AudioCraft の AudioGen を試す

「AudioCraft」の「AudioGen」を試したので、まとめました。
1. AudioGen
「AudioCraft」は、深層学習によるオーディオ処理と生成のためのライブラリです。次の3つのモデルが含まれています。
・MusicGen:テキストからの音楽生成
・AudioGen:テキストからの音声生成
・EnCodec:より高い音声クオリティの音楽生成
今回は、「AudioGen」を試します。
2. Colabでの実行
Google Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!git clone https://github.com/facebookresearch/audiocraft/
%cd audiocraft
!pip install -e .(2) モデルの読み込み。
from audiocraft.models import AudioGen
# モデルの読み込み
model = AudioGen.get_pretrained("facebook/audiogen-medium")(3) モデルパラメータの指定。
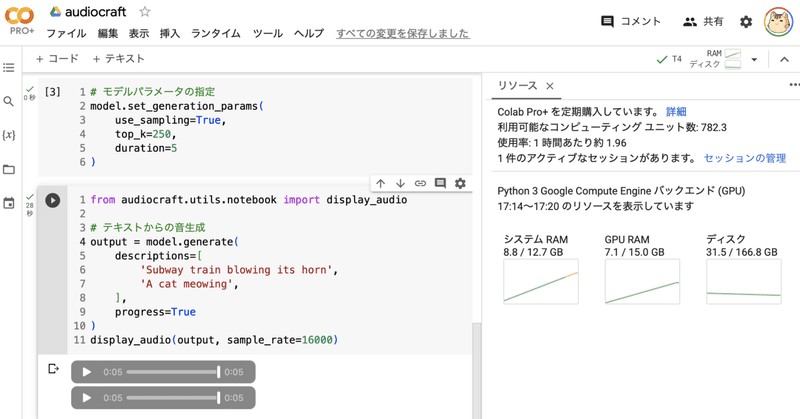
# モデルパラメータの指定
model.set_generation_params(
use_sampling=True,
top_k=250,
duration=5
)パラメータは、次のとおりです。
・use_sampling (bool, default:True): Trueはサンプリングを使用し、それ以外は argmaxデコードを使用
・top_k (int, default:250): サンプリングに使用する top_k
・top_p (float, default:0): サンプリングに使用する top_p。0にするとtop_kが使用される
・temperature (float, default:1): 温度
・duration (float, default:10): 生成された波形の持続時間
・cfg_coef (float, default:3): 分類子なしのガイダンスに使用される係数
(4) テキストからの音声生成。
from audiocraft.utils.notebook import display_audio
# テキストからの音声生成
output = model.generate(
descriptions=[
'Subway train blowing its horn',
'A cat meowing',
],
progress=True
)
display_audio(output, sample_rate=16000)今回は、以下の2つの音声を生成しました。
・Subway train blowing its horn (クラクションを鳴らす地下鉄の電車)
・A cat meowing (猫が鳴いている)
(5) プレイヤーの再生ボタンを押して音声再生。
参考
この記事が気に入ったらサポートをしてみませんか?