【東証XBRL】決算短信の前年同期比(%)は千円単位?百万円単位?選好している?(Python, R)

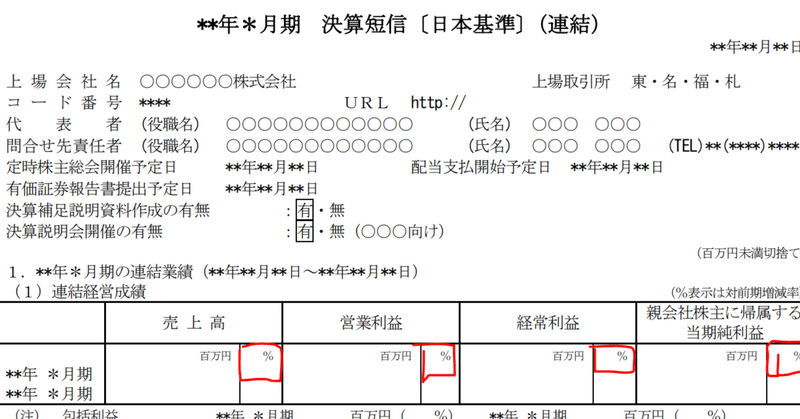
決算短信を読んだとき、前年同期比のパーセント数値が百万円単位で計算されているのか、千円単位で計算されているのかが気になりました。今回気にしているのは、決算短信1ページ目の(1)連結経営成績にある%数値です(下図参照)。

大学の財務モデリングの授業中、Excelで計算した値と決算短信の値を比較したときに、財務諸表の伸び率と短信の伸び率が異なっていたので、おそらく財務諸表で表示される数値単位に揃えて計算しているんだろうな、という固定観念を持っていました。
今回、東証XBRLに触れたかったので、そのおまけとして企業はどの単位に合わせて計算を行っているのかを調べてみました。
方法
そもそも、決算短信に記載される変化率(%)は、何円単位で計算する、という基準は無いようです。金額に対しては百万円単位は四捨五入までOKという記載でした。

とくに明確な基準がない以上、自分で調べてみる価値がありそうな話題であることが分かりました。ここから検証の方法・結果について書いていこうと思います。
検証方法:TDnetに掲載されている過去1か月間のXBRLをダウンロード。
XBRLの解析:Python(Raspberry Pi)
データの整形:R(Rstudio, Windows)
① TDnetからダウンロード
2023年10月10日~2023年11月10日に提出された決算短信を使用しました。訂正書類を考慮するのは現実的ではないので今回は利用しませんでした。
②XBRLの解析
東証XBRLとEDINETのXBRLの違いについてあまり理解していなかったので、とりあえずすべてのタグを取得するようにしました。
ダウンロードしたXBRLは./temp/xbrl/というディレクトリにzipファイルのまま配置しました。またこだわりとして、Pandasを使うと処理が重くなる印象があったので楽をせずにlistで処理するようにしました。
import zipfile
import pandas as pd
from bs4 import BeautifulSoup
import glob
import re
def load_attr_val_numeric(tag):
return [tag.text, tag.get("contextref"), tag.get("decimals"), tag.get("scale"), tag.get("format"), tag.get("name"), tag.get("sign"), tag.get("unitref"), "", ""]
def load_attr_val_nonnum(tag):
if "TextBlock" in tag.get("name"):
return
return [tag.text, tag.get("contextref"), "","",tag.get("format"),tag.get("name"),"" , "", tag.get("escape")]
columns = ["scode","value","contextref(共通)","decimals","scale","format","name(共通)","sign","unitref","escape","format"]
df = pd.DataFrame()
# file_list = glob.glob("**.zip")
file_list = glob.glob("./temp/xbrl/**.zip")
# 拡張子でファイルを選択してみる
re_match_summary = re.compile(r'.*/Summary/.*ixbrl\.htm$').match
re_match_attachment = re.compile(r'.*/Attachment/.*ixbrl\.htm$').match
first_time = True
for file_name in file_list:
print(file_name)
with zipfile.ZipFile(file_name, 'r') as zip_data:
innner_zip_content = zip_data.infolist()
find_company_info = False
scode = ""
array_outer = []
for _file in innner_zip_content:
#短信サマリー
if re_match_summary(_file.filename):
print(_file.filename)
file_data = zip_data.read(_file.filename)
for tag in BeautifulSoup(file_data).find_all('ix:nonfraction'):
array_outer.append(load_attr_val_numeric(tag))
for tag in BeautifulSoup(file_data).find_all('ix:nonnumeric'):
array_outer.append(load_attr_val_numeric(tag))
if find_company_info == False:
if tag.get("name") == 'tse-ed-t:SecuritiesCode':
scode = tag.text
#短信財務諸表
if re_match_attachment(_file.filename):
print(_file.filename)
file_data = zip_data.read(_file.filename)
for tag in BeautifulSoup(file_data).find_all('ix:nonfraction'):
array_outer.append(load_attr_val_numeric(tag))
# この時には証券コードが分かっているはず
array_outer = [[scode] + sublist for sublist in array_outer]
if first_time == True:
df = pd.DataFrame(array_outer, columns = columns)
first_time = False
else:
df = pd.concat([df, pd.DataFrame(array_outer, columns = columns)])
df.to_csv("result.csv", index = False)③データの整形
今回出力したresult.csvにはすべての決算短信のXBRL情報が縦持ちで保管されています。正直これを開示書類ごとにグループ化して処理を行うのが面倒(というか上手いやり方を知らない)ので、大学時代に頑張ってかいたRのコードを真似てそちらで処理をすることにしました。
すこし話がそれますが、○○ごとにグループ化して処理、というのはPythonのPandasよりもRに軍配が上がると思います。
例えばPandasのgroupbyは、続けて書ける処理は統計的処理しかなかった気がします(sum()とかmean()とか)。一方で、Rのtidyverseを使えば、group_by()で開示資料ごとのグループを作成できて、ungroup()するまではグループ内で前処理が容易に書けるんです。
library(tidyverse)
getwd()
df <- read.csv("./result.csv")
# サマリの変化率のcontextRefを抽出する
# ややこしいので連結に限定する
#売上高、営業利益、経常利益、当期純利益(会計基準注意)で分ける
#決算SUMMARY部分
df_sm_netsales <- df %>%
group_by(filename) %>%
filter(str_detect(name.共通., "tse-ed-t:NetSales")) %>%
filter(str_detect(contextref.共通., "ResultMember")) %>%
ungroup()
df_sm_netsales$value = as.numeric(gsub(",", "", df_sm_netsales$value))
df_sm_netsales <- df_sm_netsales %>% drop_na(value)
df_sm_opein <- df %>% group_by(filename) %>%
filter(str_detect(name.共通., "tse-ed-t:OperatingIncome")) %>%
ungroup()
df_sm_opein$value = as.numeric(gsub(",", "", df_sm_opein$value))
df_sm_opein <- df_sm_opein %>% drop_na(value)
df_sm_odiin <- df %>%
group_by(filename) %>%
filter(str_detect(name.共通., "tse-ed-t:OrdinaryIncome")) %>%
ungroup()
df_sm_odiin$value = as.numeric(gsub(",", "", df_sm_odiin$value))
df_sm_odiin <- df_sm_odiin %>% drop_na(value)
df_sm_profit <- df %>%
group_by(filename) %>%
filter(str_detect(name.共通., "tse-ed-t:ProfitAttributableToOwnersOfParent")) %>%
ungroup()
df_sm_profit$value = as.numeric(gsub(",", "", df_sm_profit$value))
df_sm_profit <- df_sm_profit %>% drop_na(value)
#財務諸表(Attachment)
df_at_netsales <- df %>%
group_by(filename) %>%
filter(name.共通. == "jppfs_cor:NetSales") %>%
mutate(count = n()) %>%
ungroup() %>%
filter(count == 2) %>%
select(!count)
df_at_netsales$value = as.numeric(gsub(",", "", df_at_netsales$value))
df_at_netsales <- df_at_netsales %>% drop_na(value)
df_at_opein <- df %>% group_by(filename) %>%
filter(name.共通. == "jppfs_cor:OperatingIncome") %>%
mutate(count= n()) %>%
ungroup()%>%
filter(count == 2) %>%
select(!count)
df_at_opein$value = as.numeric(gsub(",", "", df_at_opein$value))
df_at_opein <- df_at_opein %>% drop_na(value)
df_at_odiin <- df %>%
group_by(filename) %>%
filter(name.共通. == "jppfs_cor:OrdinaryIncome") %>%
mutate(count = n()) %>%
ungroup()%>%
filter(count == 2) %>%
select(!count)
df_at_odiin$value = as.numeric(gsub(",", "", df_at_odiin$value))
df_at_odiin <- df_at_odiin %>% drop_na(value)
df_at_profit <- df %>%
group_by(filename) %>%
filter(name.共通. == "jppfs_cor:ProfitLossAttributableToOwnersOfParent")%>%
mutate(count = n()) %>%
ungroup()%>%
filter(count == 2) %>%
select(!count)
df_at_profit$value = as.numeric(gsub(",", "", df_at_profit$value))
df_at_profit <- df_at_profit %>% drop_na(value)
## NoteToConsolidatedFinancialResultsはたぶん今期だけのContextRefを指名するはず
df_test <- df %>%
filter(name.共通. == 'tse-ed-t:NoteToConsolidatedFinancialResults') %>%
group_by(filename) %>%
mutate(count = n()) %>% select(filename, scode, count, contextref.共通.) %>%
distinct() %>% filter(count == 1) %>% ungroup() %>% select(filename, contextref.共通.)
tmp_current <- df_test
tmp_prior <- df_test %>%
mutate(contextref.共通. = str_replace_all(contextref.共通., pattern = "Current", replacement ="Prior"))
#このDFにあるcontextrefを見ればOK!!
tmp_target <- rbind(tmp_current, tmp_prior) %>% arrange(filename)
target_sm_netsales = left_join(tmp_target, df_sm_netsales) %>%
group_by(filename) %>% mutate(count = n()) %>%
ungroup() %>% filter(count == 2) %>%
select(!count) %>%
drop_na(value) %>%
group_by(filename) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(NETSALES_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(NETSALES_decimals = decimals) %>%
select(filename, NETSALES_RATE,NETSALES_decimals)
target_sm_opein = left_join(tmp_target, df_sm_opein) %>%
group_by(filename) %>% mutate(count = n()) %>%
ungroup() %>% filter(count == 2) %>%
select(!count) %>%
drop_na(value) %>%
group_by(filename) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>%
ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(OPEIN_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(OPEIN_decimals = decimals) %>%
select(filename, OPEIN_RATE, OPEIN_decimals)
target_sm_odiin = left_join(tmp_target, df_sm_odiin) %>%
group_by(filename) %>% mutate(count = n()) %>%
ungroup() %>% filter(count == 2) %>%
select(!count) %>%
drop_na(value) %>%
group_by(filename) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(ODIIN_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(ODIIN_decimals = decimals) %>%
select(filename, ODIIN_RATE, ODIIN_decimals)
target_sm_profit = left_join(tmp_target, df_sm_profit) %>%
group_by(filename) %>% mutate(count = n()) %>%
ungroup() %>% filter(count == 2) %>%
select(!count) %>%
drop_na(value) %>%
group_by(filename) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(PROFIT_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(PROFIT_decimals = decimals) %>%
select(filename, PROFIT_RATE,PROFIT_decimals)
target_sm_ALL = full_join(target_sm_netsales, target_sm_opein) %>%
full_join(target_sm_odiin) %>%
full_join(target_sm_profit)
################################
## 損益計算書側の数値で増減を計算する
target_at_netsales <- df_at_netsales %>%
group_by(filename) %>% drop_na(value) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(AT_NETSALES_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(AT_NETSALES_decimals = decimals) %>%
select(filename, AT_NETSALES_RATE, AT_NETSALES_decimals)
target_at_opein <- df_at_opein %>%
group_by(filename) %>% drop_na(value) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(AT_OPEIN_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(AT_OPEIN_decimals = decimals) %>%
select(filename, AT_OPEIN_RATE, AT_OPEIN_decimals)
target_at_odiin <- df_at_odiin %>%
group_by(filename) %>% drop_na(value) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(AT_ODIIN_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(AT_ODIIN_decimals = decimals) %>%
select(filename, AT_ODIIN_RATE, AT_ODIIN_decimals)
target_at_profit <- df_at_profit %>%
group_by(filename) %>% drop_na(value) %>%
arrange(contextref.共通.) %>%
mutate(CURRENT = value) %>%
mutate(PRIOR = lead(value) )%>% ungroup() %>%
drop_na(PRIOR) %>% select(!value) %>%
mutate(AT_PROFIT_RATE = (CURRENT - PRIOR)/ PRIOR * 100) %>%
mutate(AT_PROFIT_decimals = decimals) %>%
select(filename, AT_PROFIT_RATE, AT_PROFIT_decimals)
target_at_ALL = full_join(target_at_netsales, target_at_opein) %>%
full_join(target_at_odiin) %>% full_join(target_at_profit)
#######################################
####変化率データを科目ごとに取得する
# 変化率データだけもらう
df_sm_chg_netsales <- left_join(tmp_target, df) %>%
group_by(filename) %>%
filter(name.共通. == "tse-ed-t:ChangeInNetSales") %>%
distinct() %>%
filter(str_detect(contextref.共通., "Current"))
df_sm_chg_netsales$value = as.numeric(df_sm_chg_netsales$value)
df_sm_chg_netsales <- df_sm_chg_netsales %>% drop_na(value) %>%
mutate(SHOWN_NETSALES_RATE =
case_when(
sign == '-' ~ value * -1,
TRUE ~ value
)) %>%
select(filename, SHOWN_NETSALES_RATE)
df_sm_chg_opein <- left_join(tmp_target, df) %>%
group_by(filename) %>%
filter(name.共通. == "tse-ed-t:ChangeInOperatingIncome") %>%
distinct() %>%
filter(str_detect(contextref.共通., "Current"))
df_sm_chg_opein$value = as.numeric(df_sm_chg_opein$value)
df_sm_chg_opein <- df_sm_chg_opein %>% drop_na(value) %>%
mutate(SHOWN_OPEIN_RATE =
case_when(
sign == '-' ~ value * -1,
TRUE ~ value
)) %>%
select(filename, SHOWN_OPEIN_RATE)
df_sm_chg_odiin <- left_join(tmp_target, df) %>%
group_by(filename) %>%
filter(name.共通. == "tse-ed-t:ChangeInOrdinaryIncome") %>%
distinct() %>%
filter(str_detect(contextref.共通., "Current"))
df_sm_chg_odiin$value = as.numeric(df_sm_chg_odiin$value)
df_sm_chg_odiin <- df_sm_chg_odiin %>% drop_na(value) %>%
mutate(SHOWN_ODIIN_RATE =
case_when(
sign == '-' ~ value * -1,
TRUE ~ value
)) %>%
select(filename, SHOWN_ODIIN_RATE)
df_sm_chg_profit <- left_join(tmp_target, df) %>%
group_by(filename) %>%
filter(name.共通. == "tse-ed-t:ChangeInProfitAttributableToOwnersOfParent") %>%
distinct() %>%
filter(str_detect(contextref.共通., "Current"))
df_sm_chg_profit$value = as.numeric(df_sm_chg_profit$value)
df_sm_chg_profit <- df_sm_chg_profit %>% drop_na(value) %>%
mutate(SHOWN_PROFIT_RATE =
case_when(
sign == '-' ~ value * -1,
TRUE ~ value
)) %>%
select(filename, SHOWN_PROFIT_RATE)
df_sm_chg_ALL = full_join(df_sm_chg_netsales, df_sm_chg_opein) %>%
full_join(df_sm_chg_odiin) %>% full_join(df_sm_chg_profit)
scode_filename<- df %>%
select(filename, scode) %>%
distinct()
DF = full_join(df_sm_chg_ALL, target_sm_ALL) %>%
full_join(target_at_ALL) %>% left_join(scode_filename)
### サマリ(百万円単位)から推測される変化率と、
### 損益計算書(百万・千円単位混在)から推測される変化率を出す。
DF <- DF %>%
mutate(AS_SM_NETSALES = round(NETSALES_RATE, 1)) %>%
mutate(AS_SM_OPEIN = round(OPEIN_RATE, 1)) %>%
mutate(AS_SM_ODIIN = round(ODIIN_RATE, 1)) %>%
mutate(AS_SM_PROFIT = round(PROFIT_RATE, 1)) %>%
mutate(AS_AT_NETSALES = round(AT_NETSALES_RATE, 1)) %>%
mutate(AS_AT_OPEIN = round(AT_OPEIN_RATE, 1)) %>%
mutate(AS_AT_ODIIN = round(AT_ODIIN_RATE, 1)) %>%
mutate(AS_AT_PROFIT = round(AT_PROFIT_RATE, 1))
write.csv(DF, "tidyverse_calcuration_result.csv")…Rは便利な分、めちゃくちゃ多くのデータフレームを作ってしまいます。
検証結果
そもそも論ですが、企業が千円単位と百万円単位のどちらの財務数値で変化率を計算しているのを、1度の開示資料を見て判断するのは難しいことです。事業規模が大きな企業だと百万円単位未満切り捨てでも千円単位切り捨てでもあまり差が出ないからです。それでもやや違いが生まれてくることはあるのだと思います。
まず、百万円単位でしか損益計算書を開示していなかったのに、それよりも粒度の細かい単位(千円?)で増減率を計算していると思われる開示数は708件でした。
そこで、百万円単位で増減率を計算した場合と、実際に開示された増減率の差を計算・比較し、百万円単位以外で計算したほうが都合が良いケースと悪いケースを比較しました。
例えば、ある企業は決算短信サマリーと付属の損益計算書の両方は百万円単位で開示しているが、読者の知りえる百万円単位の数値による計算結果と決算短信サマリー表紙に開示された前年同期比の変化率に差があるとします。読者が手計算した結果、当期純利益が前年同期比4.0%増加したが、企業がサマリーの部分で開示した変化率が3.9%だった場合、「より見栄えが悪くなる」ケースとしています。

結果として、過半数が見栄えが悪くなるにも関わらず、百万円単位とは異なる数値で増減率を計算していることが分かりました。一方で、営業利益→経常利益→当期純利益、へと進むごとに数値の見栄えが良くなるケースが増えていることには注目すべきだと思います。
次は、損益計算書が千円単位で開示されているケースに注目します。
サマリー部分は百万円単位開示ですが、損益計算書は千円・百万円のどちらかの単位で開示されます。そこで、サマリーから百万円単位で前年同期比を計算するのと同時に千円単位で開示されている損益計算書からも前年同期比を計算し、企業がどちらの数値をサマリーの前年同期比(%)に採用しているのかを検証しました。

結果として、千円単位で数値を公表している場合は千円で増減率を計算していることが多いのが分かりました。一方で、ごくわずかに、敢えて百万円単位で計算しているケースが存在することも突き止めました。あえて百万円単位で開示している企業について具体例を見ると、下記のような開示でした。

損益計算書では134,906千円から221,338千円への増加、つまり64.068…%の増加になります。

一方で、サマリ部分では134百万円→221百万円、つまり64.925…%となります。ほとんどの企業で千円単位の増減率を使用している中でこの開示ではあえて百万円単位で計算を行い、結果として千円単位で計算した場合よりも0.8ポイント高く純利益が伸びたように見せることに成功しています。
結論
そもそも百万円単位で計算しようが千円単位で計算しようが、変化率に大きな差がでることはまずありません。その中でもわずかに差が生じることがあります。特に東証側はどちらの単位で計算せよ、という指示をだしていない(と思う)ので、今回は企業がどちらの単位で計算を行っているのか、また会社側は都合の良いほうの単位で開示をしているのかどうかまで検証しました。
結果として多くの企業が千円単位、言い換えれば粒度の高い数値で計算していることが示唆されました。百万円単位でしか財務数値を公表していない企業でも、より細かな数値で計算していることが示唆されましたし、なによりも、百万円単位で増減率を計算したほうが見栄えがいいのにも関わらず、ちゃんと粒度の低い数値で計算を行い、その結果を開示しているケースが多く存在することが分かりました。一方で、千円単位で増減率を計算している企業が多いにも関わらず、敢えて百万円単位で(しかも千円単位の財務数値を公表しているにも関わらず)増減率を計算し、ごくわずかですがミスリードにつながりかねない開示があったのもわかりました。こうした企業もあるので、投資家は財務諸表にも注目する必要がある一方、わざわざ見栄えの悪くなる千円単位で計算している正直者企業があることも忘れてはいけない、と思いました(小並感)。。。
付属として、検証に使用したファイルを置いておきます。
この記事が気に入ったらサポートをしてみませんか?