
データ活用、ChatGPT、学び直し…DXの重要トレンドを一気に解説した全10記事

はじめに
株式会社cross-Xの古嶋です。DX戦略立案・推進やデータ・AI活用の支援をしています。
2022年末より、ダイヤモンド・オンラインにて「DXの進化」と題し、全10回の連載を寄稿しました。
本連載では、DX戦略を構築するためのフレームワークの解説に始まり、課題解決のアプローチやITシステムの実装、AIモデルの構築、機械学習システムの開発など、DXの実務で必要となる観点を幅広く解説しています。
また、ChatGPTのような現在世界を席巻している技術や、DX人材・学び直しへの見解とあるべき方向性についても考察しています。
(なお、連載している記事については、ダイヤモンド・オンラインにて会員登録することで、全ての記事が無料でご覧頂けます。)
このnoteでは、これら10本の記事について「解説の解説」を書いていきたいと思います。
各回の記事が結構ボリュームのある内容となっているため、全体の概論を掴んでいただいたり、連載内容の背景理解となる”副読記事”として、本noteをお読み頂けると嬉しいです。
また、10回分の記事の解説をまとめているため、本noteはかなりボリュームが多くなっています。
ですので、以下の目次をご覧いただき、興味のあるところだけ読み進めるという使い方をして頂いても良いと思います。
それでは、御覧ください。
第1回:DXの成否を決定づける「データ利活用サイクル」
第1回目は、「データ利活用サイクル」についてです。
https://diamond.jp/articles/-/314934
私がDXの支援や拙著『DXの実務』(英治出版、2022年)で一貫して提言しているのは、下図で示しているデータ利活用のサイクルです。
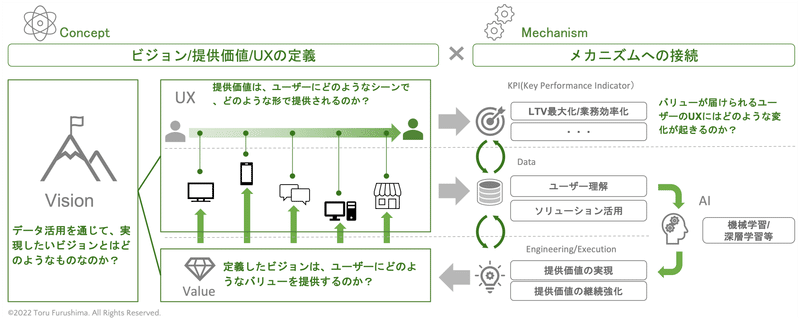
このサイクルは「戦略」と「技術」をつなぎ合わせたフレームワークとなっています。
まず、図表の左側の戦略の部分では、DXの「コンセプト」を構築します。
DXのビジョンを定め、そのビジョンが実現した世界では、どのような価値(Value)を提供し、どのような顧客体験(UX)が生まれているのかを明確化します。
次に、図表の右側の技術の部分では、戦略を技術に落とし込んだ際の「メカニズム」を言語化・可視化します。
さて、図の中には7つの重要な要素が含まれています。
以下に整理した①〜⑦の要素は、それぞれ分断・独立したものではなく、全てが繋がって連動し、全体の精度や効果が高まっていくサイクルを描くように働くことが不可欠です。

そもそもこのようなフレームワークを作った背景として、これまでのDXに関わる論考における、戦略と技術が分断していた状況への強い懸念がありました。
DXに関する企画は、ITやAIへの知見が無くても、野放図なアイデアや強い意見に引っ張られ、技術的考察を欠いた状態で作ってしまっているケースが良く見られます。
すると、実際の実務では想定していた要件の実装が難しかったり、そもそも実現困難なことが後から判明したりします。
にも関わらず、そのまま強引に進めると運用で想定以上の人員が必要となって現場が回らなくなったり、プロジェクトそのものが撤回されたりするなど、目も当てられない失敗となることも珍しくありません。
こういった考察の際にフレームワークを用いるメリットとしては、
MECE(漏れなく、ダブリなく)に考察ポイントやタスクを洗い出して整理できる
関係者全員の認識を揃え、個別・全体の活動の生産性を高められる
プロジェクト推進上で問題が生じた際のチェックを効率化し、PDCAを有効に機能させられる
といった点が挙げられると思います。
ただし、フレームワークを過信したり、その真意を理解しないまま使うと逆効果になるので十分注意が必要です。
第2回:DXにおける課題の発見と解決
今回のテーマは「課題の発見」です。
https://diamond.jp/articles/-/315829
長年この領域で仕事をしていると、常に世の中が揺れ動いている様子が、現場を通じて色濃く伺えます。
理性と感性、ロジックとデザイン、経営と現場、計画と実行・・・などなど、これらが対立概念なのかどうかは人それぞれの捉え方次第ですが、「どちらが重要か?」という比重が変わり続けているように思います。
この点、私の職業柄、「課題」というものにさまざまな角度から関わるのですが、ここでは「発見と解決」の間で、世の中が揺れ動いているなぁと感じます。

世間を賑わすサービスは何らかの課題を解決するためのもので、競争は常に「いかにして優れた解決策を生み出すか?」に終始センターピンが刺さっています。
ただ、現代は課題が減り続けている世の中であり、ここでより求められるのは課題を「発見する力」なのかな、と思います。
課題解決では、前提として既に課題が明確に存在していることになっています。
しかし、その課題が果たして課題と呼べるものなのか、本当に解くべき課題はどこにあるのか、といった思考は、実務では極めて重要です。
課題の発見によって世の中を大きく変えたものは、現在の商品・サービスを見渡せばたくさんあると思います。
例えば、
ウォークマン→iPod
ガラケー→iPhone
給湯器→瞬間湯沸かし器(T-falなど)
自動車→ビークルOS(TESLAなど)
コンビニ→無人店舗(Amazon Goなど)
決済システム→埋込み型決済(Stripe など)
などなど、挙げだせばキリがないところですが、こういった新たなソリューションは課題「解決」型のアプローチでは、恐らく生まれてこないでしょう。
「手持ちの技術で何とか良いものが作れないか」とか、「この問題を解決するにはどうすればよいか」といった“閉じた”思考様式ではなく、
「何が課題なのか」という視点を常に持ちながら、世の中を見渡し続ける意識と行動が重要です。
一方、この課題の「発見の仕方」に、さも万能なアプローチがあるかのような論考は、無駄の一言で一蹴すべきでしょう。
昨今は何でもフレームワークや方法論に落とし込んだものがウケが良いように見受けられますが、思考への「負荷」を下げようという意識は、思考力そのものを閉ざしていく危険性を必然的に伴うため、今すぐ捨て去るべきでしょう。
重要なのは、自分の力で情報を集め、考え、行動し続けることに尽きるのかなと思います。
…と、こんなことを言いつつ、その課題の発見のためのなんらかの役立つアプローチはあるかな、と思っています。
もちろん、それが万能などとは毛頭考えていませんが、課題の発見のために辿るべきいくつかのステップがあるのかなと、経験的に思っています。
第2回目の記事は、そんなことを考えながら書きました。宜しければご覧ください。
第3回:DX実現へのロードマップ
今回の内容は「DXのロードマップ」…難しいテーマです。
https://diamond.jp/articles/-/316170
そもそも論として、「DX」と「ロードマップ」は、相性最悪だと思います。計画的に仕事を進めるという考え方そのものと、相性が悪い。
にもかかわらず、DXではロードマップが至る所で量産されています。
なぜ、相性が悪いのか?
パッと思いつくところで、ポイントは2つ。
1つ目は、世の中の変化が激しすぎて、市場環境の見通しが立ちづらい中、計画通りに進めることが最良の策とは言い難い、ということです。
例えば、革命的なAIとして世間を賑わしているChatGPTの台頭を、半年前に予見出来ていたかというと、大多数は気づきもしなかったのではないかと思います。
革新的な技術の登場で一気に市場環境や競争優位性が激変する世界では、ロードマップのような計画重視のアプローチを従来どおりの慣性で進めることは、端的に言って大きなリスクだと思います。
また、ロードマップというものが経営全体に影響を与える位置づけである以上、影響範囲が殊更大きく、大いに再考の余地がある経営管理手法だと思います。

2つ目は、そもそもDX的なソリューションの実装が計画的な実務推進と馴染まないという点があると思います。
例えば、機械学習システムの開発・活用は、その成果は「やってみないと分からない」ものであり、計画的に効果を高め続けることを誰も保証出来ないことは既に周知の事実かと思います。
これを従来のITシステムのようにカチッと要件通りに動くものと考えてしまうと、ウォーターフォール型の考え方がそのまま踏襲されてしまいがちです。
上記2点以外にも色々と思うことはありますが、では、ロードマップに代替するアプローチとして、どのような手法を採用すべきか。
ここは、「小さく始めて、大きく育て、ビジョンに近づいていく」の一言に尽きると思います。
そもそも計画という手段を用いる理由は、会社のビジョンの実現です。
その実現が計画的に進めづらいことが明らかなのであれば、ビジョンに向かった仕事の進め方そのものを変えるしかありません。
(一方、「小さく始めて、大きく育てる」という部分の根拠は、次回以降の連載で詳述しているので割愛します。)
ロードマップという考え方を、この「育て方」という言葉に置き換えていきませんか?というのが、私が常々発信していることです。
そうすると、自ずと「ビジョン」の言語化や可視化がより一層重要になります。
また、何を育てるべきかを知るために、市場環境や競合他社の事例、関連技術、先端技術の理解により一層向き合う必要があります。
DXの実務の中では、成功よりも失敗が遥かに多いと思います。
そんな中でも「こうなっていきたい」というビジョンが組織全体で浸透し、そのテーマに沿って各種プロジェクトが創発的に生まれて、少しずつ歩みを進め、ビジョン実現に近づいていくことが、今風な「ロードマップ」なのかなと思います。
もちろん、このような経営的合意が取りづらいことは重々承知しています。
つらつらと書きましたが、第3回の記事は、そんなことを考えながら執筆しました。宜しければご一読ください。
第4回:DXを推進するための「フレームワーク」
連載第4回目のテーマは「フレームワーク」です
https://diamond.jp/articles/-/316538
世界的ベストセラー『ファクトフルネス』には、「パターン化」について警鐘を鳴らしている節があります。
ほんと仰る通りで、無闇なパターン化は、無思考の状態で分類した結果を”正しいもの”のように錯覚してしまう危うさがあります。
フレームワークなんてものは、そのパターン化の最たるものの一つです。
なので、その功罪の両面を知っておくことが重要だと、若い頃さんざん叩き込まれてきました。
ただ、このDXの分野では、パターン化をしておくことが理解を助けるシーンが多々あるのでは?と思っています。
そして、おそらくDXではこれが大変なのですが、獲得したパターンを常にアップデートし続ける必要があると思っています。
例えば、昨今世間を賑わせているChatGPTは、Transformerという技術をベースに開発されたものです。
OpenAI:
Transformer:
しかし、このTransformerという技術は、それ以前から存在したCNNやRNNといった深層学習モデルと、一体なにが違うのか?
CNN:
RNN:
言い換えれば、なぜ、CNNやRNNではChatGPTを生み出すことが出来なかったのか?
…こういった問いは、DXの分野ではめちゃくちゃ多いと思います。
こういった考察をする際、双方の「共通点」と「相違点」を見分けることが第一歩だと思います。
そして、この「共通点」と「相違点」を見分けられるかどうかは、「何らかの”パターン“を見抜き、そのパターンを軸にして考える」ということが出来なければ、恐らく無理でしょう。
それ以外の方法は、ちょっと思い当たりません。
やや専門的な話ですが、例えばCNNの精度を飛躍的に向上させたResNetという深層学習モデルでは「スキップ接続」という手法を用いていますが、これはTransformerでもエンコーダーのステップで当然のように採用されています。スキップ接続とは、深層学習モデルで課題となる勾配消失問題を解消する手法です。
ResNet:
勾配消失問題:
つまり、この「スキップ接続」を採用している点は「共通」していると言えます。
一方、深層学習で重要な役割を果たす活性化関数では、ResNetではReLUを用いてますが、TransformerではGELUを用いています。
活性化関数:
この点、活性化関数として「使っている関数」は相違しますが、活性化関数を「使う」ということ自体は共通しています。
新しいアイデアや技術が台頭した際、「今までと何が同じで、何が違うのか」ということが考えられるかどうかは、このパターンの「引き出し」をどのくらい持っているかどうかだと思います。
さらに、そのパターンがすぐに陳腐化することを承知のうえで常にインプットを続け、無数のパターンを同時並行でアップデートしていくことが重要なのかなと思います。
DXの分野では、新しい技術の台頭で、突如としてこれまでの知識が陳腐化することが珍しくないため、これまでの考え方を変えたり、場合によっては捨てなければならないシーンと遭遇します。
そのとき、守りに入らず、いかに攻めの姿勢で自分自身をアップデート出来るかが、相当重要なのではないかと最近強く思います。
このインプットとアップデートが大変だなぁと日々感じています。
パターンを軸にすること無しに比較すると、何だか思いつきで場当たり的な指摘合戦になっちゃいますし、そのパターン自体が古かったり怪しかったりすると、目も当てられない状況になってしまう…。
今回の記事は、そんなことを考えながら、自戒の念を込めて書きました。
よろしければご覧ください。
第5回:DXの難易度を左右する3つの要素
全10回の連載も、いよいよ折返しです。
今回のテーマは「DXの難易度を決める3つの要素」についてです。
https://diamond.jp/articles/-/316901
数年前、Google出身の友人と会話している際に「優秀なエンジニアとはどういう人を指すのだろうか?」という話題で盛り上がったことがあります。
色々な視点はありますが、友人曰く「結局、難しい問題を簡単な問題に分解・帰着させられるエンジニアは、やっぱり優秀だよね」とのことでした。

この「簡単な問題に分解する」という思考プロセスは、まさにロジカルシンキングが要求されるところです。
しかし、DXでは特にこの「分解」という作業が不十分なケースを非常によく見かけます。
例えば、「DXとは何か?」というテーマが議論されているところで、「ITシステムを導入するだけではダメで、変革を生み出すことがDXだ」という主張をよく見かけます。
さも正論を言っているように見えますが、私からすると「あ、また問題を『分解』出来てない」と思ってしまいます。
「変革を生み出すことがDXだ」という考えでは、設定された問題を簡単にするどころか、余計に難しくしてしまっています。
私としては、そのような意見に価値があるとはあまり思えません。
変革という言葉の定義にもよりますが、DXとはそもそもデータやAIを活用するものであり、であれば自ずとITシステムの導入は大前提となるでしょう。
そのステップを軽視しているかのような見解に基づいてプロジェクトを主導すると、多くのケースで現場は混乱します。
というか、混乱している状況を多く見てきました。
ITシステムの導入だって、十分過ぎるほどの「変革」です。
なぜなら、これまでの業務を一部「システムに置き換える」という作業だけでも、膨大な労力と変更プロセスが求められるからです。
ITシステムは、人の言うことを聞いてくれるわけではなく、あらかじめ指定されたタスクを処理するだけです。
すると、人間側もある程度はシステムの仕様に合わせた業務スタイルに変更しなければならないでしょう。
つまり、これまでのやり方を「変化」させる必要があります。
DXには”Transform”の意味合いが込められていますが、この変革を実現する前に、「変化」しなければならないポイントが多数存在します。
これらを1個ずつ変えていかなければ、変革には届かない。「変革」と「変化」では、意味が全く違います。
では、変化させるべきポイントをどのように見極めるか?…これが、DXの課題解決における「難しい問題を分解する」ための第一歩です。
この「分解」の粒度が粗かったり漏れていたりすると、後からさまざまな問題が生じます。
ただ、DXの性質上、プロジェクトの影響範囲の広さやIT、AI活用で要求される専門性、未経験領域への挑戦など、問題を「分解」するには多彩なスキル・ノウハウが求められます。
よって、この「分解」というタスクそのものが困難となるのは仕方ないことであり、座学や実践を通じて学び続けたいところです。
一方、問題なのはこういった状況に対して「無自覚」であることだと思います。
なんとなくトレンドに引っ張られたり、変革といった言葉に浮足立ってDXに関わっていると、多くの関係者を疲弊させてしまうことになるでしょう。
この点、翻弄されて疲弊した経験のある方も、今となっては少なくないのではないでしょうか。
…と、この領域に身を置く立場としてはそうならないよう、自己研鑽に励み続けなければならないなぁと、自戒の念を込めて本稿を書きました。
よろしければご覧ください。
第6回:DXの具体的実務:KPIの落とし込み
今回のテーマは「DXの実務とKPI」についてです。
https://diamond.jp/articles/-/317215
KPI設計と運用は、私自身キャリアを通じてかなり深く関わってきました。
コンサル会社ではクライアント企業のKPI設計、事業会社では自分たち自身のKPI設計と運用、という形で関わってましたが、どちらかというと、やはり後者の方が大変でした。
KPIに関する論考は書籍やメディアで多数紹介されていて、ここで改めて語るようなことはないかなと思いつつも、経験上、結局これに尽きるかなぁということを備忘までに書いておきたいと思います。

仕事は何でもそうだと思いますが、その目標や業務内容について、「管理が可能かどうか」が全てなんじゃないかなと思います。
逆の言い方をすれば、「不確実な要素をどれだけ取り除けるか」ですね。
運任せのようなKPI設計になっている状態って、結構多いと思います。
それだと、担当者がどれだけ頑張っても成果が出るかどうか分かりませんし、目標未達になると経営と現場の間に不和が生まれやすい。
経営からすると、「ちゃんと仕事してんのか」ですし、現場からすると、「だから前から無理って言ってたじゃん」みたいな状態ですね。
もう一つ、そのKPIを達成したら「誰が嬉しいのか?」という点は、チームのモチベーションにめちゃくちゃ影響すると思います。
目標を達成して嬉しいのが経営層だけだと、現場では「働かされている」という不満が蔓延します。
そしてそのしわ寄せは、時間の経過とともに事業責任者にやってきます。それが結局は、決算説明の場にも大きく影響します。
この点、キャリアの多様化がスタンダードになってきている世の中では、ただやらされているだけで成長を感じられない業務は益々魅力を失っていくと思います。
担当するKPIによって、おおよそやるべきことは決まってしまいます。
つまり、KPIは各担当者のキャリアを決めてしまうほどの影響力を持った経営指標だということかなと思います。
昨今、リスキリングが話題となっていますが、このKPIをめぐる業務推進は、仕事のノウハウが集約された活動だと思います。
特に、DXの実務ではデータ起点で細かなKPIを高速でPDCAを回す活動が行われるため、従来型の業務よりも高いレベルでのKPI管理が求められてしまいます。
私自身、DXの領域でKPI設計を実際に行って事業・組織管理するなかで、たくさんの経験や学びを得られました。
普段の業務を見直すきっかけもたくさんありました。
失敗するパターンも、そこから挽回する方法も身を以て経験しました。
・・・さて、前置きが長くなりましたが、このような記事を出しておいてこんなことを言うのも変ですが、KPIに関しては「経験から学ぶ」が最良の方法だと思います。
いろいろな書籍、媒体などに情報が溢れている中、それらにザザッと目を通したなら、まずは「やってみる」ことが一番かなと思います。
公開されている情報ではカバーしきれないことが、KPIの設計と運用には現れてきます。
逆に、経験してしまえば相当大きな「強み」になるんじゃないかな、と思います。
皆さんの「やってみる」の一助に、少しでもなれれば幸いです。
宜しければご覧ください。
第7回:DXの具体的実務:AI活用に向けたデータ基盤の構築
今回のテーマは「AI活用に向けたデータ基盤の構築」についてです。
https://diamond.jp/articles/-/317676
データ活用の議論になると、ITシステムにおける「攻め」と「守り」の考え方が対立する様子をよく見かけます。

例えば、事業開発やマーケティングなど、数値責任を持って主体的に成果創出を目指す組織では、データは活用したい資産であり、そのために必要なシステム開発を推進したい。
一方、セキュリティ保護やシステムエラー防止を担う情報システム部や開発チームは、システム変更による影響範囲を見積もったり、機能実装に必要なデータの活用に伴う個人情報保護の対応など、新しい取り組みは慎重に進めたい。
こういった牽制関係は組織において重要である一方、バランスが崩れると、「攻め」が強すぎれば事業リスクの増大、「守り」が強すぎれば開発全体の停滞を生むなど、大きな弊害を生んでしまいます。
この点、AIにおけるデータ基盤は、その内部に「攻め」と「守り」の概念が同居するようなシステムです。
データサイエンティストや機械学習エンジニアとしては、新しい予測モデルを開発したり、モデルを再学習後速やかにデプロイしたり、新しい特徴量を作り出してそれを試したりと、実験的に素早く実務を進めたい。
専門的に言えば、速いイテレーションで試行錯誤して実務を進めたい、ということですが、その内容や変更履歴を記録保存したり、他者が読みやすかったり再利用しやすいようなコーディングは、やや優先度が下がる傾向にあります。
一方、データ基盤やフロントエンドなどを担当するエンジニアは、データの形式変更や新しいバージョンのモデル実装によってITシステム全体にどのような影響があるかを慎重に検討したい。
特に、予測モデルが実装された後、システム全体が壊れることなく安定的に稼働して期待どおりの成果を発揮するように、システム全体を制御することの優先度が高い傾向にあります。
他にも数多くの考察ポイントがありますが、重要なのは、
「従来型のITシステムの考え方と、AIやデータ分析を含めたITシステムの考え方は、かなり異なるものと考えた方が良い」
ということです。
この点、開発側に依頼する事業側・経営側が、このような状況を理解しない、もしくは知らないまま計画を提示、管理していると、開発側の実務推進上のストレスは更に高まります。
DXには多様な組織や人材が求められる、とよく言われます。ただ、多様な人材が集まったとしても、組織間やメンバー間で上記のような状況に陥っていると、逆効果です。
一方、相互理解が組織間、メンバー間で形成されたとしても、役割の異なる相手が「どのような実務をしているか」が分からなければ、先述したような問題は解決しないと思います。
DXの実務では想定外の問題がつきものですが、その内容がITやAIなどの専門的な内容だとしても、その内容をある程度理解しておかないと、何かが起きたときに手の打ちようがないことになってしまいます。
分からない問題は、解決できないですからね。
また、データやAIを活用すると、多くの関係者が多様なタスクを同時並行で進めることになります。
そこでは、個々のタスクについて専門スキルを持った人材を適材適所で配置し、実務を推進していくことになります。
この点、一見すると効率的なように見えますが、実はそうではないケースが多い。
よく見かけるのは、「そこは違う部署のあの人が担当だから、自分は知らない」といったスタンスです。
このような意識と役割分担は、効率的なように見えて、実は活動を妨げることになりがちです。
専門化が進むほど実務はブラックボックスになりがちですが、DXは「個々の活動を繋ぎ合わせて成果を出すもの」なので、個々の実務が分からないままだと成果を出すことは難しいと思います。
重要なのは、ミッションや立ち位置の異なるメンバー間で双方の考え方を理解するだけでなく、相手の実務や専門的な内容に少しでも踏み込んで理解することです。
この点、昨今よく言われる「リスキリング」は、その定義も意味合いもさまざまなようですが、
「他のメンバーの実務を理解するための技術的リテラシーを高め、チームワークをより高度なレベルで発揮するためのものだ」
という側面もある気がします。
上記のような点で悩む方々にとって少しでも役に立てばと、今回の記事を書きました。
よろしければぜひ御覧ください。
第8回:AIモデルとDX
今回のテーマは「AIモデルとDX」です。
https://diamond.jp/articles/-/317874
今回の記事では、「数学の重要性」について私の実体験も踏まえて書いています。
その話題に触れる前に、昨今の技術トレンドについて簡単に私見を書いていきます。
GPT-nシリーズやDiffusion Modelなど、昨今はAI関連で非常に強力な技術が誕生し、世間を賑わせています。
こういった革新的な技術は、突如表れて世間を驚かせるといったものではなく、歴史的(といっても過去10年程度を遡った考察)に考えれば、このような変化はある程度“読める”ものだと思います。
今から10年程前の2013年〜2014年頃、深層学習モデルの抱えていた主な課題の一つは「大規模なモデル設計に伴う膨大なパラメータに、いかにして対応するか」でした。
そもそも深層学習モデルは、線形の関数では表せない複雑な事象に対し、複雑な非線形関数によって関数近似を実現するという数理モデルのアプローチです。
複雑とは、簡単に言えば「表現力」のことで、パッと見ただけでよくわからないデータの傾向に対しても、非線形な関数を適用して対応するということです。
そして、この複雑性が高いほど、予測結果の精度が高まってきたというのが、深層学習モデルが歩んできた歴史です。
しかし、その過程でぶつかってきた課題の一つが、上記の「膨大なパラメータへの対応」です。
深層学習モデルの複雑性を高める主なアプローチは、層を増やすことです。層を増やして演算を繰り返すほど、関数は複雑になります。
しかし、層を増やせば当然ながら計算量が飛躍的に増加するだけでなく、学習するパラメータ数も跳ね上がります。
言い換えれば、AIを学習させるための学習量が跳ね上がるということです。
この課題を見事に克服し、当時画像認識モデルの精度を競っていたILSVRCで驚異的な精度を示したのが、2015年に登場したResNetというモデルです。
このモデルでは、層を増やして精度を高めることと、学習量を抑制して精度を出すという、これまでトレードオフだと考えられていたことを同時的に克服しました。
厳密には、その前年でILSVRCで1位となったGoogLeNetや、さらにその前年で1位となったAlexNetでも同様の試みを行い、成果を出しているのですが、目覚ましい成果を発揮したのはResNetです。
そして時代は移り変わり(といっても5年程度しか経っていませんが)、GPT-nシリーズが誕生しました。これはTransformerをベースとした技術であり、GPT→GPT-2→GPT-3と、シリーズを経るごとにモデルの複雑性と学習データ量が大幅に増加しています。
GPT-nシリーズには特筆すべき面白い特徴がたくさんありますが、「学習量を減らす」というアプローチでは、GPT-3で採用されているSparse Transformerがあります。
これは、Transformerの最大の特徴と言えるMulti-Head Attention部分の学習をSparse(疎)にするための工夫を行った、ということです。
ちょっと専門的過ぎる考察ですが、要するに「学習量を減らすための工夫をした」ということです。
こういった経緯を見ていると、深層学習モデルの進化のための本質的な着眼点は、実は旧世代のモデルと変わってない部分もたくさんあると言えます。
一方で、大きく変化した部分もあります。例えば、旧来型のモデルの学習では膨大な「教師データ」が必要でしたが、GPT-2では「教師なしデータ」のみで、複数のテーマで当時のSOTA(State-of-the-Art: ある特定の技術領域で最高性能だという意味)を出してしまうという驚異的な結果を示しました。
教師データの準備のためには膨大なデータ量に対して「人の手で」ラベリングするような地道とも過酷とも呼べる作業が必要でしたが、大規模な言語モデルではそのようなことが不要になってしまった、ということです。
AIのこれまでの歴史を考えると、驚愕の出来事だったのではないかと思います。
層の数やパラメータ数によるボトルネックが大幅に解消されつつある現在、GPT-nシリーズが現在追い求めているのは、より巨大な言語モデルを構築してさらに大量のデータを学習させ、より高精度なAIを生み出す、ということが基本路線のように見受けられます。
この点だけを考えれば、非常にシンプルなアプローチと言えます。
AIの歴史を遡り、現代までの経緯を紐解いていくと、人間がAIを生み出すために繰り広げてきた“格闘”のようなものが垣間見えます。
この過程を読み解く中で、最先端の技術者が革新的な技術を生み出す際に、当時どういった姿勢で、どのくらい突き詰めて仕事と向き合っていたか、非常に多くの示唆や学びを得られると個人的に思います。
さて、だいぶ前置きが長くなりましたが、今回寄稿した記事では、「数学の重要性」について、私の実体験も踏まえて書いています。
昨今、学び直しやリスキリングが話題となっていて、その中のテーマの一つに「数学」が挙げられることも多いと思います。
そこで私がいつも密かに思っているのは、数学は「必要だから学ぶ」というよりも、「視野が広がり、景色が豊かになるから学んだ方が“おトク”だ」というものなのかなと思います。
数学が分かれば、社内でどのようなAIを採用するべきか検討する際も、昨今の技術の核心部分を理解する際も、非常に強力な武器となります。
数学が分かるだけで、特に現代は、見える景色が大きく変わると思います。
私事でちょっとだけ宣伝ですが、実は来年、数学に関する書籍を出版予定で、目下執筆中です。
その書籍で、「視野が広がり、景色が豊かになる」ような内容を作れたら、と妄想しています。
そんなこともあり、今回の記事は個人的に思い入れのある内容となっています。
よろしければぜひ御覧ください。
第9回:機械学習システムとDX
今回のテーマは「機械学習システムとDX」です。
https://diamond.jp/articles/-/318563
前回第8回の「AIモデル」に続き、今回は「機械学習システム」をテーマにしています。
この2回を通じて、AIをより身近に感じて頂けたらと思いつつ、できる限り丁寧に書きました。
ここで、本稿執筆の背景を少し書かせてください。

Open AIがいよいよChatGPTのAPI提供を発表しました。
併せてWhisperのAPIも提供を発表しています。
Whisperとは、Open AIが開発した汎用的かつ高精度の音声認識モデルです。これまでのOpen AI APIで提供していた大規模言語モデルのバージョンはGPT-3でしたが、今回ようやくChatGPTで採用されているGPT-3.5-turboがAPIを通じて利用可能になりました。
利用料も破格の安さです。
こういった高精度AIのAPIが誰でも利用可能になるという流れは、今後も加速していくと思います。同時に、DXの領域において大きな“転換点”となると思います。
機械学習システムの競争優位性の最たるものは、つまるところ「精度」に帰着すると思います。
つまり、予測結果がどのくらい妥当かが、機械学習システムの優劣を大きく左右します。
その精度を左右するのは、機械学習システムの中核とも言えるAIモデルです。
すると、精度で他のAIに劣ると、ユーザーからすると精度の低いAIを利用する価値は無い、と結論づけても仕方のないことです。
よって、ユーザーは精度が少しでも高いAIを選択することになります。
この点、ChatGPTに類する他の対話型AIは、「ChatGPTに精度で勝てるか?」が競争優位性を評価する重要な指標になってしまいます。
もちろん、特定ドメインを土俵にして優劣を評価すれば勝てる可能性もありますが、現状のトレンドを見る限り、劣勢となることが想定されます。
上記のリリースの通り、ChatGPTで用いられている大規模言語モデルが誰でも利用可能になってしまうと、もはやこれを使う以外の手はない、という状況になっていくと思います。
そもそも、機械学習システムの開発と運用では、広範囲にわたる技術要素を総動員して開発・運用を進めるという難しさがあります。
例えば、予測精度向上のための特徴量エンジニアリングや、AIモデルの継続的な訓練・評価、ユーザー体験を高めるためのUI改善、大規模なデータの利用を可能にするためのデータ基盤構築と保守・運用体制の整備など、です。
さらに、AIモデルは「作ってみなければ上手くいくか分からない」というクリティカルな実務課題があります。
であれば、最初から高精度が保障されているAIモデルのAPIを使う方が利点が多い、という判断も妥当だと個人的に思います。
UIの強化など、他の開発に集中できるというメリットも享受できます。
そういった、「イチから開発しなくても、これを使えば良い」という高精度AIが、これからどんどん世に放たれていきます。
すると、イチからシステム全体を作り上げるのではなく、APIを用いて外部のAIモデルを活用するというアプローチが、今後はかなり増えていきます。
これは、既存の各社の開発戦略に決定的に影響するでしょう。
となると、高精度のAIを開発できるかどうかよりも、
課題解決のための手段として、アクセス可能なAIを縦横無尽に利活用できるような人材が、今後は活躍するのではないか?
と想像します。
もちろん、その人材にはビジネス課題だけでなく各種AIの特性や技術面を、自ら作ることは出来なくとも、ある程度熟知していることが求められそうです。
その一貫として、そもそも機械学習システムが全体としてどのような仕組みになっているかを知ることは、すごく有意義なことだと個人的に思います。
AIによる世の中の進化が著しい昨今ですが、本稿をきっかけに、AIを少しでも身近なものに感じて頂ければ幸いです。
よろしければぜひ御覧ください。
第10回:DXの実務を推進する組織と人材
最後のテーマは「DX人材について」です。
https://diamond.jp/articles/-/319000
…このテーマには強い”思い入れ”もあり、少し長めの記事となりました。

昨今、DX人材の育成やリスキリングなど、DX人材をめぐって組織論やキャリア論の分野で様々な論考が各種メディアやプレスリリース等で飛び交っています。
ただ、その中で強く違和感を持つ部分があり、本稿では、昨今のDX人材に関する議論や動向に対して、やや強めに問題提起しています。
これまで寄稿してきた中でも何度か触れていますが、そもそもDXは「計画的に進める」というスタイルと極めて相性が悪いと言えます。
例えば、昨今はChatGPTの出現によって大規模言語モデル(LLM)が一躍脚光を浴び、AIによる変革の時代が本格的に到来した、と言える状況です。
このマクロ的な変化に対しては、何かしらの策を講じなければ大きなリスクとなることは間違いないと思います。
しかし、ここで多くの企業では、これまで積み上げた活動が機会損失になることを躊躇し、各種計画の変更に踏み切れない場面が想像されます。
また、AIは計画的に、期限までに目標の成果に到達できるものではなく、試行錯誤を繰り返しながら取り組みを進め、それでも成果が出るかは分からないものです。
テーマや難易度にもよりますが、AIを作るとは、その原理を踏まえるとそういうものだと考えるしかありません。
こういった例に限らず、そもそもDXは、計画的に成果を達成するプロセスを実現することが、極めて困難な領域だと私は考えています。
そんな中で、昨今盛り上がっている「DX人材育成」や「学び直し・リスキリング」は、
あたかも計画的に特定のテーマを学んでいけば、組織やキャリアにおいて成果が出せることを謳っているように見受けられます。
ここに、私は強く違和感を覚えます。
少し前に“VUCA”という言葉が流行りました。
これはVolatility・Uncertainty・Complexity・Ambiguityの
頭文字を取った、現在の世の中を表現した造語ですが、この状況は変わらないどころか、加速しているのが昨今だと思います。
そんな中で、「これを学べば良い」といったテーマを定め、計画的に育成を進めていくという施策は、遅かれ早かれ、トレンドとのギャップを生み出す遠因となります。
もちろん、各種育成コンテンツを提供して学びの機会を作ること自体は欠かせないと思います。
特に日本では諸外国と比べて育成への投資が少ないことは、各種調査で明らかになっている通りであり、この傾向は歓迎すべきであることは確かです。
ただ、この育成投資に何らかの理屈が働き、計画重視に傾倒してしまうと後々に弊害が起きる可能性が高い、というのが私の強い主張です。
こういった点を考慮すると、現代では、「何が重要なのか?」を見抜く審美眼と、何でもトライしてみるフットワークの軽さが、組織・個人の双方で、ますます重要になってくると思います。
DXの実務では、特にこのフットワークの軽さが大切だと実感するシーンが、個人的に多々あります。
今年はこれまで以上に世の中の激しい変化が予想されるので、私としては、この変化を楽しみながら、新しい領域やテーマに対して常に柔軟なフットワークで、挑戦していきたいと思います。
今回の連載で、私自身、これまでの経験の棚卸しができ、気持ちを新たにする機会を頂けました。
末筆ではございますが、今回の連載の機会を頂いたダイヤモンド社様には、この場をお借りして、改めて御礼を申し上げます。
本連載がDXの実務に関わる方々にとって、少しでもお役に立てれば幸いです。
よろしければぜひ御覧ください。
おわりに
ここまでご覧頂き、ありがとうございました。
本noteが少しでもお役に立てれば幸いです。
また、noteにてDX組織がフェーズごとに直面する典型的な課題とその解決策について以下のnoteにまとめています。
いずれも長編となっていますが、何かしら役に立つ情報をご提供できれば幸いです。
この記事が気に入ったらサポートをしてみませんか?