
HuggingFaceのオープンソースなテキスト生成モデルとLLMエコシステム

以下の記事が面白かったので、軽くまとめました。
・HuggingFace Blog - Open-Source Text Generation & LLM Ecosystem at Hugging Face
1. テキスト生成モデル
「テキスト生成モデル」は基本的に、不完全なテキストを完成させる、または、指示や質問の応答を生成する目的で学習されています。
1-1. CLM (Causal Language Model)
不完全なテキストを完成させるモデルは「CLM」 (Causal Language Model)と呼ばれ、主な例はOpenAIの「GPT-3」とMetaの「LLaMA」です。
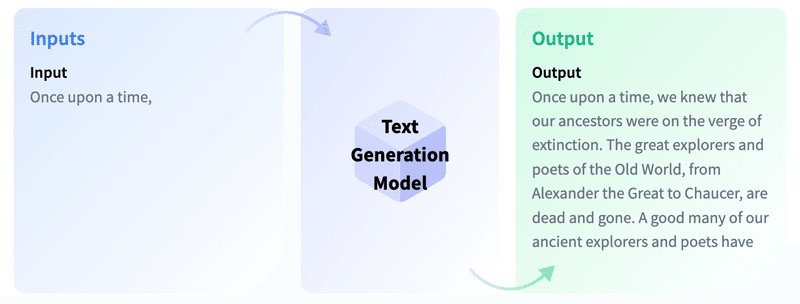
・Input : むかしむかし、
・Output : むかしむかし、私たちの祖先は絶滅の危機に瀕していた。…
「ファインチューニング」は、ベースモデルに含まれる知識を、下流のタスクのユースケースに転送するプロセスです。ファインチューニングで学習した指示で、よりよく一般化することができます。
「CLM」は、「RLHF」(Reinforcement Learning from Human Feedback) を使用して適応されます。この最適化は、テキストがどれほど自然で一貫性があるかをめぐって行われます。「RLHF」の仕組みについては、この記事を参照してください。
「GPT-3」はCLMのベースモデルですが、「ChatGPT」のモデルは、会話や指示のプロンプトで「RLHF」を介してファインチューニングされています。これらのモデルの違いは重要です。
「HuggingFace Hub」では、CLMの「ベースモデル」と「ファインチューニングモデル」の両方を見つけることができます。「LLaMA」は、クローズドソースのLLMに迫る性能を示した最初のオープンソースLLMです。Togetherは「RedPajama」と呼ばれるLLaMAのデータセットの複製を作成し、LLMを学習し、その上でファインチューニングしました。現在、オープンソースライセンスを持つ最大のCLMの3つは、MosaicMLの「MPT-30B」、Salesforceの「XGen」、TII UAEの「Falcon」です。
1-2. Text-to-Text
2番目のタイプの「テキスト生成モデル」は、「Text-to-Text」と呼ばれ、主な例は「T5」と「BART」(現時点では最先端ではありません) です。これらのモデルは、「質問と回答」、または「指示と回答」のテキストペアで学習しています。
Googleは最近、「FLAN-T5」のモデルをリリースしました。「FLAN」は指示チューニングのために開発された最近の技術であり、「FLAN-T5」は基本的に「FLAN」を使用してT5ファインチューニングしています。現時点では、「FLAN-T5」のモデルは最先端のオープンソースで、「Hugging Face Hub」で入手できます。
これらは、入出力形式は似ているように見えるかもしれませんが、指示チューニングされた「CLM」とは異なることに注意してください。以下では、これらのモデルがどのように機能するかのイラストを見ることができます。
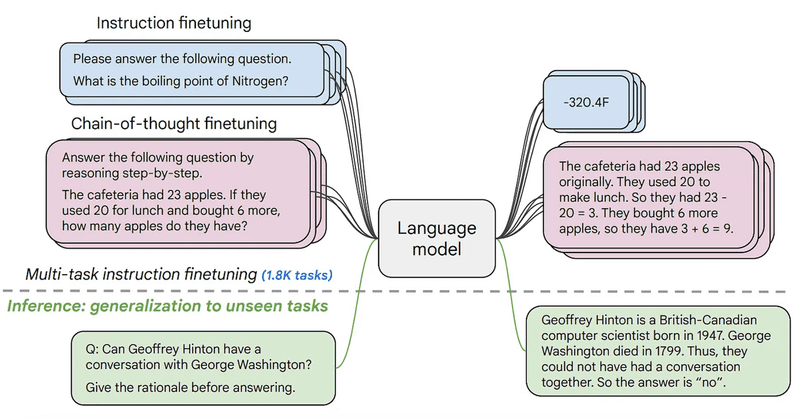
・Instruction ファインチューニング
・Input : 次の質問に答えてください。窒素の沸点は何度ですか?
・Output : -320.4F
・Chain-of-thought ファインチューニング
・Input : 段階的に推論して次の質問に答えてください。
食堂にはリンゴが23個ありました。
昼食に 20 個使用し、さらに 6 個購入した場合。
彼らはリンゴを何個持っていますか?
・Output : カフェテリアにはもともと23個のリンゴがありました。
彼らは昼食を作るのに20個を使いました。
したがって、23 - 20 = 3 となります。
彼らはさらに 6 個のリンゴを買ったので、3 + 6 = 9 になります。
・推論 : タスクへの一般化
・Input : Q: ジェフリー・ヒントンはジョージ・ワシントンと会話できますか?
答える前に根拠を述べなさい。
・Output : ジェフリー・ヒントンは、1947 年生まれのイギリス系カナダ人のコンピューター科学者です。
ジョージ・ワシントンは 1799 年に亡くなりました。
したがって、彼らは一緒に会話をすることができませんでした。
したがって、答えは「いいえ」です
2. HuggingFaceが制作したモデル
「BLOOM」と「StarCoder」は、HuggingFaceが制作したモデルです。
2-1. BLOOM
「BLOOM」は、46の言語と13のプログラミング言語で学習したCLMです。これは、「GPT-3」よりも多くのパラメータを持つ最初のオープンソースモデルです。
2-2. StarCoder
「StarCoder」は、GitHub(80以上のプログラミング言語)の許容コードで学習された言語モデルで、Fill-in-the-Middleの目的があります。指示ファインチューニングしているわけではないので、与えられたコードを完成させるためのコーディング・アシスタントとしての役割がメインになります。例えば、PythonをC++に翻訳したり、概念(再帰とは何か)を説明したり、端末として機能したりできます。
3. ライセンス
以下は、完全にオープンソースのライセンスを持つ「CLM」のリストです。
・Falcon 40B
・XGen
・MPT-30B
・Pythia-12B
・RedPajama-INCITE-7B
・OpenAssistant (Falcon variant)
「コード生成モデル」には、「StarCoder」と「Codegen」のがあります。指示ファインチューニングされた「Codegen」を除いて、オープンなライセンスがあります。
「HuggingFace Hub」には、指示やチャット用にファインチューニングされたさまざまなモデルもホストされています。
・MPT-30B-Chat : CC-BY-NC-SA。商用利用を許可せず。
・MPT-30B-Instruct : CC-BY-SA 3.0。商業利用を許可。
・Falcon-40B-Instruct ・Falcon-7B-Instruct : Apache 2.0。商用利用も許可。
・OpenAssistant : 指示チューニングデータセットを使用して「LLaMA」上に構築されている。「LLAMA」は研究にしか使用できないため、完全なオープンソースライセンスはない。ただし、「Falcon」「pythia」などをベースにしたOpenAssistantモデルは、許容ライセンスを使用。
・StarChat Beta : StarCoderの指示チューニング版。商用利用を可能にするBigCode Open RAIL-M v1ライセンスを持っている。
・XGen model : Salesforceの命令調整されたコーディングモデル。研究の使用のみを許可。
4. LLMエコシステム
4-1. TGI (Text Generation Inference)
同時ユーザに対するレスポンスタイムとレイテンシは、これらの大規模モデルを提供するための大きな課題です。この問題に取り組むため、HuggingFaceはRust、Python、gRPcで構築された大規模言語モデル向けのオープンソースな推論ソリューション「TGI」(text-generation-inference) をリリースしました。「TGI」は、HuggingFaceの「Inference Endpoints」「Inference API」に統合されているので、数クリックで最適化された推論を持つエンドポイントを直接作成したり、単純にHuggingFaceの推論APIにリクエストを送るだけで恩恵を受けることができます。
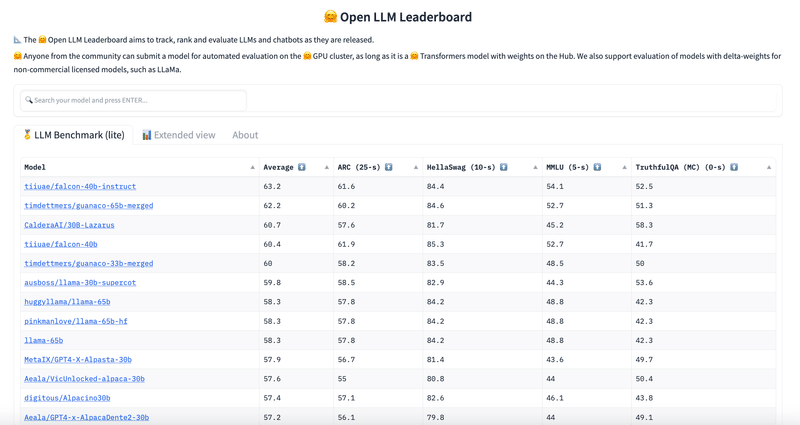
4-2. LLM leaderboard
HuggingFace は「LLM leaderboard」をホストしています。 これは、HuggingFace のクラスター上のテキスト生成ベンチマークでコミュニティから送信されたモデルを評価することによって作成されます。 探している言語またはドメインが見つからない場合は、ここでフィルタリングできます。
また、LLMのレイテンシとスループットを評価することを目的とした「LLM Performance leaderboard」をチェックすることもできます。
4-3. PEFT
「PEFT」は、パラメータ効率の高いファインチューニングを行うことができるライブラリです。これは、モデル全体を学習するのではなく、非常に少数の追加パラメータを学習することができ、パフォーマンスの低下をほとんどなく、より高速な学習を可能にします。PEFTを使用すると、「LoRA」(low-rank adaptation)「prefix tuning」「 prompt tuning」「p-tuning」を行うことができます。
この記事が気に入ったらサポートをしてみませんか?