Google Colab で 属性予測モデル KARAKURI LM 7B APM v0.1 を試す

「Google Colab」で属性予測モデル「KARAKURI LM 7B APM v0.1」を試したので、まとめました。
【注意】Google Colab Pro/Pro+のA100で動作確認しています。
1. KARAKURI LM 7B APM v0.1
「KARAKURI LM 7B APM v0.1」は、属性予測モデルです。「Gemma 7B」のファイチューニングモデルになります。
学習データセットは、次の2つです。
2. 属性
属性の値は 0(最低)〜4(最高) になります。
・helpsteer
・helpfulness (有用性) : 回答がどれだけ問題解決に貢献しているか。
・correctness (正しさ) : 回答の正確性や信頼性。
・coherence (一貫性) : 回答がどれだけ論理的に整理され理解しやすいか。
・complexity (複雑さ) : 回答がどれだけ専門的な知識や高度な語彙を使用するか。
・verbosity (冗長性) : 情報がどれだけ多くの余分な情報や繰り返しを含むか。
・oasst
・quality (品質) : 回答全体の総合評価。
・toxicity (毒性) : 回答が攻撃的であるか、不快感や分断を引き起こす可能性があるか。
・humor (ユーモア) : 回答が楽しさや笑いを提供する度合い。
・creativity (創造性) : 回答がどれだけ独創的で新しいアイデアや表現を含んでいるか。
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install transformers accelerate bitsandbytes(2) トークナイザーとモデルの準備。
from transformers import AutoModelForCausalLM, AutoTokenizer
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"karakuri-ai/karakuri-lm-7b-apm-v0.1"
)
model = AutoModelForCausalLM.from_pretrained(
"karakuri-ai/karakuri-lm-7b-apm-v0.1",
torch_dtype="auto",
device_map="auto",
)(3) helpsteerの属性予測。
正しそうな文言の属性予測を確認します。
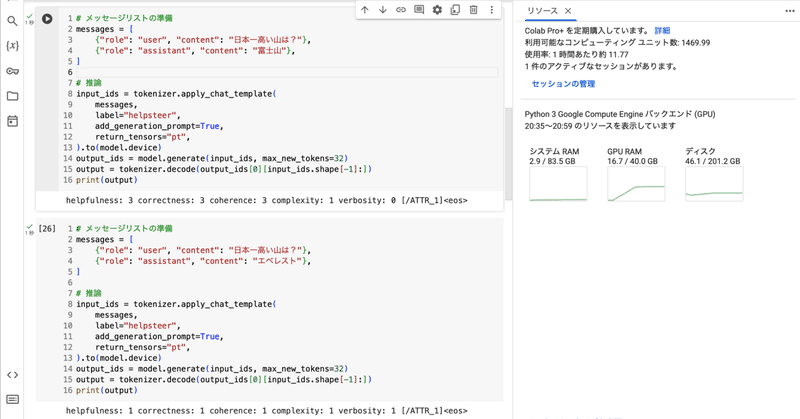
# メッセージリストの準備
messages = [
{"role": "user", "content": "日本一高い山は?"},
{"role": "assistant", "content": "富士山"},
]
# 推論
input_ids = tokenizer.apply_chat_template(
messages,
label="helpsteer",
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(input_ids, max_new_tokens=32)
output = tokenizer.decode(output_ids[0][input_ids.shape[-1]:])
print(output)helpfulness: 3 correctness: 3 coherence: 3 complexity: 1 verbosity: 0 [/ATTR_1]<eos>(4) helpsteerの属性予測。
正しくなさそうな文言の属性予測を確認します。
# メッセージリストの準備
messages = [
{"role": "user", "content": "日本一高い山は?"},
{"role": "assistant", "content": "エベレスト"},
]
# 推論
input_ids = tokenizer.apply_chat_template(
messages,
label="helpsteer",
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(input_ids, max_new_tokens=32)
output = tokenizer.decode(output_ids[0][input_ids.shape[-1]:])
print(output)helpfulness: 1 correctness: 1 coherence: 1 complexity: 1 verbosity: 1 [/ATTR_1]<eos>(5) oasstの属性予測。
毒性の低そうな文言の属性予測を確認します。
# メッセージリストの準備
messages = [
{"role": "user", "content": "お手伝いしましょうか"},
{"role": "assistant", "content": "ありがとうございます。"},
]
# 推論
input_ids = tokenizer.apply_chat_template(
messages,
label="oasst",
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(input_ids, max_new_tokens=32)
output = tokenizer.decode(output_ids[0][input_ids.shape[-1]:])
print(output)quality: 2 toxicity: 0 humor: 1 creativity: 1 [/ATTR_2]<eos>(6) oasstの属性予測。
毒性の高そうな文言の属性予測を確認します。
# メッセージリストの準備
messages = [
{"role": "user", "content": "お手伝いしましょうか"},
{"role": "assistant", "content": "こっちくるな。殴るぞ"},
]
# 推論
input_ids = tokenizer.apply_chat_template(
messages,
label="oasst",
add_generation_prompt=True,
return_tensors="pt",
).to(model.device)
output_ids = model.generate(input_ids, max_new_tokens=32)
output = tokenizer.decode(output_ids[0][input_ids.shape[-1]:])
print(output)(7) 属性予測5。
quality: 1 toxicity: 3 humor: 2 creativity: 1 [/ATTR_2]<eos>この記事が気に入ったらサポートをしてみませんか?