
Petoi Bittle 入門 (20) - OpenCat Gymによる強化学習

以下の記事を参考に書いてます。
・Reinforcement Learning - OpenCat Gym
前回
1. ロボットと強化学習
近年、「強化学習」に関して多くの進歩があり、機械学習によってロボットの安定した歩行を実現できることを証明する多くの論文が発表されています。主に興味深く、比較的理解しやすい論文としては、「Sim-to-Real: Learning Agile Locomotion For Quadruped Robots」があります。
この論文の著者は、シミュレーションでの学習と、その後のロボットへの適用に基づいて、歩行と疾走の歩容を作成しました。その後の発表では、さらに進化して、シミュレーションなしでロボットに直接強化を介して新しい歩容を2時間以内に学習することを可能にしました。
他にも多くの例や異なるアプローチがあります。
これは非常に注目すべきことであり、「Nybble」と「Bittle」でもそこに到達できるのではないかと考えさせられました。
2. 強化学習の仕組み
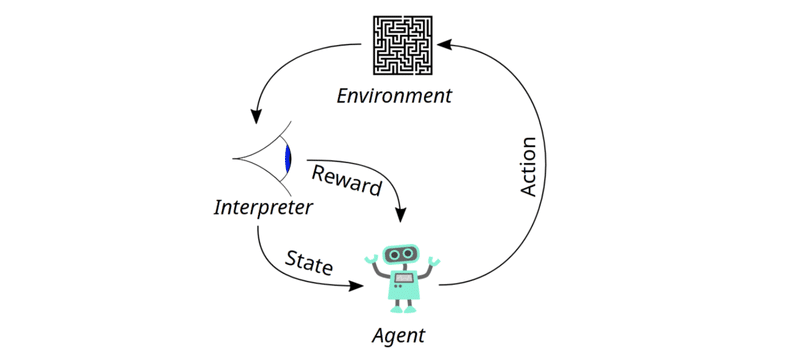
そもそも「強化学習」とは何か、少し落ち着いて考えてみましょう。下のグラフを見ると、その仕組みを基本を理解することができます。エージェント(ここではNybble/Bittle)は環境(例:平らな地面)に置かれます。そこで、手足をなんとか動かしたり、プログラマーからご褒美をもらおうとするなどの行動をとります。ご褒美は、状態が実際に欲しいもの、例えば前進しているときにのみ与えられます。このループに陥ったロボットは、反復するたびに報酬を最大化しようとし、どんどん動きが良くなっていきます。
3. OpenCat Gymによる強化学習
今回やってみたのは、平らな地面があるシミュレーション環境と、「Nybble」のシミュレーションモデルを使って、「Nybble」を前進させたいということです。これを強化学習ライブラリ「Stable-Baselines3」 を使って「PyBullet」のGymの学習環境に実装しました。
「強化学習」で使用できる学習アルゴリズムはたくさんあります。私の場合は、「SAC」(Soft Actor-Critic)というアルゴリズムを試しました。これは、現在の「強化学習」の最新アルゴリズムで、「Nybble」に適用して、その性能を確認しました。結果は、確かにまだ歩くというよりは這うような歩き方ですが、可能性は感じられます。

次のステップは、学習とその結果としての歩行を改善することです。そして、シミュレーションで良い歩行が得られたら、次に行うべきは、「Nybble」「Bittle」上で学習ポリシーを実行させる、あるいは直接学習させることです。そのためには、追加のハードウェアを使用する必要があると思います。
もしあなたが歩行訓練を行いたいのであれば、以下に私のリポジトリへのリンクがありますので、そこで更なるアップデートを行います。コードのimportセクションで、必要なPythonライブラリをすべてインストールすることを確認してください。
この記事が気に入ったらサポートをしてみませんか?