Acme - DeepMindの強化学習アルゴリズムの分散フレームワーク

以下の記事を参考に書いてます。
・DeepMind releases Acme, a distributed framework for reinforcement learning algorithm development
1. はじめに
6月はじめ、DeepMind は、強化学習アルゴリズムの開発を容易にするフレームワーク「Acme」をリリースしました。これを使用することで、以前のアプローチよりも「並列化」に優れた強化学習エージェントを作成できます。
強化学習には、環境と相互作用して学習データを生成するエージェントが含まれており、これによって、ビデオゲーム、ロボット、自動運転などの分野で画期的な成果をもたらしています。
この成果の要因のひとつとして、使用される学習データ量の増加 が挙げられます。そのため、すばやく大量の学習データを生成できる強化学習システムの設計が求められています。強化学習システムを単一プロセスから分散システムにスケーリングする場合、エージェントの再実装が必要になることがほとんどです。そこで、「Acme」の出番です。
「Acme」は、さまざまなレベルでエージェントを構築するためのコンポーネントを使用して、「複雑さ」と「スケール」の両方の問題に対処します。
これにより、訓練グループ、ロギング、チェックポイントを介して、アイデアの迅速な反復と本番環境での評価が可能になります。
「Acme」内では、Actorは環境と相互作用し、観察を行い、行動を実行します。行動結果を観察した後、Actorは状態を更新する機会が与えられます。これは多くの場合、環境に応じて実行する「行動」を決定する「行動選択ポリシー」に関連しています。エージェントは、ActorとLearnerのコンポーネントで構成され、状態の更新は、学習コンポーネント内のいくつかのステップによってトリガーされます。とはいえ、エージェントの大部分は、行動の選択を独自の行動コンポーネントに委ねています。
「Acme」は、DeepMindがリリースした「Reverb」と呼ばれる「低レベルのストレージシステム」によるDatasetモジュールを提供します。ActorとLearnerのコンポーネントの間にあります。さらに、「Acme」は「Reverb」に挿入する共通インターフェイスを確立し、さまざまなスタイルの前処理と継続的な観測データの集計を可能にします。
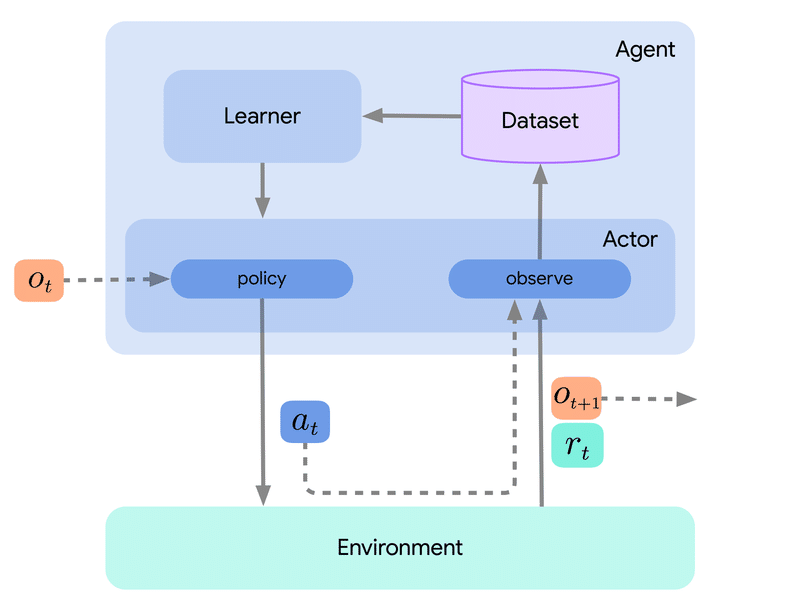
Actor、Learner、Storageコンポーネントは「Acme」内の異なるスレッドまたはプロセスに分割されます。これにより、環境の相互作用が学習プロセスと非同期に発生し、学習データ生成が加速します。
それ以外の場合、Acmeのレート制限により、学習から動作までの望ましいレートを適用でき、プロセスが定義された許容範囲内にある限り、ブロックされずに実行できます。たとえば、ネットワークの問題や不十分なリソースのために、プロセスの1つが他のプロセスに遅れをとった場合、レートリミッターは、他のプロセスが追いつく間の遅れをブロックします。
これらのツールとリソースに加えて、「Acme」には 強化学習アルゴリズムの参照実装 となる一連のサンプルが付属しています。DeepMindは、今後さらに多くの参照実装が利用可能になる可能性があると述べています。
この記事が気に入ったらサポートをしてみませんか?