鳥写真のトリミングを自動化したい

バードウォッチングでたまっていく鳥写真。望遠レンズがしょぼいこともあり撮影後に鳥の部分だけ切り抜きをするのだが枚数が多くて大変なのでSSDという物体認識ライブラリを使ったLightroom Classicのプラグインを作って自動でできないかという話。
前回までのあらすじ
写真の編集にAdobe Lightroom Classic というデスクトップアプリケーションを使っている(クラウド版ではなく)ので、幸いにしてプラグインSDKが提供されており、自分でプログラムを組むかマーケット等で提供されるプラグインを利用すれば作業の自動化は可能。ただドキュメントが「あっさり」しているためどのパラメーターがあってどういう風に動作するか、いちいち試しながら確認していた。
やりたいこと
あまり凝った使い方はできてないのですが、自分の鳥写真の編集フローは以下の通り:
写真の取り込み(1回の探鳥で100-1000枚程度のRAW画像)
失敗写真に除外フラグを付けて非表示にする。(1/2 - 1/3に削減) (*1)
鳥の種を判別する (これは現場で終わることも多いが宿題になることも)
よさそうな写真に採用フラグを付けてその他を非表示にする。(数枚 - 数十枚に削減)
採用フラグを付けた写真を編集する。
- 鳥の切り抜き (cropping) (*2)
- カラープロファイルの設定
- 明るさの設定 (WB, 露出, コントラスト, 白飛び, 黒つぶれの補正)
- その他、必要に応じてノイズ補正や回転、微調整など
このうち、最も時間がかかっているのは(*1)の失敗写真の除外で、単純に枚数が多いからなのですが、今のところ自動化の目途がたたないので、当面はキーボードショートカットなどを駆使して頑張ることにしました。めどが立たない、というのは失敗の基準が不明確だからで、ブレ、ピンボケ、見切れ、鳥が写ってないは当然除外されますが、うまく写っているが連写で同じのが複数写ってしまった場合は1枚を残して他のは除外するし、逆に構図がダメだが鳥の種類の判別のために参照したいということで除外しないこともあるし、たまには鳥以外の風景や猫なども撮るという感じです。
そこで今回は次に効果がありそうな(*2)の鳥の切り抜きの自動化を試みたいと思います。これはどうしてもマウス操作が主となるため面倒です。主目的は、小さく写ってしまった鳥を(画素数を犠牲にして)大きく見せることで、本当は撮影時に望遠レンズを調整するか自分が鳥に近づければ一番いいのですが、焦点距離が足りないとか鳥を脅かさないためとか物理的にアクセスできないとかで小さくなることが多いです。もう一つは構図を調整するという目的もあります。鳥の位置や背景との関係を決めるのですが、もちろんいつも真ん中に大きく写っていればいいわけではなくて、背景の方を活かして鳥を小さめにしたり、1/3構図だったり、鳥の向いてるほうを大きめに空けることもあります。さらに複数の鳥が写った場合も1羽を見るのか全体を見るのか、自由度があります。
考え出すときりがないですが、基本線は図鑑構図(日の丸構図)で、たまに違うことをしたい場合は手作業で修正する、でそれなりの効果があるだろうという仮定の下、鳥を中央にして一定の大きさで切り出す機能を実装したいと思います。
みんなどうやってんの?
Lightroomのクラウド版で自動切り抜きがテストされたという話はあるんですが、使ったことがないのでわかりません。実用化されたんだろうか。切り取るべき場所も提案してくれるんだろうか。気になるところです。
https://lightroomkillertips.com/lightroom-suggest-crop-automatically/
さっき見つけたのがこちらの「Croppola」というサービス。適当に写真をドラッグアンドドロップすると適当に適当な切り取り枠が提案されます。鳥の画像なら確かに鳥を囲むような枠が出てきます。時々真ん中からずれた切り取り方をするなど、謎な挙動もありますがこれはすごい。
しかも(ご予算が許す限り)APIもあるのでプログラムからも制御できそうです。デスクトップアプリケーションと統合するのは面倒そうだけど、できない話ではないよなあ・・・。
https://croppola.com/documentation/
学会では自動クロッピングの話題もありますし、実際に企業のサービス(ニュースやSNS)で使われているものも多くあります。が、まあ普通は顔にフォーカスしますよね。(参考記事は有料)
似たような話で人物と背景を(四角ではなくて人物の形で)分けるというのもよくあるニーズですが、今回は鳥でやりたいのと四角く切れればいいのでちとオーバースペックかと。
https://nlab.itmedia.co.jp/nl/articles/1812/19/news117.html
あとは、自動トリミング(trimming <=> croppingと違うらしい)といって無駄な余白を切り取れという話もあります。この場合は切り取りたい部分は背景色であることが想定のようです。これもやりたいことと違うか。
http://hitoriblog.com/?p=40274
まとめると、鳥に対応したクロッピングとしてはCroppolaというサービスがあるもののLightroom Classicと統合できるかというところ。できればローカルで切り抜き処理が完結すると試すのは楽ですが・・・。
手っ取り早い実装: SSD Kerasの訓練済みモデルを使う
物体検出(写真の中で特定の種類の物の位置とおよその大きさを検出する)タスクの問題だということにして、使えるライブラリーがないか、できればKerasが楽だなと思って探したところこれが出てきました。もともとはCaffe用だった実装をTensorFlow + Kerasに移植したもののようです。
https://github.com/weiliu89/caffe/tree/ssd
インストール方法や学習済みモデルの使い方についてはこちらのブログも参照してください。
SSD: Single Shot MultiBox Detector 高速リアルタイム物体検出デモをKerasで試す - Qiita
https://qiita.com/PonDad/items/6f9e6d9397951cadc6be
で、これの何がいいかというと、サンプルとして学習済みのモデルがhdf5型式で提供されているからでして、しかもJupyter Notesのサンプルコードを見ると以下のように書いてあります。
voc_classes = ['Aeroplane', 'Bicycle', 'Bird', 'Boat', 'Bottle',
'Bus', 'Car', 'Cat', 'Chair', 'Cow', 'Diningtable',
'Dog', 'Horse','Motorbike', 'Person', 'Pottedplant',
'Sheep', 'Sofa', 'Train', 'Tvmonitor']なんとBirdクラスが学習済みなのです。神か。サンプル画像には鳥はなかったので手持ちの池の鳥の写真を入れてみたところちゃんとクラスと場所と大きさを認識している・・・使うのは結構簡単みたいです。一方で一つ上の猫とラジコンカーの写真、猫さんを認識できていないような。背景と色が被っているからでしょうか。
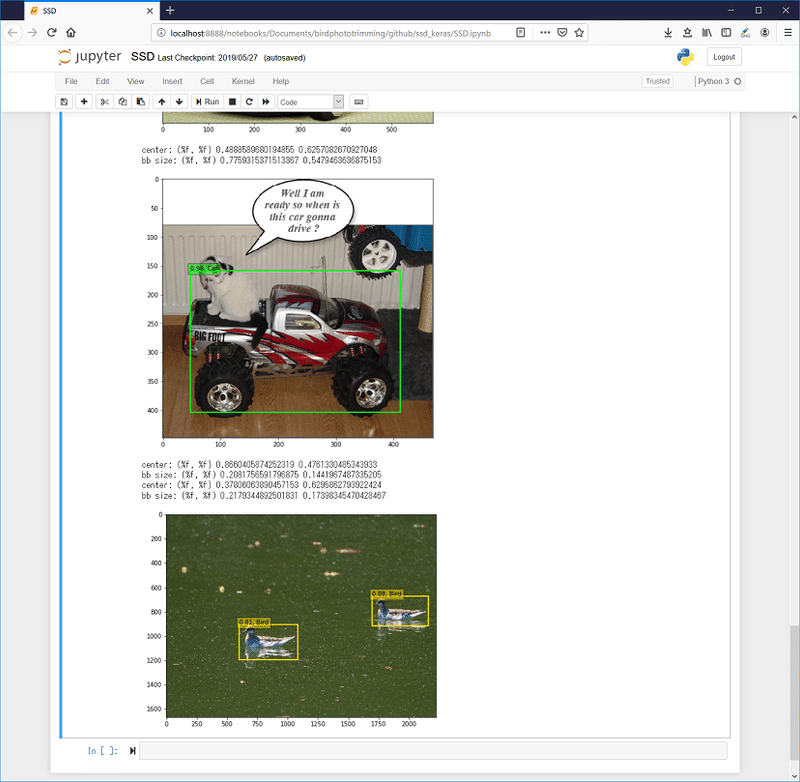
というわけで、性能など定量的な評価は全くしていませんが、まずはこの学習済みモデルを使用させていただくことにします。
全体の構成
選択画像の情報の書き出し: Lightroom Classic のフィルムストリップ(画面下部のサムネ)で選択状態にある写真の一覧をLightroom Classic SDKで取得し、それぞれの写真のフルパスを得ます。これは以下のようにLrPhotoインスタンスのコレクションを取得しそれぞれのインスタンスについてメタデータ"path"を取得します。これはRAWファイルのパスなので、後段でJPEGを使うためには本来は変換が必要ですが、自分の場合はたまたまRAWとJPEGをカメラで同時に撮影して同じフォルダーに入れているのでRAWファイルの場所が分かれば拡張子を変えるだけにしています。結果はいったん中間ファイルに書き出しています。
local activeCatalog = LrApplication.activeCatalog()
local photos = activeCatalog:getTargetPhotos()
for ip, photo in ipairs(photos) do
local photopath = photo:getRawMetadata("path")
local photoFileType = photo:getFormattedMetadata("fileType")
fout:write(string.format("%s,%s\n", photopath, photoFileType))
end
物体検出と切り抜き枠の計算: これは上記のSSD KerasのリポジトリにあったJupyter Notesのサンプルとほぼ同じ方法でPythonで記述しています。先ほどの中間ファイルを読み込んで個々の画像ファイルパスごとにJPEGファイルを300x300画素にリサイズして読み込み、別途学習済みモデルをロードして物体検出させます。リサイズしたのはこのモデルが300x300の画像で学習されているためです (CNNなんかだと画素数変えてもいいんでしょうがこのモデルは全結合層があるので恐らく固定サイズでしか動かないです)。検出した物体のうちconfidence >= 0.6でクラスがBirdの物だけを残して、そのbounding boxの座標を利用します。
少しだけ作りこんだ点としては、複数の物体を検出したら一番大きいもののみ1つ残す、bounding boxを1.5倍ぐらい大きくする(脚がはみ出たりするので)、縦横比は元の画像と同じ(検出されたbounding boxの長辺に合わせる)、画像からはみ出さないよう外周でクリップ、です。
結果は、鳥があるかないかのフラグ、切り抜き座標(xmin, ymin, xmax, ymax)を対応する元画像のフルパスと共にCSVで中間ファイルに出力します。
元画像への切り抜きの適用: ここはまたLightroom Classic SDKで実装しています。まず上記の中間ファイルを読み込みます。CSV形式は標準で対応していないとのうわさなので、テキストとして行ごとに読んで単純にコンマで分割しています(エスケープ処理などはサボり)。対応する元画像をセレクト状態にし、鳥が検出された写真にはカラーフラグ(今回は紫)を設定し、切り抜きのプロパティを設定します。
local photo = activeCatalog:findPhotoByPath( path, true )
activeCatalog:setSelectedPhotos(photo, {})
if birdflag == "true" then
LrSelection.setColorLabel(birdlabel)
for index, param in ipairs(cropParamNames) do
LrDevelopController.setValue(param, tonumber(paramMap[param]))
end
else
LrSelection.setColorLabel(nonelabel)
end
気を付けた点としては、前回のブログ記事でも参考にさせていただいた「記憶は人なり」の記事にあるように4Kサイズの画像のロードに数秒かかるため、1枚当たり5秒程度のウェイトをかけてあること、したがって全体としてはバックグラウンドタスクになっていること、です。
またDevelop Controlを使用するためLightroom Classic は「現像」モードにあらかじめ設定されている必要があります(エラーも出ないしプラグインから変更することもできないので手動で)。
結果と残る課題
上記の3ステップですが、まだLightroom Classicプラグインから外部プログラムを起動するところ (特にPython (Anaconda) の特定の環境にスイッチする方法) が実装できておらず、Pythonプログラムは手作業で起動しています。それでもとりあえず使ってみていて、結果がこの記事の最初の画像のようになります。
定量的な評価はしていませんが、だいたい鳥の種類や色によらず検出できているようですが、森の小鳥の画像が特に未検出になりやすいようです。枝かぶりや保護色など本質的な難しさもありますが、今のところSSDにかける画像を300x300ピクセルに縮小しているのが原因ではないかと疑っています。元画像サイズは4608x3456なので、情報量としては1/200ぐらいに落ちてしまっています。この制限は使用している学習済みモデルがこのサイズで学習されていることから来ている(と私は理解している、知らんけど)のですが、CNNと違って(おそらく)全結合層のニューラルネットワークを含んでいるので、高解像度に対応するには再学習が必要となります。これはGPUマシンを持っていないこともあるし、元画像は200倍大きいわけで相当な時間がかかりそうです・・。もちろん教師データを作るためのアノーテーションが大変というのもあります。ので、とりあえずは閾値の調整や探索範囲の制限など別の方法をまずは試したいと思います。
あとは、複数の鳥を検出したとき現在は一番大きい1羽のみ取り出していますが、すべての鳥を囲むように範囲を広げたほうがいいのかもしれません。こういうのをルールベースで作りこんでいくのか、あるは切り取り方自体を「うまい人」の写真から学習させたほうがいいのか、ここら辺も悩みます。前述のCroppolaのサービスを使えば後者もあっさり実現できるのかもしれません。
しばらく使用感をいろいろ確認しながら、また更新があったらブログ書きたいと思います。
この記事が気に入ったらサポートをしてみませんか?