LLMファインチューニングのためのNLPと深層学習入門 #3 系列変換モデルとアテンション機構(2)

前回は系列変換モデルの概要と変遷、そしてアテンション機構の特徴と、アテンション機構の導入により何が変化したかという内容についてまとめました。
今回は、前回からの続きということで、『系列変換モデル と アテンション機構 [seq2seq から Transformer まで]』の2. seq2seq with attentionから再開します。
1. (おさらい)seq2seqによる機械翻訳

(系列変換モデル と アテンション機構 [seq2seq から Transformer まで] から引用)
seq2seqは、DNNを用いた初めての機械翻訳システムです。
(OpenAI のIlya Sutskeverの代表的研究の1つ)
RNN2つを直列に結合したEncoder-Decoderモデルで、入力言語をRNNによってEncodeした結果の潜在変数ベクトルを入力として、出力言語のDecoder側RNNが出力言語の単語をひとつずつ生成する処理を繰り返すことにより、自己回帰的に入力文と同じ意味の翻訳済み文章を出力します。
2. seq2seq with attention

(系列変換モデル と アテンション機構 [seq2seq から Transformer まで] から引用)
seq2seq with attention [Bahdanau et al. 2015] は、名前から分かる通りseq2seqにアテンション機構を追加したものです。
アテンション機構により、次の単語を毎フレーム予測する際にエンコーダ側の全単語へのアテンション係数を計算しなおすので、入力系列全体のコンテキストを考慮しつつ、各フレームごとに重みを適応的に変化させて予測することができました。
3. 画像キャプション生成への応用
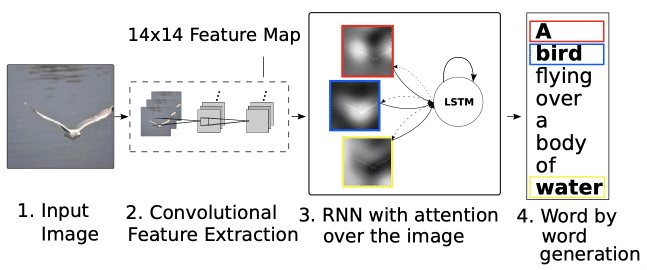
画像のキャプション生成では、"Show, Attend and Tell"という画像キャプション生成フレームワークとしてseq2seq with attentionが応用されました。
これは、RNN-Encoderの代わりに、画像をCNNでEncodeした結果である14x14特徴マップの各グリッド位置特徴にアテンション係数を割り当て、デコーダ側のRNNへの入力としています。
"Show, Attend and Tell"は、"Show and Tell" [Vinyals et al., 2015]にアテンション機構を挿入して拡張した提案です。
"Show and Tell" の時点では、画像全体に対する単一特徴ベクトルを文章生成RNNLMへと入力していました。
2014~2015年ごろは、CNNによる物体検出システムは黎明期であり、それほど頑健なモデルではなかったため、積極的に採用されることはありませんでした。
しかし、Faster R-CNNの登場以降、画像からROIを検出し、各領域をROI Poolingした領域特徴にアテンション機構を通じて物体を説明する単語へ対応付ける手法が提案されていきます。
以後、「物体検出結果を、物体単語の生成に、明示的に活用するアプローチ [Anderson et al., 2018 など] 」も主流となっています。
4. Transformerを用いた系列変換モデル
Transformerは、マルチヘッドアテンションが主部品として採用することで、片方の系列内の全トークンと、もう片方の系列内の全トークンに対するアテンションを一括計算するようにした、seq2seq with attentionの改良モデルです。[Vaswani et al. 2017]

(系列変換モデル と アテンション機構 [seq2seq から Transformer まで] から引用)
Transformerは、マルチヘッドアテンションと順伝搬ニューラルネットワーク(トークンごとの非線形変換を行う)で構成されるTransformerブロックを用いた深層Encoder-Decoderモデルです。
このモデルでは、エンコーダとデコーダに6つのTransformerブロックがそれぞれスタックされ、さらに残差接続が活用されてモデルの深さが増しています。
メイン部品であるマルチヘッドアテンション内の各アテンションは「系列トークン全体に対する行列変換(Query, Key, Valueアテンション)」となっています。
これにより、系列内の全トークンのコンテキストを考慮しつつ、行列計算を用いて効率的に「系列内の複雑なベクトル間の変換関係」を一度に扱うことが可能になります。
4.1 Transformerとseq2seq with attentionの違い
前回の記事と併せて説明した、seq2seqなどのモデルに使われているRNNでは、系列全体のうち、前のフレームの単語をもとに、次のフレームの単語を予測します。
つまり、2フレーム間のローカルな符号化を行うモデルでした。
一方、Transformerでは、系列中のトークンK個全体の変換を、マルチヘッド(自己)アテンションを用いて、ブロック内では一気に変換する方式が採用されました。
逐次的に毎フレーム符号化していくRNNベースのモデルと比べ、Transformerでは系列全体のグローバルな一括計算が中心となったことで、処理が効率的になりました。
4.2 Transformerの利点
最後に、これまでに説明したTransformerの利点を整理します。
Transformerは、処理全体をマルチヘッドアテンションでの連続変換で構成することで、
系列全体を考慮したコンテキスト処理(のスタック)
いっぺんに系列全体の処理が済む効率的な処理
を実現しました。
これはTransformerの論文タイトルである「Attention is all you need(系列変換モデルに必要なのはアテンションだけ)」にも表現されています。
しかしその後、Transformer-XLや、音声でよく使われるConformerなどにみられるように、RNN式のフレーム間再帰や畳み込み層は結局Transformerにもよく使用されています。
ちょっと記事を投稿するのが日付を回ってしまいましたが、Transformerの基礎知識である系列変換モデルとアテンション機構について、理解が深まりました。
アテンション機構についてはもっと詳しく知る必要があるのかなと思います。
マルチヘッドアテンションに到達したいので、今後の流れとしては
1. seq2seq
2. seq2seq with attention
3. Transformer か マルチヘッドアテンション のどちらか
になると思います。
では、次回はseq2seqについて勉強していきます。
それでは。
参考
系列変換モデル と アテンション機構 [seq2seq から Transformer まで], CVMLエキスパートガイド, 林 昌希, 2022
この記事が気に入ったらサポートをしてみませんか?