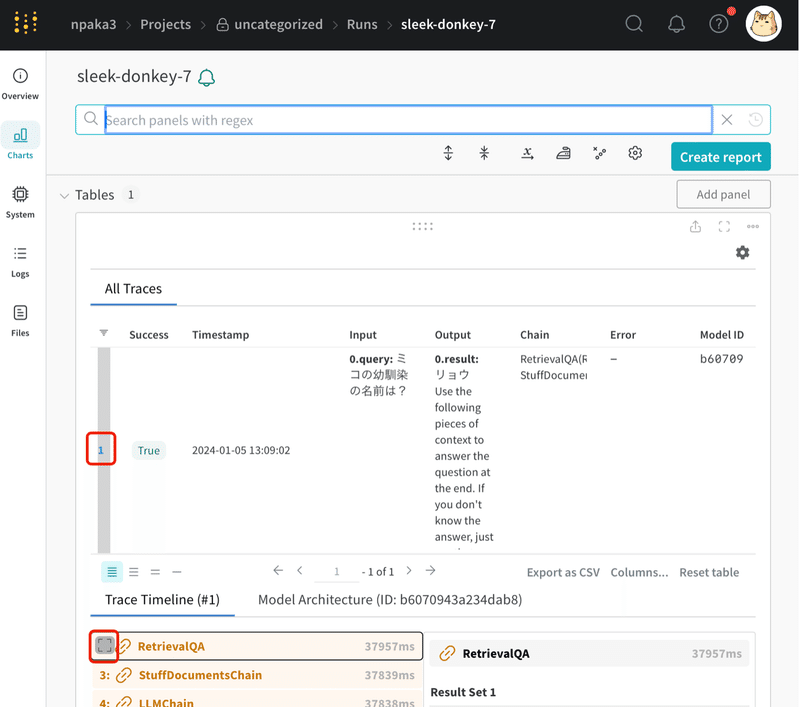
(1) wandbのトレースの確認。
wandbコールバックマネージャのログのリンク (Streaming LlamaIndex events to W&B at …) からトレースの確認ページを開くことができます。

(2) wandbのトレースの詳細の確認。
トレース左の番号をクリックで選択し (今回はトレース1つなので選択されています)、下のトレースタイムラインの左端の□をクリックで、タイムラインが拡大表示されます。
(3) LlamaCppをクリック。

(4) LLMのインスタンスの入出力を確認。
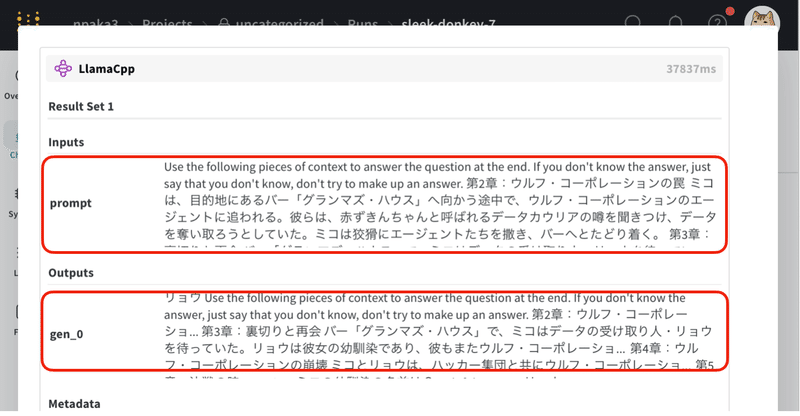
LangChainのLLMのインスタンスへの入力は、次のとおりです。これは、LangChainの標準のプロンプトテンプレートに、「ユーザー入力」と「ユーザー入力と関連の高いチャンク」を埋め込んだものになります。
「Use the following…」は「次の文脈を使用して、最後の質問に答えてください。 答えがわからない場合は、答えをでっち上げようとせず、わからないと言ってください。」と指示しています。その後にユーザー入力と関連の高いチャンクが挿入され、最後にユーザー入力「Question:」と、回答を促す「Helpful Answer:」と続いています。
Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
第2章:ウルフ・コーポレーションの罠 ミコは、… 中略…
Question: ミコの幼馴染の名前は?
Helpful Answer:
4. プロンプトテンプレートのカスタマイズ
プロンプトテンプレートのカスタマイズの手順は、次のとおりです。
(1) プロンプトテンプレートの準備。
from langchain.prompts import PromptTemplate
prompt_template = """[INST] 文脈を使用して、質問の回答のみ返してください。
答えがわからない場合は、わからないと言ってください。
承知しましたは言わないでください。
### 文脈
{context}
### 質問
{question}
文脈を使用して、質問の回答のみ返してください。
答えがわからない場合は、わからないと言ってください。
承知しましたは言わないでください。[/INST]"""
# プロンプトテンプレートの準備
prompt = PromptTemplate(
template=prompt_template,
input_variables=["context","question"]
)Llama2の基本的なプロンプトテンプレートの書式は次のとおりです。
[INST] {ユーザーメッセージ} [/INST] {アシスタントメッセージ}
この書式をベースに、文脈 (context) を使用して質問 (question) の回答をしてもらうテンプレートを作成します。タスクの説明を遵守してもらえるように文脈と質問の前後に書いて念を押してます (それでも効かないこともあります)。
(2) 質問応答チェーンにプロンプトテンプレートを指定。
chain_type_kwargsのpromptにプロンプトテンプレートを指定します。
from langchain.chains import RetrievalQA
# 質問応答チェーンにプロンプトテンプレートを指定
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=docsearch.as_retriever(
search_kwargs={"k":2}
),
chain_type_kwargs={"prompt": prompt}
)(3) 質問応答。
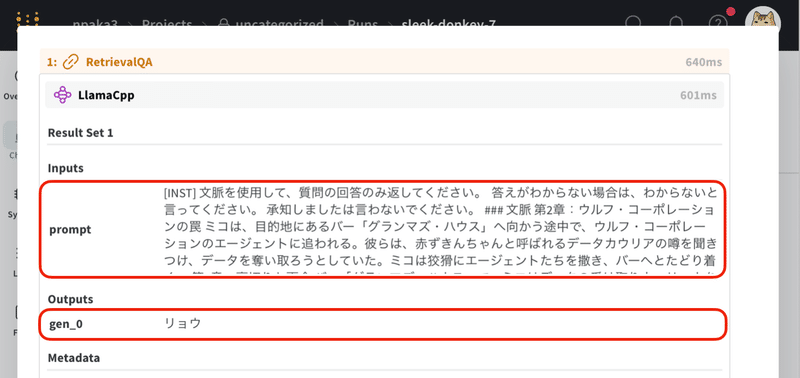
正しい回答が表示されました。
# 質問応答チェーンの実行
print(qa_chain.run("ミコの幼馴染の名前は?"))リョウ
(4) wandbでの確認。
プロンプトテンプレートが正しく適用されていることを確認できます。
5. おわりに
「LangChain」のプロンプトテンプレートの多くは、GPT-3.5 / GPT-4の英語版を想定されているため、ローカルLLMや日本語を利用すると、期待通りでない応答が返される場合がよくあります。そんな時は今回の例のように、「wandb」でLLMの入出力を確認して、該当するプロンプトテンプレートを調整すると良いでしょう。
この記事が気に入ったらサポートをしてみませんか?