日本の人事を科学する

この記事は日本の人事を科学する 因果推論に基づくデータ活用 (Japanese) Tankobon Softcover – June 15, 2017が元になっています。
人事の領域にもデータサイエンスが活用されるようになってきました。
今回はより実践的な内容を書けたらと思っています。
これまでの人事とこれからの人事
これまで人事では経験と勘による運用がされ、多くの人事データは利用されないまま、時には廃棄されてきました。
背景には人事に配属される人が文系出身が多く、統計の知識が不足していた点や新卒一括採用の文化があり、一元管理がされていたため大きな方針は決まっていてその中から勘で判断をしたところで大きな間違いにはならなかったことがあげられます。
しかし、働き方が多様化したことやクラウドの発展により、データ収集・集約・客観的な成果指標が比較的容易になったことでデータを活用するメリットが増えてきています。
Googleでは元々16~25回、採用時に面接がありました。社員の質に妥協しないため、社内の集合知への信奉があったためです。
しかし、1人増やすごとの選別精度を測定したところ、5人目以降の面接では1%しか予測精度に影響を与えないことがわかりました。
これにより90~180日かかっていた採用フローを47日にまで減らすことに成功し、応募者の評判も大きく改善しました。
これはかなりドラスティックな改善ですが、どの会社でも改善の余地のある人事制度や慣習などはあるのではないでしょうか?
効果測定で一般的に使われる方法
マッチング法
これは効果測定を考える時に思いつくシンプルな方法かもしれません。
条件のよく似たサンプル同士に、1つだけ条件を変えてその後の結果を見るやり方です。広告の時のA/Bテストがまさにこれにあたるかと思います。
サンプルの抽出の条件決めと母数が最低でも半分にはなってしまうので母数の問題はありますが、導入もしやすいやり方です。
回帰不連続デザイン
これもマッチング法同様、よく使われるやり方かもしれません。
介入前と介入後を純粋に比べるやり方です。
時系列が別れてしまうので、介入の前後の条件を見る必要がありますが、先程のマッチング法で問題になった母数の問題をクリアしやすい点から、これも導入のしやすいやり方です。
回帰分析
連続尺度の従属変数(目的変数)Y と独立変数(説明変数)X の間にモデルを当てはめることで、X が1次元ならば単回帰、X が2次元以上ならば重回帰と呼びます。なぜ離職するのかを考える時なら、離職が目的変数、なぜの理由になりそうな項目(賃金が安い・労働環境が悪いなど)が説明変数です。
それぞれの説明変数がどれくらい目的変数を説明できているかを計るのが回帰分析です。
文字にすると複雑に見えますが、RやPython、その他ツールを使えば誰でも回帰分析はできます。エクセルでもできます。
マッチングや回帰不連続デザインでは、条件のコントロールが必要ですが、回帰分析ではどの説明変数が目的変数を説明しているかを定量で見ることができる点や未知のものを定量で予測することができる点が優れます。
女性の活躍推進施策を効果測定する場合
1つの指標として、男女の平均賃金格差を見る方法があります。
しかし純粋に男女の賃金格差をみてしまうと、男女間で発生する学歴や年齢、勤続年数の構成の影響を大きく受けてしまいます。
ここで男女以外の特性を全て同じで比較する必要があるため、回帰分析を用います。
データはこちらから使わせていただきました。
賃金を目的変数(説明したい値)として、以下の値を説明変数(賃金の構成要素)としました。
①性別(male/female)
②年齢
③学歴(univ/ post_high/ high/ junior_high)
命名のセンスは置いといて、univが大卒以上、post_highが専門学校・短大、highが高卒、junior_highが中卒になっております。
④企業規模
bigが大企業、middleが中企業、smallが小企業となっています。
上記を元に、重回帰分析をしてみました。
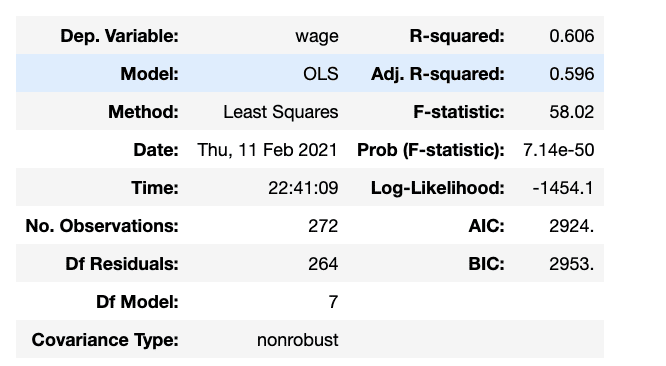
Adj. R-squaredがどれくらい目的変数である賃金を説明できているかを表します。0.596なのでまずまずの値だとは思います。
とはいえ他にも構成要素はありそうだなというくらいの値です。
次に各説明変数ごとにみてみます。
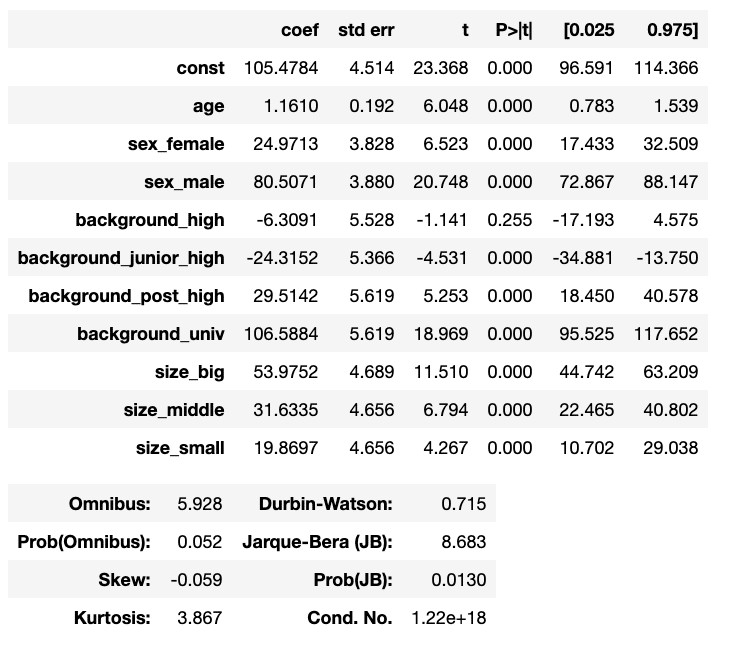
coefが係数です。大きいほど説明変数として強い値になります。
constを除いた、ageから下が説明変数たちです。
性別と学歴での値が影響大きそうですね。
これは1年でのデータなのでこれの推移を見ることで、施策としての評価ができると思います。ただ現状として格差が0ではないことは結論づけられそうです。
まとめ
環境が代わり、データを容易に収集・加工することができる時代になったので、データから遠い仕事も段々にデータを使うようになる流れになりそうなのを感じました。
そのときにデータを使うことによってこんなこともできることを提案して価値を感じていただけるかどうかがデータサイエンティストの腕の見せ所なのかもしれません。
この記事が気に入ったらサポートをしてみませんか?