
SLO はじめました

今年の夏は短く、冷やし中華をあまり食べられなかったなと思う @kumagaias です。
夏の品質を測るのも難しいですが Web サービスの基本的な品質を測るのも難しいですよね。
例えば・・
・バグが少ない。
・サービスが安定している。
・レスポンスが速い。
しかし、これらをどうやって測りましょう?
SLO がプロジェクトに導入されてから 10 ヶ月ほど経ち、サービスの品質を測る上で有益だと感じておりますので、共有させて頂きます。
SLO とは?
SLO は Service Level Object (サービスレベル目標) です。
例えば、私の参加しているプロジェクトではサービスごとに
・リクエスト成功率 x %以上
・API はレスポンスを y 秒以内に返す (レイテンシー y 秒以内)
を定めております。
また、サーバー監視 & 分析サービスの Datadog を導入し、APM を通じて Datadog に情報を集約しております。
その上で Datadog の SLO 機能を利用してダッシュボードを作成し、いつでも誰でもリアルタイムで SLO を確認できるようにしております。
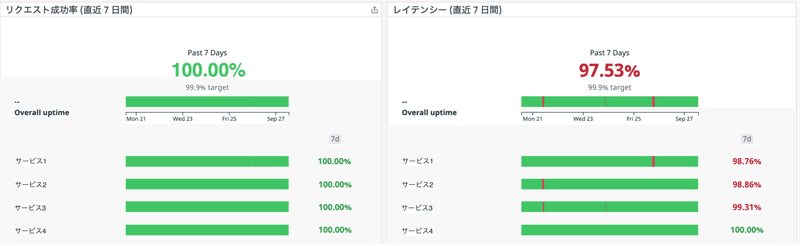
(※ 画像はイメージです。)
ちなみに・・ SLA とは?
SLA は Service Level Agreement (サービス品質保証) です。Azure, AWS, GCP など有名なクラウドサービスは SLA が定められていますので、SLO より身近かもしれません。
(例)
・サーバーの可用性 99.9 %以上
・障害から回復するまでの時間: 1 時間以内
こちらは契約のため、SLAを下回った場合は返金が発生等が考えられます。
SLO と SLA の違い
視点の違いだと思います。
例えばユーザー視点だと、各 API のレスポンスが x 秒以内というような細かい指標よりは、サービス全体の安定性・性能や障害発生時の保証を知りたいと思います。
逆に開発者視点だと、先月はサービスがダウンした・しなかった、というような大まかな観測より、サービス改善のために日々の細かい観測をしたいはずです。
以上より、
SLO: プロジェクト内向け、自発的なもの
SLA: プロジェクト外向け、契約
と言うことができると思います。
一般的に SLA は SLO より少し緩めに設定することが多いようです。
参考: SLO、SLI、SLA について考える : CRE が現場で学んだこと
SLO の指標
RED メソッドと USE メソッドがよく知られています。
RED メソッド
Rate - 1 秒あたりのリクエスト数
Errors - 1 秒あたりのリクエストエラー数
Duration - 各リクエストの時間
リクエストエラーは 500 系のエラーを対象としています。
参考: The RED Method: key metrics for microservices architecture
USE メソッド
Utilization: 使用率 (例: ディスク使用量が 90% )
Saturation: 飽和率 (例: CPU の load average が 4)
Errors: エラー率
参考: The USE Method / Brendan Gregg
私の参加しているプロジェクトでは、障害が起きた時はまず RED で考え、次に USE も考えてみる、と言った具合で利用しています。
1. RED によりユーザーのリクエスト状況を把握する。
2. USE により queue や thread の待ちが発生していないか。
3. 上記でわからなかった場合はアプリケーションや各種ミドルウェアの詳細なメトリクスを参照する。
障害の原因を把握するにはまずユーザーに近いメトリクスから監視することが良いとされています。
SLO を決めるときに困ったこと
最初は SRE チームから「SLO っていう良い考えがあるから、新規機能開発チームと保守チームで話し合って決めてみて。」と優しく言われたのがきっかけです。
当時、私も含め開発者大半が SLO って何??という状態だったと思います。またよくわからない 3 文字の英字が出てきてしまったな・・と。
ともあれ新規機能開発チーム・保守チームで SLO を決めるべく数回ミーティングをしました。
困った点は、新規機能開発チームと保守チームで温度感が違ったことです。保守チームは日頃から監視をしているため関心がありましたが、新規機能開発チームからはなぜ SLO を決めないといけないのか?という率直な意見も出ました。
これは当然のことで、当時はチームごとに役割 (壁?) がカッチリ決まっていました。
ですので SLO を決める前提で話を進めるのではなく、そもそもなぜ SLO を決めるのか?からみんなで話し合いました。その結果、下記のようになりました。
・SLOを決める理由は品質の維持を行うためです。
・品質の維持は誰のために行うのかというとサービスを使うユーザーのためです。
(※ 掲載にあたり一部変更してあります。)
SLO がもし誰かから押し付けられた SLO であったとしたら、開発者はあまり見なくなり、いずれ形骸化していたかもしれません。
SLO の具体的な数値は今までのサービスの実績を元に算出し、最初はお試しで設定し、適宜見直していこう、となりました。
また、エラー・バジェットや、Apdex という考えも魅力的でしたが、いったんはシンプルにリクエスト成功率とレイテンシーに絞り、導入の障壁をできる限り無くそうと考えました。
SLO を入れたらこうなった
こんな声が挙がっています。
・異常にすぐ気付けるようになった。
以前はユーザーからお問い合わせを頂いてから調査することも多かったです。
現在はお問い合わせを頂く前に調査を開始し、先手を打てるようになりました。
・異常じゃないことにも気付けるようになった。
以前はユーザーからお問い合わせを頂いた際、システムのどこかに不具合がある前提で調査を開始することが多かったです。
現在はまず SLO を見ることで事象が全体で起きているのか、レアケースなのか、もしくはエラーは起きていない (ユーザーの操作ミス等) を素早く判別でき、原因判明までの時間が短くなりました。
・マイクロサービスの中で、どのサービスが悪くなっているかわかりやすくなった。
以前は調査の際、まず各サービスのエラーログを見に行っており、それから問題があるサービスを特定しておりました。開発者にしかできない & 担当者のスキルで原因判明までの時間が大きく変わっておりました。
現在は問題のあるサービスが一目瞭然、また開発者以外でも (例えばディレクター等) でも初期調査が可能となりました。
・ パフォーマンスを意識したアプリケーションを作る意識になった。
以前はリリース後、サービスの健康状態の変化が可視化されていない状態だっため、新規機能開発チームではリリースまでが主な関心事だったと思います。
現在は SLO という誰が見ても明確な基準があるため、SLO を下げないようにパフォーマンスを意識して作るようになった、という声が挙がりました。
SLO が形骸化しないように
以下を実施しています。
・プロジェクトメンバーが参加するデイリー (昼会) で SLO を見る時間を毎日 5 分ほど設ける。
・SLO 当番 (日替わり) がリモートで画面共有する。SLO を下回った時間帯の状況をみんなで確認し、原因等を軽く話し合う。
毎日実施した結果、不具合に気づくのが早くなり、ユーザーからお問い合わせを頂く前に行動を起こせるようになりました。
また、自分達のサービスの健康状態を話し合う場になり、開発、デザイン、保守、基盤、チームに関係なく話し合えるようになりました。
最後に
SLO はプロダクトに確実に良い影響を与えていると思います。
ポイントは
・SLO はプロジェクト内の自発的な目標である。
・SLO はチームの壁を超え、プロダクトの品質について話し合う場を与えてくれる。
と思っております。
うちのプロジェクトの SLO はこうだよ!
SLO に興味あるけど、どう導入したら良いかわからない・・
等ありましたら、お気軽にコメント・シェア頂ければ幸いです。
最後までお読み頂きありがとうございました!
この記事が気に入ったらサポートをしてみませんか?