こんにちは。 今日はAIを使えばスロットで勝てるのか? みていきたいと思います。 とは言いましても諸事情により実際にお金はかけられないので、 iPhoneのスロットアプリで検証していきたいと思います。 まず前提として、スロットには『設定』というものがあります。 今回ターゲットにした機種も1~6まで『設定』があり、 『設定』が高いほど勝ちやすいです。 そして各設定ごとの当たりの確率が公開されています。 つまりAIですべきことは『設定』を予測することです。 店
こんにちは。 日本でもコロナウィルスが猛威をふるうようになりました。 みなさまが健康であることを祈るばかりです。 ※2020年3月現在 さて、ここではTwitterでのコロナウィルスの反応を見ていきます。 当社のTwitter感情分析アプリを使って『コロナ』で検索しました。 結果がこちら ネガティブな感情ばかりかと思いきやわりとまんべんなく感情が分散していました。 試しに分析対象になったツイートを読んでいくと、第一印象として冷静なツイートが多く、感情的なツイー
こんにちは。 今日はひさびさにTwitterを分析していきたいと思います。 今回気になったのは 『ツイートをキーワード検索したとき、どの時間帯でもいいねやリツイートの数の見込みは変わらないか?』 です。 とりあえず見込みは変わらないものとして分析していきましょう。 キーワードに選んだのは、お笑い芸人のオードリーさん。 『オードリー』で検索、ツイートを集めたとある日の時間帯ごとのいいね、リツイート数の平均値がこちら 夜中の3時台に突然高いいいね数(の平均値)を記録してい
こんにちは。 AIの重要な課題の1つは”分類”です。 今日は分類アルゴリズムの中でも特に有名なロジスティック回帰を実装してみました。 数式で書き起こすところから実装したところ、感想は 簡単だ。。。。 しかし簡単さにも関わらずアヤメデータ(花のデータ)の分類問題の正解率は90%以上! ちなみに2値分類(例えば男女の判別など)と多値分類(選択肢が2以上の場合)の両方とも実装してみましたが、どちらも簡単に実装でき、多値での正解率(交差検証法による)は 98.7%!ちな
前回の記事で気象庁からダウンロードした気象データに対して正解率を競い、 弊社AIが全勝ということで終わりました。 しかしですよ、こう思った人もいるのではないでしょうか… アヤメデータで勝たないと意味ないんじゃない?そうです。最初に負け気味判定だったアヤメデータ。 アヤメデータで勝ってこそ真の勝利。 そこで弊社AI、ゼロから作り直しました。 ベイズモデルには変わりありませんが、別の理論を採用しました。 アヤメデータと気象データの両方についていざ勝負! 判定方法は
前回”やや負け気味”の判定で終わった 弊社AI VS Scikit-Learnライブラリ しかし負けたままでは終われません。 負けた直後に弊社AIを強化改善しました。 それとアルゴリズムの致命的なミスを発見しました…。 そして前回はScikit-Learn側で用意しているアヤメデータを対象データとしましたが、 今回は公平を期して気象庁の天気データを対象データとしました。 気温、日照時間、気圧から天気を判別できるか?? ただし気象庁の天気の判定は”晴後一時雨”な
こんにちは。 今回は対決企画です。 弊社開発の分類用AI(ベイズ確率モデル)とPython機械学習ライブラリとしてお馴染みのScikit-Learnライブラリのアルゴリズムで予測精度を競います。 対象のデータはSkit-Learnライブラリから提供されている、有名なアヤメデータ(分類用の花のデータ)です。 今回Scikit-Learnからエントリーしてもらうのは ・ロジスティック回帰 ・SVM(サポートベクターマシン) そして最後は最強の刺客 ・ランダムフォレ
こんにちは。 弊社で開発したAIを使って任意の会社の株価の動きを予測するアプリを作りました。 企業コードを入れることで様々な企業の株価の動きを予測してくれます。 データは6時間おきに自動更新され、最新の情報のもとで予測します。 以下、予測例です 青線・・・実際の株価 赤線・・・AI予測 グラフを見るとAI予測の赤線はしっかりトレンドを捉えていることがわかります。 右端の赤線だけの部分が向こう10日間の予測になります。 以上、開発したアプリの紹介でした。
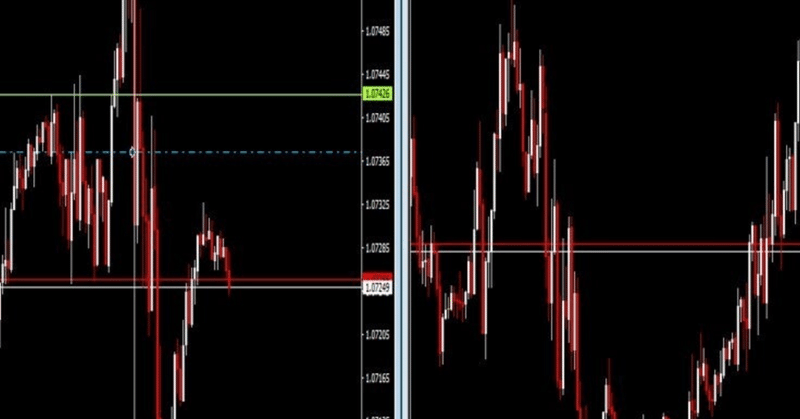
こんにちは。 今日は弊社で新しく開発したAI(回帰モデル)で実際にFXのデータを予測できるか試してみました。 用意したのは毎日の円/ドルデータです。 過去200日まで遡って170日分を学習データ、直近30日分を予測用データとしました。 結果がこちら 青線・・・学習データ 赤線・・・AIの予測 緑線・・・正解 全体としてトレンドは掴めていますね。 予測部分に関しては当たったのか微妙です・・・。 この後下がったとしたら当たっていると言うことになりますね。 今
統計ってどんなことに役に立つのか? . . . そもそも統計ってなんだ? という方も多いと思うので、今日はざっくりと紹介していきたいと思います。 まず統計の話をするにはデータが必要です。 売り上げデータ、視聴者データ、試験データなど、世の中はデータで溢れています。 これらのデータは自分からはなにも語りませんが、 こちらから積極的に話しかけることで色々なことを教えてくれます。 統計をする上で必ず登場するのが統計量。 統計量とはデータから算出される値の総称で
こんにちは。 今日はTwitterのAPIを使って取り出したデータを使ってお話していきたいと思います。 TwitterのAPIを使えば、 ・ツイート本文 ・いいね数 ・リツイート数 ・投稿日時 ・ユーザー情報 など、様々な情報を手に入れることができます。 今回は「菅田将暉 ANN」で検索した結果のツイートを男女別に分析してみました。 ※リツイート、URLを含むツイートははじいています。 ツイートごとのいいね数の平均値を男女別に比較してみましょう。 女性
こんにちは。 今日は多項式回帰を通じてベイズ推定と最尤法について話していきたいと思います。 まず準備したダミーデータはこちら 青い点が今回観測された(とする)データです。 本来はオレンジの曲線上に乗るはずのデータが、なんらかのノイズによりずれてしまっていると考えます(実際は意図的にずらしました)。 さて、多項式回帰を使って、観測された青い点からオレンジの曲線=真の分布を予測しようという試みます。 多項式回帰とは y=w0+w1x+w2x2+...+wnxn�=�0
こんにちは。 今日は統計検定2級を受けた時のレポを書きたいと思います。 統計検定2級を受けるにあたってまず最初に勉強したのが、 統計学入門 東京大学出版会 言わずと知れた”赤本”です。 文体はやや硬いものの、高度な数学は使っておらず、目で追うだけでさらさら読めました。 念のため2回読んだのですが、やはり2周するとかなり理解度が上がります。 そして公式テキストで過去問を解きました。 1回目 55% 2回目 65% 3回目 75% 4回目 80% と順調に正答率は上が
こんにちは! 今日は正則化について扱っていきます。 前回FXデータに対して重回帰分析を行いましたが、重みはさほど大きくなりませんでした。これはもともとのデータが直線的だったからです。 しかし一般的にデータが直線的であるとは限らず、すると重みがとても大きい値になることがあります。これを過学習と呼びます。 過学習してしまうと、学習データにはよく当てはまるのですが、未知のデータに対する予測精度は下がってしまいます。 そこで過学習を防ぐために重みが大きくならないようにするの
こんにちは! 前回はFXデータの単回帰分析を行いました。 今回は重回帰分析を行なっていきたいと思います。 単回帰分析と違うところは、説明変数が複数あるところです。 単回帰分析では、 目的変数 円/ドル 説明変数 先月の円/ドル としましたが、 今回の重回帰分析では、 目的変数 円/ドル 説明変数 円/ドル、円/ユーロ としました。 CSVから読み込んだデータがこちら これを3次元グラフに表すと、 ここで重回帰分析を行なっていきます。 単回帰分析では
こんにちは! 今日からFXのデータを使って色々なアルゴリズムを試してみた結果を記事にしていきたいと思います。 初回は線形回帰の基礎の基礎、単回帰分析です。 回帰分析というのはざっくりいうと数値を予測するアルゴリズムです。 その中で最もシンプルなのが単回帰分析です。 予測したい数値データのことを目的変数と言います。 予測のために使うデータを説明変数と言います。 単回帰分析は目的変数1つ、説明変数1つの簡単な線形回帰分析です。 今回は 目的変数→円/ドル 説明変数→先