
#08 テキストマイニングで技術士二次試験の問題分析【ChatGPT活用】

以下の記事に続き、技術士問題掘り下げてみます。
というより、最近テキストマイニングに興味があって、技術士の問題を例にしただけ&途中でChatGPT使えるな??ってなっただけです。
興味本位で動いてます。
テキストマイニングとは
Wikipediaの言う通りですが、文章を区切って(形態素解析)、単語の頻度とか相関とか見るものと理解しています。
普通の統計とは違って、数だけじゃなく、この単語の後ろにはこういう単語が多いとか、この単語とこの単語が近いとか相関がわかります。
テキストマイニング(英: text mining)は、文字列を対象としたデータマイニングのことである。通常の文章からなるデータを単語や文節で区切り、それらの出現の頻度や共出現の相関、出現傾向、時系列などを解析することで有用な情報を取り出す、テキストデータの分析方法である[1]。
これを使うと、自由記述の文章を分析することができるので、アンケートとか意見とか、整理しにくかった情報を体系的に整理できるとかできないとか。
たまたま、こんな論文を見かけて、技術士の二次試験問題に適用したら面白いのでは?と思ったのが今回のきっかけです。
出典:khcoder3のチュートリアルより抜粋

出典:Pythonを使ったテキストマイニングについて、プログラムを交えて解説
khcoder
使うツールは、立命館大学教授が作成されたkhcoderです。
公式の書籍もあって、操作もGUIでわかりやすいです。
pythonでやった方が仕組みがよくわかりそうですが、、とにかくやってみたいが勝ちました。
Twitterからデータを吸い上げてテキストマイニングなんかも面白そうですね。こういうことするならpython必須。
テキストマイニングの準備
対象データ作成
技術士二次試験の過去問は公開されています。
ここからDLしてエクセルか何かに文章をコピペして、、と思いましたが、まさかのpdfが画像形式。文字選択ができないため、OCRのサイトに放り込んで文字起こしからやりました。
起こしした問題を、Excelに出題年や問題番号で属性をつけながら一覧にしました。分析は大問内容(赤字)の列を対象にしています。
R1年度に問題形式が変わり、全部論述問題になったので扱いに悩みましたが、選択問題には誤りも含まれているので、今回は問題文だけを対象にしました。

語の取捨選択設定
とりあえず一回データを放り投げて、形態素分析の結果からうまく単語にならない言葉は"強制抽出語"、抽出不要な言葉は"使用しない語"に登録しました。
うまく単語にならないというのは、"堤防"という単語が"堤"と"防"に分かれてしまうことを指してます。
マニュアル作業になりますが、この作業も非常に重要な気がします。

技術士二次試験問題の分析結果
形態素分析
まず形態素分析の結果から、抽出単語リストを見ると、災害、河川、社会など建設部門らしい単語が上がってきました。
ただ、これだけでは何の分析にもならない、、

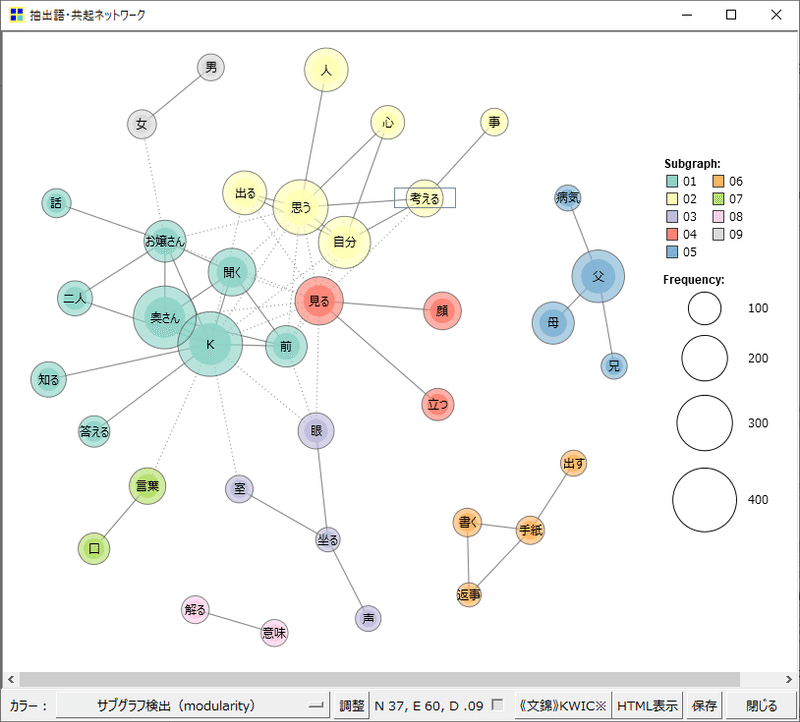
共起ネットワーク
共起ネットワークはそのまま作ると、また分析しにくいので問題番号と関係づけて作成してみました。
全部に共通するのは災害でした。
当たり前ですが、技術士建設部門の本質かもですね。
専門的学識が問われる選択ⅠⅡは洪水、堤防、津波など専門用語が集中しています。
解答形式が似ていて、同じ問題解決能力が問われる必須Ⅰと選択Ⅲは社会や経済など大きい単語がよく出ています。選択に共通する河川、海岸、土砂は問題文に必ず含まれる言葉なのであまり関係はなさそう。

年度との関連付けでも作成しましたが、R1年度を挟んで問題形式が異なるので、H30以前の情報が少なすぎる。。
技術士問題は、3,4年周期で問題が似ている傾向があるので、そのあたりが見れたらと思いましたが、微妙な結果。

対応分析
対応分析図も作成してみました。
共起ネットワーク図をより細かく見た感じになるのか、考察が難しい、、

ChatGPTを使ったグルーピング、クロス集計
ここまでの分析はソフトの力でサクッとできるんですが、どんな分野の単語が多いか、とかクロス集計的なことをしようと思うとグルーピングが大変なので、ChatGPTを使ってみました。
非常に参考になりました↓
方法は、以下のような流れです。
1. khcoderで抽出単語リストを作成
2. 単語リストをChatGPTに記憶させ、10グループ程度に指定のデータ形式でグルーピング
3. khcoderのコーディングを使って、グループ単位の統計を取る。
2.のグルーピングのChatGPTへのプロンプトは以下です。
GPT-3.5は含まれていない語を入れたりしてきて、GPT-4.0(有料版)の方がうまくいきました。
プロンプト1
以下の文章を"分析用テキスト"として記憶だけして、結果の表示や分析はしないで次の入力を待ってください。
~抽出後リスト~
プロンプト2
”分析用テキスト”について、形態素解析を行い、単語を抽出して、似た意味の単語を10個にグループ化して、グループ名を付けて次の形式で表示してください。
*”グループ名”改行”単語1″” | “”単語2″” | “単語3″……
この流れで作成したグループが以下のようになります。
若干の手直しは入れましたが、いい感じかと思います。
* 災害種別
地震 | 洪水 | 津波 | 台風 | 豪雨 | 噴火 | 高潮 | 雪崩 | 土砂崩れ | 乾燥 | 雷
* 防災・災害復旧
対策 | 防災 | 避難 | 砂防 | 警戒 | 予想 | 予測 | 救援 | 災害復旧 | 緊急対応 | レスキュー
* 地域・環境
国土 | 地域 | 都市 | 自然 | 環境 | 気候変動 | 海岸 | 山岳 | 森林 | 湖 | 河川
* インフラ・施設
ダム | 堤防 | 施設 | インフラ | 建設 | 堰堤 | 土堤 | 橋 | 道路 | 鉄道 | 空港
* 管理・維持
管理 | 維持 | 保全 | 修繕 | 点検 | 耐震 | 強化 | 維新 | 復旧 | 更新 | 水害対策
* 社会経済
社会 | 経済 | 成長 | 人口 | 老朽 | 高齢 | 安全 | 人口減少 | 都市化 | 地方創生 | 雇用
* 情報・技術
データ | 技術 | 情報 | デジタル | プロセス | 計測 | 調査 | 分析 | AI | IoT | ビッグデータ
* 交通
交通 | 交通省 | 運輸 | 自動車 | 貨物 | 通信 | バス | 鉄道 | 船 | 飛行機 | 自転車
* リスク・問題
問題 | リスク | 問い | 課題 | 懸念 | 影響 | 危険 | 脆弱性 | 障害 | 妨害 | 複雑性
* 法律・規制
法律 | 規模 | 設定 | 措置 | 法 | 保障 | 制度 | 規定 | 法令 | 条例
これを使って、出題年と関連付けてバブル図のクロス集計をとりました。
問題形式がR1年度で変わるので時系列的な変化は何とも言えませんが、年毎の傾向はなんとなく見えるような?
例えば、R3年度はインフラ・施設、情報技術が多いので、維持管理とかDX関連のテーマだったのかなくらいの考察でしょうか。

おわり
まだまだやってみた、程度の内容です。
テキストマイニングは手法としてはソフトもあって、だいぶ環境整備されていますが、そのあとの考察が非常に難しいです。
真面目に本を読んで、考察の仕方を考えてみます。業務で必要になったらもっと時間かけれるのにな。
…サムネ画像は、khcoderのチュートリアルが「こころ」なので夏目漱石です。
noteにもいい記事多いです。参考にさせていただきました。
お時間あれば、以下も覗いていってください。
この記事が気に入ったらサポートをしてみませんか?