
LangChain のための wandb 入門

この入門記事は、「Weights & Biases」のご支援により提供されています。

1. wandb
「wandb」 (Weights & Biases) は、機械学習の実験管理とモデルのパフォーマンス追跡に特化したツールです。
「wandb」の主な機能は、次のとおりです。
・トレース : 実験のパラメータ、評価指標、出力を自動的にログに記録します。これにより、異なる実験間での比較や分析が容易になります。
・視覚化: 学習中の評価ををリアルタイムで視覚化します。これにより、モデルのパフォーマンスを直感的に理解しやすくなります。
・ハイパーパラメータの最適化 : 異なるハイパーパラメータのセットを試して、最適な組み合わせを見つけるのに役立ちます。
・チームコラボレーション : チームメンバー間で実験のデータを共有し、コラボレーションを促進します。
・統合 : 主要な機械学習フレームワーク (LlamaIndexやLangChain含む) に統合されているため、簡単に使用することができます。
「LlamaIndex」「LangChain」では、「wandb」を使うことでトレース情報の自動的記録が可能で、期待する応答が返されなかった場合、処理の流れを視覚化して原因を突き止めることができます。
2. wandbの利用料金
2023年現在、wandbの利用料金は、次のとおりです。個人利用は無料になります。
・パーソナルプラン : 無料
個人向けのプランです。無制限の実験、無制限のトラッキング時間、100GBのストレージとアーティファクトの追跡が含まれます。
・チームプラン: 月額$50 (1ユーザー、年払い)
企業向けのプランです。最初の250時間のトラッキングが無料で、年間5,000時間が含まれます。追加の時間は$1/時間で課金されます。最大10席までで、100GBのストレージとアーティファクトの追跡が含まれます。
・エンタープライズプラン : 料金はwandbに直接問い合わせ
企業向けのカスタムプランです。無制限のトラッキング時間、セキュアなストレージコネクタ、専門の技術サポート、カスタムストレージプランなどの機能が含まれています。
3. wandbのアカウントの作成
「wandb」を利用するには、アカウント作成が必要です。
(1) wandbのサイトを開いてサインアップボタンを押す。

(2) いずれかのアカウントでログイン。

(3) wandbアカウントの作成。
「氏名」「会社名」「ユーザー名」を入力して「Sign Up」を押します。

(4) プランの選択。

(5) wandbのホームの確認。
「APIキー」があるので、メモしておきます。

4. LangChain のトレース
「Google Colab」で「LangChain」のシンプルなRAGを作成して、wandbでトレースしてみます。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」を選択。
(2) パッケージのインストール。
wandbのパッケージをインストールします。
# パッケージのインストール
!pip install langchain==0.0.350 openai faiss-gpu tiktoken
!pip install wandb(3) 環境変数の準備。
左端の鍵アイコンで「OPENAI_API_KEY」に自分のOpenAI APIキーを設定してからセルを実行してください。

# 環境変数の準備 (左端の鍵アイコンでOPENAI_API_KEYを設定)
import os
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("OPENAI_API_KEY")(4) wandbのトレースの有効化。
環境変数「LANGCHAIN_WANDB_TRACING」にtrueを指定します。
import os
# wandbのトレースの有効化
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"(5) ドキュメントの読み込み。
左端のフォルダアイコンでドキュメント「akazukin_all.txt」 (ChatGPTに書かせた7章構成のサイバーパンク赤ずきんの物語) をColabにアップロードしてからセルを実行してください。

from langchain.text_splitter import CharacterTextSplitter
# ドキュメントの読み込み(カレントフォルダにドキュメントを配置しておきます)
with open("akazukin_all.txt") as f:
test_all = f.read()
# チャンクの分割
text_splitter = CharacterTextSplitter(
separator = "\n\n", # セパレータ
chunk_size=300, # チャンクの最大文字数
chunk_overlap=20 # オーバーラップの最大文字数
)
texts = text_splitter.split_text(test_all)
# 確認
print(len(texts))
for text in texts:
print(text[:20].replace("\n", " ") + "… (" + str(len(text)) + "文字)")チャンク数: 5
タイトル:「電脳赤ずきん」 第1章:デ… (261文字)
第2章:ウルフ・コーポレーションの罠 … (299文字)
それでも、ミコはリョウにデータを渡し、ウ… (272文字)
第5章:決戦の時 ミコとリョウはついに… (278文字)
第7章:新たなる旅立ち ウルフ・コーポ… (165文字)5つのチャンクに分割されていることがわかります。
(6) FAISSの準備。
「FAISS」は近傍探索のライブラリで、今回は、クエリから関連するチャンクを取得するために利用します。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.faiss import FAISS
# FAISSの準備
docsearch = FAISS.from_texts(
texts=texts,
embedding=OpenAIEmbeddings()
)(7) 質問応答チェーンの準備。
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 質問応答チェーンの作成
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff",
retriever=docsearch.as_retriever(),
)(8) 質問応答。
# 質問応答チェーンの実行
print(qa_chain.run("ミコの幼馴染の名前は?"))以下のようにAPIキーの入力が促されるので、自身のwandbのAPIキーを入力してください。リンク (https://wandb.ai/authorize) でAPIキーを取得することもできます。

(9) wandbのトレースの確認。
wandbコールバックマネージャのログのリンク (Streaming LlamaIndex events to W&B at …) からトレースの確認ページを開くことができます。

質問応答のトレース結果が保存されています。クエリ「ミコの幼馴染の名前は?」に対し出力「リョウ」を返したことがわかります。
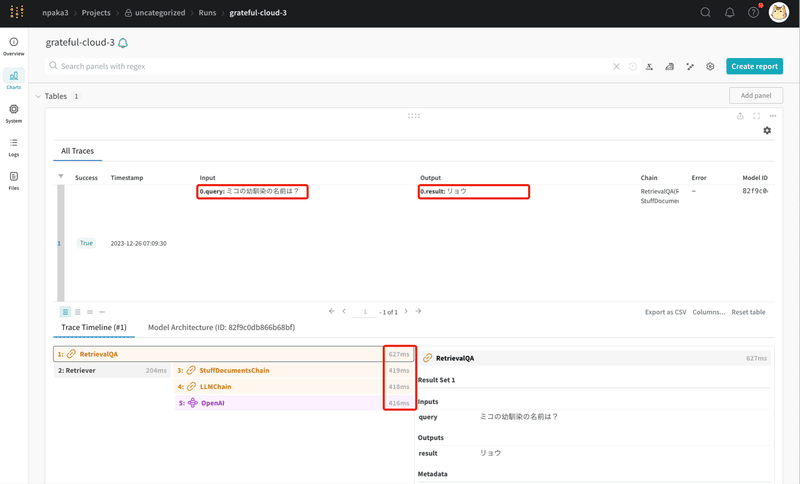
各コンポーネントの処理時間も視覚的に表示されており、ボトルネックが一目瞭然になります。エラー発生時には、そのコンポーネントがトレースが赤くハイライトされ、発生箇所を即座に特定することができます。
(10) wandbのトレースの詳細の確認。
トレース左の番号をクリックで選択し (今回はトレース1つなので選択されています)、下のトレースタイムラインの左端の□をクリックで、タイムラインが拡大表示されます。

このタイムラインの各コンポーネントをクリックすることで、入出力やメタデータなどの詳細を確認することができます。

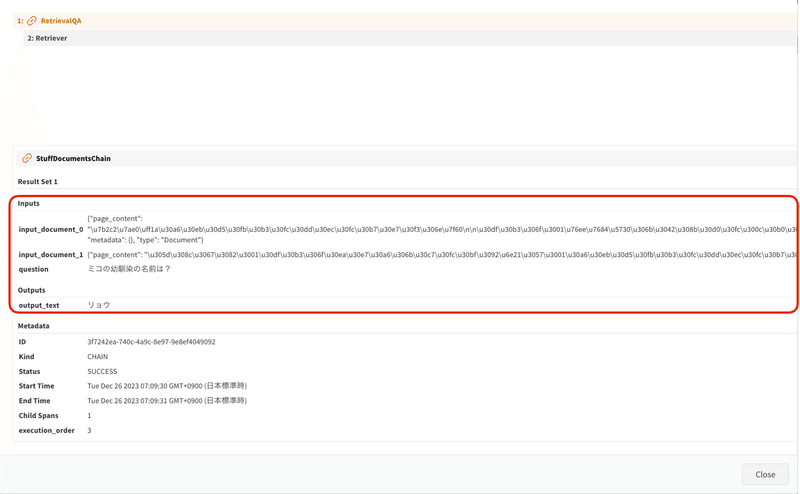
「StuffDocumentsChain」をクリックすると、クエリに応じて取得したチャンク (今回は2つ) を確認できます。
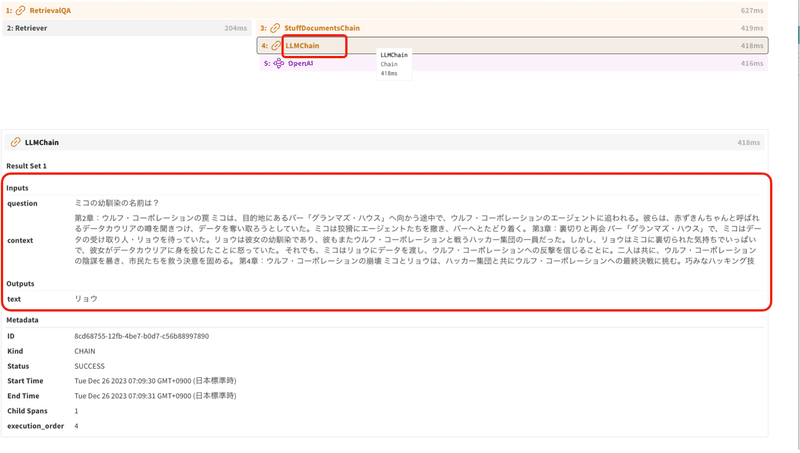
「LLMChain」をクリックすると、「クエリ」「コンテキスト」「出力」を確認できます。
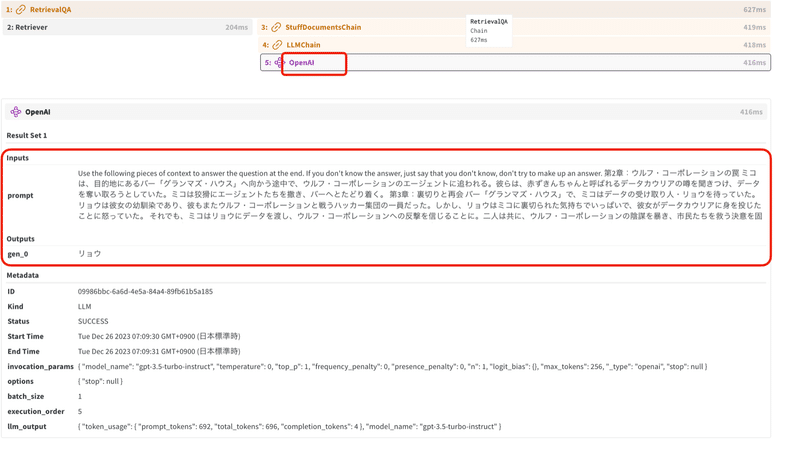
「OpenAI」をクリックすると、langchainのテンプレートを含む低レベルなプロンプトを確認できます。
5. おわりに
このように、環境変数「LANGCHAIN_WANDB_TRACING」にtrueにするだけで、「wandb」に「LangChain」のコンポーネントの各種情報を記録できます。期待する応答が返されなかった場合の調査などに非常に便利なので、ぜひ「LangChain」活用の際は試してみてください。
この記事が気に入ったらサポートをしてみませんか?