
chatGPTを見ていて、AIの推論と人間の知識の習得が似てるかも?と感じた話

こんばんは、ろろいです。年度末最終週を終えて無事に4月になりました。皆まいかがお過ごしでしょうか。
先日知人と自分のやりたい研究領域についてあれこれ話す機会があったので、そこから少しAIのことや話題のchatGPTについても調べ直していたのですが、それらを調べていく過程で「AIの推論」と「自分の学習」が似ているかもということに気づきました。
学習と理解
突然ですが、皆さんは何かを学習するとき、どのようにして学びますか。あるいはどうやって学んだことが理解できていることを確認していますか。非常に難しい問いですし、様々な方法があります。
私も「理解している」ということをどうやって確認するかはわかりませんし、一方で「理解していないと思っている」のに実際に問われると何故か話せてしまうようなこともあったりします。これがとても不思議でした。一方で「理解していないがアウトプットを出せる」というところがAIと似ているのではないかということを感じたのが大きなヒントであり、この記事を書くきっかけになりました。
AIの推論モデル
ここでAIの推論モデルやプロセスについて少し学んでおきましょう。
AIの推論モデルは、機械学習を用いてデータから知識やパターンを抽出し、新しいデータに対して予測や分類を行う仕組みです。訓練データと呼ばれる既知のデータセットを使って、AIはパターンや関連性を学習します。学習が完了したら、推論モデルは未知のデータに対して適切な予測や判断を行うことができます。
推論モデルにはさまざまな種類があり、ディープラーニングや決定木、サポートベクターマシンなどが代表的な手法です。それぞれの手法は、データの特性や問題の複雑さに応じて選択されます。
またAIがどのように回答を導き出しているかについては次のとおりです。
AIが質問に回答する際のプロセスは、主に次のステップで構成されます。
テキスト解析: まず、質問を自然言語処理(NLP)技術を用いて解析します。これにより、質問の文法や意味、重要なキーワードやフレーズが抽出されます。
情報検索: 次に、AIは質問に関連する情報や知識をデータベースやインターネットから検索します。このステップでは、検索エンジンや知識グラフなどの技術が使用されます。
情報評価: AIは検索された情報を評価し、質問に対する最適な回答を見つけ出すために、関連性や信頼性を判断します。これには、情報源の評判や権威性、情報の新鮮度や一貫性などが考慮されます。
回答生成: 評価された情報をもとに、AIは自然言語生成(NLG)技術を使って回答を生成します。この過程では、適切な文法や表現を用いて、人間が理解しやすい形で回答が構築されます。
回答評価: 最後に、生成された回答が適切かどうかを評価します。これには、文脈や一貫性、情報の正確さなどが考慮されます。評価結果に基づいて、AIは回答を最適化し、ユーザーに提供します。
AIはなにか問われたことを回答するときに意味を理解しているわけではなく、自然言語処理によって重要なキーワードやフレーズを導き出し、その質問に関係する情報を取得します。※chatGPTの場合は情報検索の項目のところがデータセットからの抽出でしょうか
情報の関連性によって質問に対して「もっともらしい答え=回答として確率の高いもの」を返しているというわけです。
知らないことを、相手に説明できる
私は10歳に満たないくらいのときからYahooやGoogleで検索をするという経験をしており、まだ一般家庭にコンピュータが普及しきっていない時代からinfoseekやgooなどもあれこれ使うヘビーユーザーでした。知らないことをとにかくたくさんしらべて情報を得る経験はこの時代に養われたと言っても過言ではありません。
また、あまり自覚はなかったのですが社会に出てみると「検索できない人」がいるということを知りました。他の人が1時間検索してもたどり着けないものが、私が検索すると30秒で見つかるなど、「検索にもスキルがあるんだな」と気づきました。
27歳くらいのときだったと思うのですが、知人が電話で相談をしてきました。「このサイトに書いてあることが理解できないんだけど」ということで電話してきたようです。送ってもらったURLの内容は初見のもので知らない内容だったのですが、サイトの中の関連しそうなキーワードを検索して類似のページを2~3つ見たあと、なんとなく関係性がわかったことから、まとまった情報を相手がわかりやすいように整理して口頭で伝えました。
言葉はあまり覚えていないのですが、知人の反応は「え、めちゃわかりやすいんだけど」というようなもので、それまで全く理解できなかったことがすぐに理解できたようでした。
この経験は「自分もよくわかっていないことを相手に説明できる」という不思議な体験として自分の中に残っています。これまで「なぜそれがわかったのか」ということについて説明ができなかったのですが、上記で太文字にした部分はまさにchatGPTとそれを通じて多くの人が感じていることにほかならないと気づきました。
AIの創発
少し前にニュースになっていたことでもありますが、大規模言語モデル(LLM)は規模が大きくなるほどパフォーマンスが上がり、更に複雑な推論ができるようになるということがわかっています。以下はGigazineさんからの引用です。
大規模言語モデルは規模が大きくなるほど、必要な演算リソースは増えるものの、より複雑な推論をこなすことが可能になり、文章生成の精度が上がるとされています。これまでは規模が大きくなることで既知のタスクパフォーマンスが向上すると思われていましたが、それだけではなく「これまで不可能だと思われていたタスクも処理できることがある」ということが明らかになっています。ただし、こうしたAIの創発がなぜ起こっているのかは、AIの研究者や開発者にもまだわかっていません。
この現象を創発(Emergent)と読んでいて、別のサイトでは次のように説明しています。
以下、ai.googleblog.comより「Characterizing Emergent Phenomena in Large Language Models」の意訳です。元記事の投稿は2022年11月10日、Jason WeiさんとYi Tayさんによる投稿です。
創発(Emergent)とは日本語でも耳慣れない言葉ですが、人工知能関連の文脈で出てきた場合は、ある能力が突然開花する事です。
今回のお話は物凄く興味深いのです。例えば、人間の赤ちゃんも身体の成長と共に創発的に能力を開発していくわけではないですか?
立つ事、発声する事、言葉を使う事、相手と会話をする事、世界を意識する事、感情を持つ事などなど。何らかの急激な変化が起こる転換点があって、ある日、突然、能力が開花したように見えると。
人工知能も同じようにモデルのサイズを拡大する事で、創発的に能力が開発されていくのだとしたら、そう、ちょっと前に「意識を得た人工知能」として話題になったLaMDAのお話をどうしても思い出すのです。
以下の画像は論文の中で登場しているグラフですが、左のグラフが複数の計算が求められるような問題、中央のグラフが大学レベルの試験問題、右が文脈から単語の意味を推定する問題で、Y軸は正確さを表しています。
グラフからも読み取れるのですが、10の22乗(1垓)から10の24乗(1杼)の間で急激にスコアが上がっていることがわかります。まさに「創発」です。
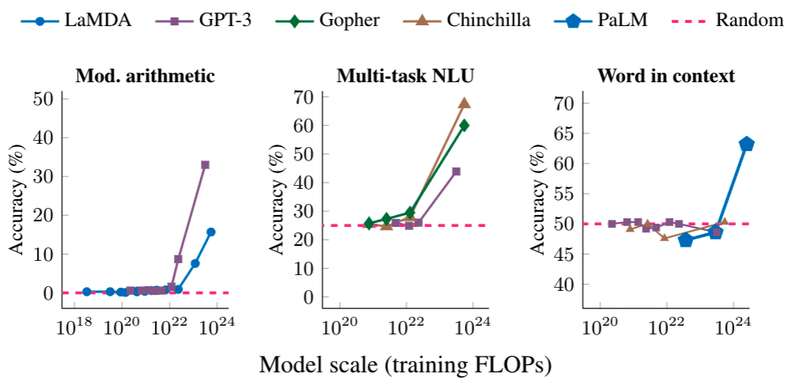
ある日突然、わかるようになる
こういった創発は実は自分の身にも起こっています。私はあまり学習が得意な方ではなく記憶力がいいわけでもありません。ですが、昔から「少し勉強して、少し経つと情報が自分で推察できる状態になっていることがある」という経験をしています。例えばギターを引き始めて全くコードが上手く引けなかったあと、3ヶ月放置して触れると少しの練習で何故かコードが引けるようになっていたり、プログラミングについてほとんど知らなかった自分が、2週間毎日数時間学習をしたところ、1ヶ月後には自分で調べて考えたりトラブルシュートができるようになっていました。「情報を浴びると突然何かが目覚める」ような感覚です。
実は最近も同じような経験がありました。
2022年12月末、私は仕事で業界Xについての担当をすることになりました。全く知らない業界を前に一体何から勉強すればいいのかというのがわからない状態でしたが、ひとまずは様々な情報に触れてみようということで調べ始めました。業界Xは日本ではどのような産業なのか、日々どのようなニュースがあるだろうか、動画で解説している人はいないか、まとまったホワイトペーパーを読んでみよう、海外の取り組みはどうだろうか、業界Xを題材としたシュミレーションゲームなどはないのか...etc
まさに上記のグラフの10の18乗や20乗の状態です。
それから約3ヶ月経った昨今、驚くことが起きます。まさに昨日、商談の一場面で業界Xのことを話す機会があったのですが、一昨日までは全く理解が捗らなかった経験をしていたのにも関わらず、また特段準備をしていたわけでもなかったのですが業界Xについて私見を含めて俯瞰的に語れるようになりました。
自分の中でも説明できない何かが起こっており、なんとも脳がスッキリした状態になっていることを体感しています。
人間とAIの学習は似ている?
これらの経験とAIの推論から元に人間(もしかしたら自分だけかもしれません)は、理解をするよりも先に脳内で無意識に情報を蓄積しているのではないかということがあります(そういう研究があったら知りたいです)。つまり、理解を実感するためには大量の関連する情報を浴びデータの関連性を蓄積する必要があり、それをアウトプットできたときに「理解できた」と感じるような仕組みがあるのではないかということです。そのため興味があることに対して無意識に情報を集めたりあるいは種まきのような行動をするのではないかと考えられます。(振り返れば関係のあることをしていたということに気づくのは皆様も経験があるのではないでしょうか)
これは先程紹介した、AIが大量のデータを参照してもある段階までは全く成果があせず、ある閾値を超えると急に理解ができる(推論の正確性があがる)ような現象に通じるものがありますね。
ほんとうの意味で人間とAIの学習が似ているのかというのはわからないのですが、少なくとも私自身はAIの学習に近い脳の動きがあるようなので、情報を大量に浴びることとその中でのパターンを無意識に見つけ出すことでより賢くなっていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?