R/RStudioベーシック講座:顧客情報をTidyverseで分析

UdemyでR/RStudioベーシック講座【データ処理・グラフ作成】というコースの学習が進みました。今回はtidyverseで実践的なデータ分析・記述統計をする方法を学びました。例題としてISLRパッケージという、クレジットカード会社の匿名の顧客情報をグラフ化して分析しています。
棒グラフ、ヒストグラム、散布図、箱ひげ図の4グラフの適切な使い方の他、グルーピングでカテゴリー情報を追加する方法も掲載しておきます。
Tidyverse・ISLRパッケージを読み込み
#データの整形・視覚化に標準的に使われるtidyverseを使えるようにする
#tidyverseのパッケージにはggplot2,dplyr, readr等が含まれている
library(tidyverse)
setwd("C:/Users/user/Desktop/統計学習用資料")
#ISLRパッケージという、クレジットカード会社の匿名の顧客情報を分析にかける。
#今回は債務者か否かを分析したDefaultデータを使う。
#データには債務不履行者か否か(default)、学生か否か(student)、銀行残高(balance)、収入(income)の4カテゴリーの情報が載っている
#tidyverseでデータ分析をする際は、as_tibbleでtibble形式に変換する
install.packages("ISLR")
library(ISLR)
Default <- as_tibble(Default)
#head・summaryでデータ内容を確認
head(Default)
summary(Default)
#psychを使って相関係数・分布を表示
library(psych)
Default.s <- Default[,c(1,2,3,4)]
psych::pairs.panels(Default.s)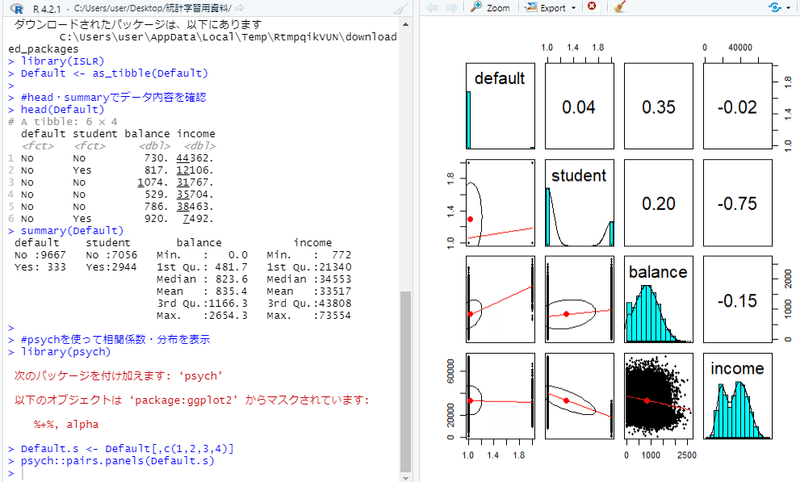
グラフを使った記述統計の基礎
データをどのように表示するかにはパターンがあり、
x軸にカテゴリー/離散変数、連続変数を使う場合、
y軸にカウント数、カテゴリー/離散変数、連続変数をつかう場合
これらをどう組み合わせるかでどのグラフで
データを表示するのが適切かが分かれています。
①(x軸、y軸)=(カテゴリー/離散変数、カウント数) → 棒グラフ
②(x軸、y軸)=(連続変数、カウント数) → ヒストグラム
③y軸がカテゴリー/離散変数 → 散布図
④(x軸、y軸)=(カテゴリー/離散変数、連続変数) → 箱ひげ図
⑤(x軸、y軸)=(連続変数、連続変数) → 散布図
gglot2を使った記述統計
gglpot2を使った記述統計ではまずグラフの下地を作成し、グラフ関数のメソッドを使って装飾するイメージで目的のデータ視覚化を行います。
#ggplotで棒グラフを描く。ISLRパッケージのデータの内、x軸に債務不履行か否かを表示する
ggplot(data=Default, mapping=aes(x = default)) + geom_bar(width=0.5, fill="steelblue")
#ggplotでヒストグラムを描く。ISLRパッケージのデータの内、x軸に銀行残高(Balance)、y軸に債務不履行者数(Count)を表す
ggplot(data=Default, mapping=aes(x = balance)) + geom_histogram(bins = 50, fill = "steelblue")
#ggplotで散布図を描く。散布図を描くには点を配置するgeom_point,近似曲線を描くgeom_smoothを使う
#x軸は収入、y軸は銀行残高を表す
ggplot(data=Default, mapping=aes(x = income, y = balance)) + geom_point(colour = "steelblue",size=0.5) + geom_smooth(method = "lm")
#ggplotで箱ひげ図を描く。
#x軸は債務不履行者か否か、y軸は銀行残高を表す
ggplot(data=Default, mapping=aes(x = default, y = balance)) + geom_boxplot(fill = "steelblue")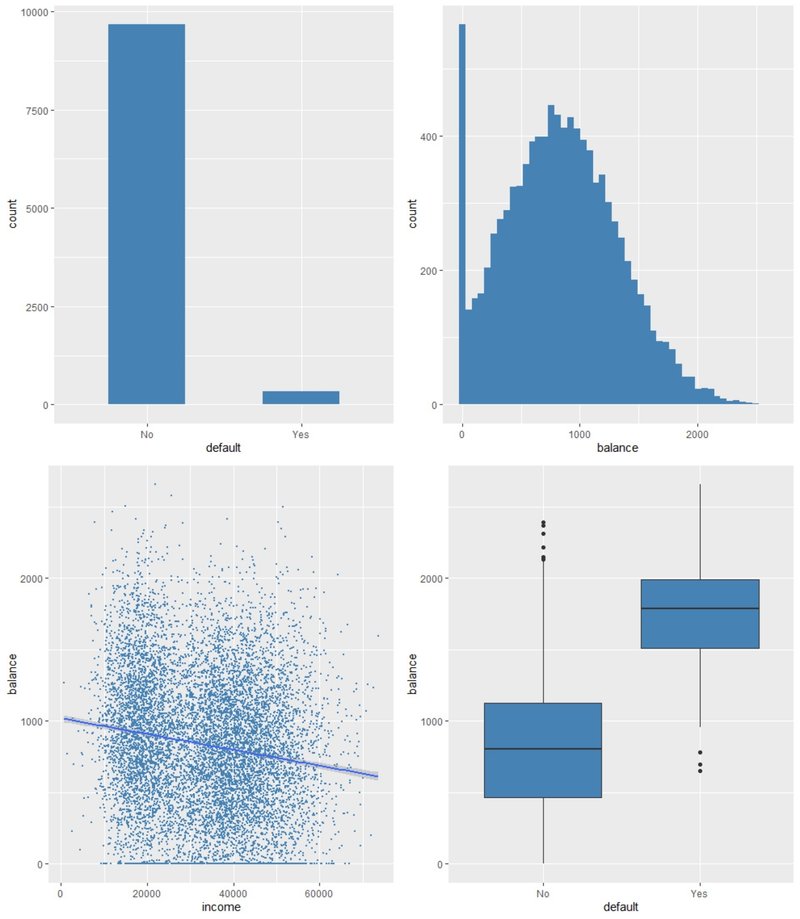
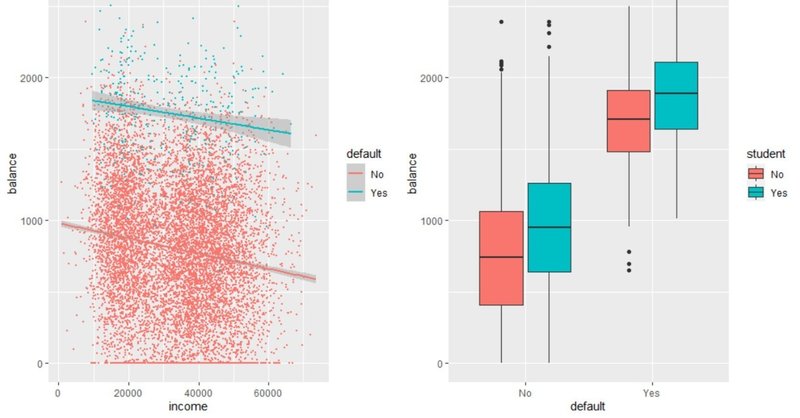
図を分析すると債務不履行者の数は約900の預金を平均とする正規分布に近い分布をしていること、予測とは逆に収入と預金残高は府の相関となっていることが分かります。債務不履行者の預金残高がそうでない人々よりも優位に高いというのは、箱ひげ図を見れば瞭然ですね。
gglot2を使った記述統計、グルーピング編
次に、グルーピングを使ってカテゴリーの違うデータを比較する方法を紹介します。グルーピングを活用すれば棒グラフ、ヒストグラム、散布図、箱ひげ図にもう一つカテゴリー情報を追加できます。
ISLRパッケージの場合はカテゴリー情報にdefault, studentの様な2値情報を使うのが有効です。
#ISLRパッケージ=クレジットカード会社の匿名の顧客情報を分析にかける
#tidyverseでデータ分析をする際は、as_tibbleでtibble形式に変換する
library(tidyverse)
library(ISLR)
setwd("C:/Users/user/Desktop/統計学習用資料")
Default <- as_tibble(Default)
#グルーピングした棒グラフを描く。カテゴリごとに離散量を表示するのに使う
#離散量と2つのカテゴリにどんな関係があるかを知りたい時に有効
#fillにグルーピングしたい変数(student)、positionに配置法(position_dodge → 横に配置)を指定する
ggplot(data=Default, mapping=aes(x = default, fill = student)) + geom_bar(width=0.9, position = position_dodge())
#グルーピングしたヒストグラムを描く。カテゴリごとに散布の仕方が知りたい時に有効
#fillにグルーピングしたい変数(default)、positionに配置法(position_identity → 同じグラフに表示)を指定する
ggplot(data=Default, mapping=aes(x = balance, fill = default)) + geom_histogram(bins = 50, color = "black", position = position_identity(), alpha = 0.8)
#グルーピングした散布図を描く。カテゴリごとに散布の仕方が知りたい時に有効
#aesのcolourにdefaultを指定。指定したカテゴリの値ごとに分布の色が変わる
#またグループごとに近似曲線を描いて比較することも可
ggplot(data=Default, mapping=aes(x = income, y = balance, colour = default)) + geom_point(size=0.5) + geom_smooth(method = "lm")
#グルーピングした箱ひげ図を描く。カテゴリごとに散布の仕方が知りたい時に有効
#fillにグルーピングしたい変数(student)を指定
ggplot(data=Default, mapping=aes(x = default, y = balance, fill = student)) + geom_boxplot()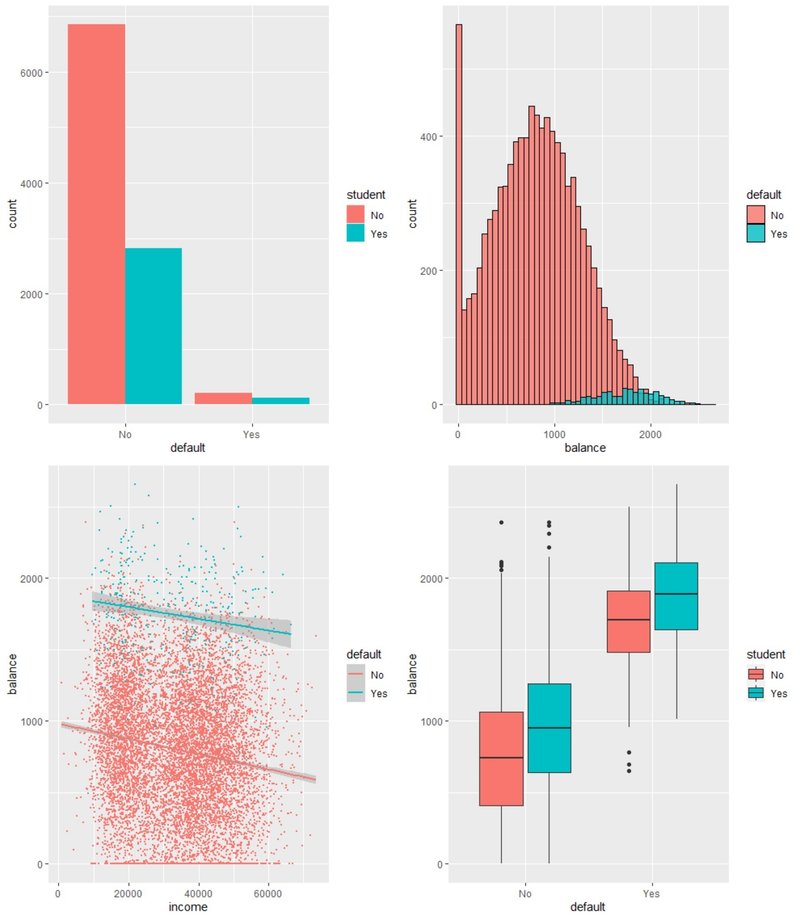
分布図を見ると、債務不履行者・債務不履行者でない顧客の分布を描くことができます。どちらも正規分布に近い分布をしていますが、債務不履行者は前回の図でも触れたとおり預金残高の平均値が約1800と債務不履行者でない顧客の約倍近くあることが分かります。一方学生か否かを見てみると、債務不履行者・債務不履行でない者双方のケースで若干預金残高の平均が高い傾向があるようです。これはやや直感に反する結果ですね。
次回はデータの整形・集計に関する記事を書きたいと思います。お楽しみに!
この記事が気に入ったらサポートをしてみませんか?