
Relational Graph Convolutional Networkについて解説してみた

概要説明
この記事では、去年ぐらいに話題になっていた、Relational Graph Convolutional Network(R-GCN)について、解説してみたいと思います。
内容的には、M. Schlichtkrull et al., “Modeling Relational Data with Graph Convolutional Networks”を日本語に訳し、僕なりに解釈して説明を加えたものです。
グラフコンボリューション系の日本語記事が少ない印象があったので、グラフコンボリューションって何?というような方への導入になれば幸いです(内容は論文解説なので難しいかもしれませんが)。
この内容は、去年、自分が書いたものを載せているので、情報が少し古くなっている可能性があります。また、授業のレポートとして取り組んだ内容だったので、言葉遣いがおかしいかもしれませんが、ご容赦ください。
参考文献
[1] M. Schlichtkrull et al., “Modeling Relational Data with Graph Convolutional Networks”, arXiv preprint arXiv:1703.06103, 2017
[2] ABEJA Tech Blog, 「機は熟した!グラフ構造に対する Deep Learning、Graph Convolution のご紹介」 [http://tech-blog.abeja.asia/entry/2017/04/27/105613] (最終検索日 : 2017 年 7 月 5 日)
1. 導入
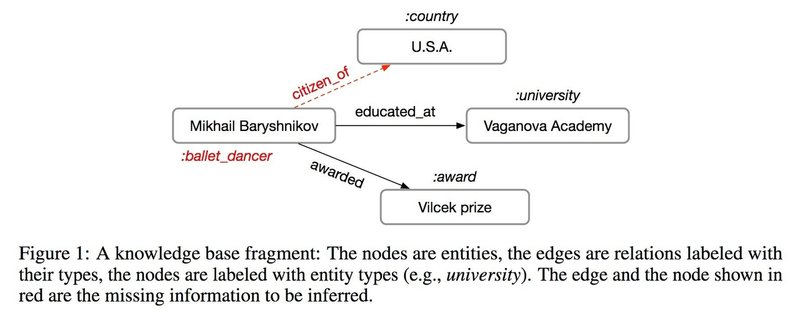
Relational Graph Convolutional Network(以降, R-GCN として表記) というグラフ構造の分析に主眼を置いたニューラルネッ トワークモデルが提案されており, このモデルを知識ベース補完 (knowledge base completion) に適用した事 例を紹介する [1]. この事例では知識ベース補完として, 欠損したエッジを予測する (ラベルのついていない エッジのラベルを予測する) エッジ予測 (link prediction) と, ノードのラベルを分類するノード分類 (entity classification) の 2 つの方法が適用の対象となっている. 以下の Figure 1 にこの事例で扱っている知識ベース の例を示す ([1] から引用). Mikhail Baryshnikov のノードから U.S.A へ向かう有効エッジが欠けている場合, このエッジ (citizen of が該当) を補うのがエッジ予測であり, Mikhail Baryshnikov のラベル (:ballet dancer が該当) がなく, これを予想し分類するのがノード分類である.
2. R-GCNについて
R-GCN で対象とするのはグラフ G = (V, E, R) である. 各ノード v_i ∈ V, エッジのラベル r ∈ R, ラベル のついたエッジ (v_i,r,v_j) ∈ E, というように表現される. ただし, (v_i,r_p,v_j) と (v_j,r_q,v_i) において, r_p と r_q が同じであっても, R においては別のラベルとして含まれる. グラフ G はループ, 多重エッジ, 有向エッジを 許容するグラフである. また, 各ノードはラベルと特徴量を持つ.
また, 多層の R-GCN のうち, 一層に関しての順伝播は以下の式に基づく.
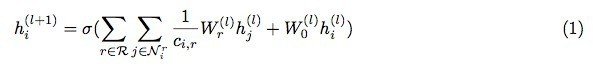
この式はノード v_i についての順伝播である. h_i^(l) ∈ R^(d^(l))は v_i についての l 番目の層への入力, つまり, v_iの l 番 目の隠れ層での状態を表す. d^(l) は l 層目の入力次元を表す. N_i^r は v_i と隣接し, r の関係を持つノードのインデックスの集合である. c_(i,r) は問題固有の正規化定数である. この定数はグラフの規模によらないモデリングをするために重要な役割を果たす. また, この定数はあらかじめ設定したり, 学習によって獲得したりする. σ は ReLU などの非線形活性化関数である. W_r^(l) は v_i と r の関係を持つノードの l 番目の隠れ層のもつ重み行列である. W_0^(l) は v_i の l 番目の隠れ層が持つ重み行列である. つまり, 自己ループの重みである. ただし, 各重み行列はノード依存ではなく, どのノードでも同じ重みが用いられる. 上記の式で計算されたh_i^(l+1)が次の層の入力となる. 以下, Figure 2a は l 層目の R-GCN の例を示す ([1] から引用し, 修正した).
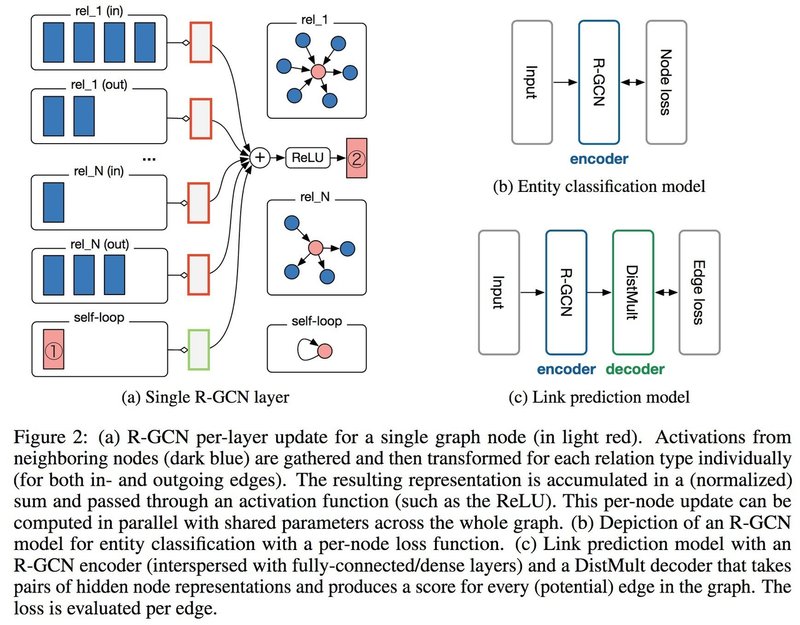
Figure 2a に基づき (1) の式を幾何学的に説明する. h_i^(l)(対象のノード, ① の部分) は Figure 2a では淡紅色で塗りつぶされた長方形で表現されている. また, h_j^(l)(対象ノードと関係のあるノード) は青色で塗りつぶされた長方形で表現されている. rel_n(in/out) は v_i との関係の種類を表しており, rel_n(in) は v_i に向かい, rel_n のラベルを持つエッジのあるノードの集合を表し, rel_n(out) は v_i から外へ向かい, rel_n のラベルを持つエッジのあるノードの集合を表している. W_0^(l) は Figure 2a の緑色の線に囲まれた重みを表しており, W_r^(l)は Figure 2a の赤色の線に囲まれた重みを表している.
各重み行列を各ノードの h^(l) に掛け合わせ, それらを合計したものを非活性関数 (Figure 2a では ReLU 関数) に入れ, その出力が h_i^(l+1) となる (Figure 2a における②の部分). この出力が次の層の入力になる (②→① ). また, 重みの表現として, 通常の表現 (basis-representation) とブロック対角行列の表現 (block-diagonal- representation) の 2 種類がある. なお, 1 層目への入力は重みが通常表現の場合, 各ノードの特徴量の one-hot ベクトルとなる. one-hot ベクトルへの変換は問題依存である. 重みがブロック表現である場合はこの one-hot ベクトルを密度表現 (dense representation) に変換したものが用いられる. basis-representation を使った R-GCN を R-GCN(basis) と表現し, block-diagonal-representation を使った R-GCN を R-GCN(block) と 表現することにする.上記のようにニューラルネットワークを使うことにより, 対象ノードの状態を, そのノードと関係のある ノードの状態を加味することにより更新していく.
上記のようにニューラルネットワークを使うことにより, 対象ノードの状態を, そのノードと関係のある ノードの状態を加味することにより更新していく.
3. R-GCN のノード分類とエッジ予測への適用方法
ノード分類
ノード分類の仕組みは Figure 2b に示してある ([1] より引用). アルゴリズムは, R-GCN の層をいくつか重 ね, 最終層で softmax 関数にかけるという操作をしており, 入力されたノードの特徴量ベクトルからそのノー ドのクラスを予想している. つまりはラベルのない予想対象のノードのラベルを隣接するノード (自分自身を 含む) の特徴量からそのラベルを予想するという仕組みになっている. なお, 目的関数は以下の交差エントロ ピーを用いる.

Yはラベルのあるノードの集合を表しており, h(L) はノード i を R-GCN に通した最終出力の k 番目のエントリー ([0, 1] の実数) を表現している. tik は正解のラベル (0 or 1) である. この目的関数を最小化するよう 勾配降下法をこの論文では用いている. 学習の種類は半教師付き学習である.
エッジ予測
エッジ予測の仕組みは Figure 2c に示してある ([1] より引用). エッジ予測には図のようなグラフオートエ ンコーダーモデルを用い, エンコーダーとして R-GCN を使い, デコーダーとして DistMult というモデルを 用いている. エッジ予測では E のサブセットである Eˆから可能性のあるエッジ (s, r, o) に評価値 f (s, r, o) を 割り振り, 各エッジがどれくらい E に属するかを予測する. DistMult は評価関数であり, 各ノードを R-GCN に通した後の出力を DistMult の入力にする. 各関係 r には対角行列 R_r ∈ R^d×d が割り当てられており, 各 エッジの評価には以下の式を用いる. ここでは e_i = h_i(L) である.

またモデルの推定はネガティブサンプリングをすることで行い, 目的関数として以下の交差エントロピーを用いる.
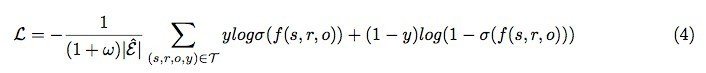
ω はネガティブサンプルの数を表し, T はポジティブサンプル, ネガティブサンプルを含めたすべての (s, r, o) を表す. σ はロジスティックシグモイド関数であり, y は, (s, r, o) の関係が存在していれば 1, 存在し ないと 0 を出力する. ネガティブサンプリングをする際は, ランダムにポジティブサンプルの s と o を操作してネガティブサンプルを作る.
4. 実験結果
ノード分類
R-GCN を使ったノード分類アルゴリズムをテストするために 4 つのデータセットを用いた. R-GCN(basis) を実験で使用し, そのテスト結果が以下である. なお, 他の手法との比較結果も載せている ([1] から引用).
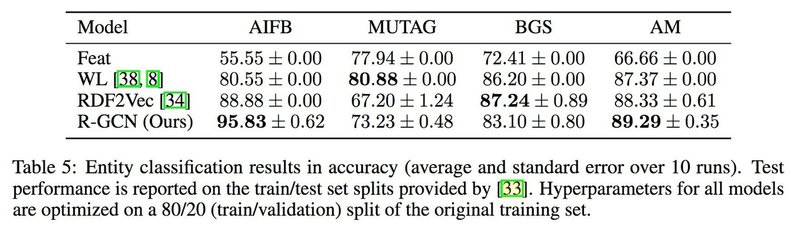
Table 5 から AIFB, AM のデータセットには精度がよいが, MUTAG, BGS のデータセットに対しては従来 の手法より精度が落ちている. AIFB, AM のデータセットは直接的なエッジを多く含む一方, MUTAG, BCG のデータセットは直接的なエッジが少なく, 例えば大局的なハブを持っているなどの特徴がある. このことか ら R-GCN は直接的なエッジを多く含むデータセットに対するノード分類は高精度でできることがわかる.
エッジ予測
R-GCN を使ったエッジ予測アルゴリズムのテストをするために FB15K(Freebase), WN18(WordNet) という2つのデータセットを用いて実験を行った. その結果が以下の Table 2 である ([1] から引用). な お, この 2 つのデータセットに対しては R-GCN(block) よりも R-GCN(basis) の方が精度が良かったため, R-GCN(basis) での結果を用いている.
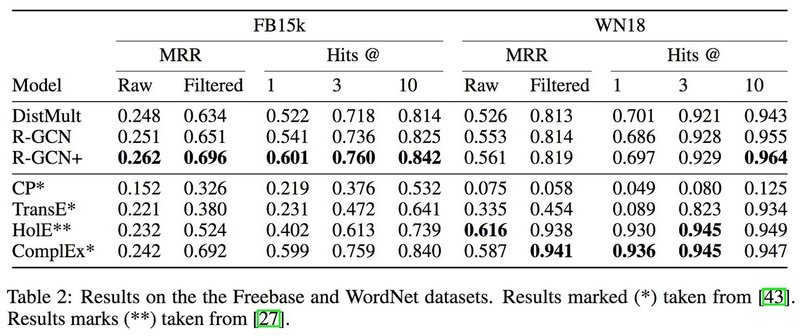
DistMult は, Figure 2c と同じような構造をしてるが, エンコーダーには固定の写像を使っている. R-GCN+ というのは f(s, r, t)_R−GCN+ = α * f(s, r, t)_R−GCN + (1 − α)f(s, r, t)_DistMult のように, R-GCN とDistMult を組み合わせたモデルと, 固定写像を使った DistMult のモデルの出力を融合したモデルになっている. なお, 実験では α = 0.4 という数字が用いられている. この実験では MRR と Hits という 2 つの評価指標を用いている. また, MRR は Raw と Filtered に2つに分けることができ, Hits は Hits@n として分けられるが, ここでは n として, 1, 3, 10 を用いている. CP, TransE, HolE, ComplEx は既存の手法である. また,c_(i,r) = c_i = ∑ _r|N_i^r| が正規化係数として用いられている. また, FB15K から低頻度の関係, 近傍の重複する関係を除いて作成したFB15k-237 のデータセットを使って実験をし, 以下の結果を得た ([1] から引用).
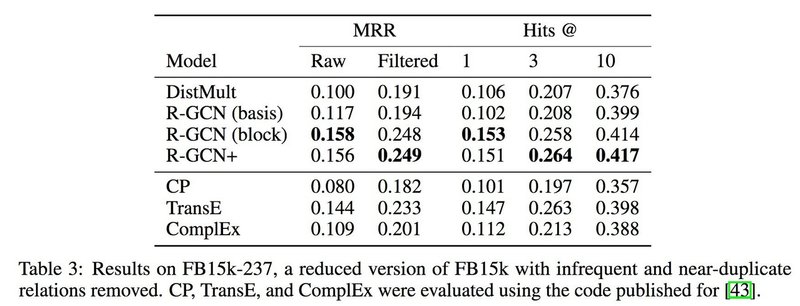
Table 2, 3 より, R-GCN がエッジ予測のタスクにおいて精度の向上に寄与していることがわける. まずは Table 2 について. 多くの場合, DistMult 単体を使うよりも R-GCN と組み合わせると精度が上がっているこ とがわかる. WN18 での実験では既存手法の方の精度がいいが, そもそも DistMult よりも HolE, ComplEx の方が精度がよく, R-GCN と DistMult を組み合わせたモデルはデコーダーである DistMult の性能に強く 依存することが考えられる. そのため, R-GCN のデコーダーとして既存の手法を使うと, 既存デコーダー単体 の精度よりも高い精度が出ると予想できる. 次に, Table 3 についてである. これは結果を見て分かるように既 存の手法よりも R-GCN を使った方が精度が高くなっている. このようなことから, R-GCN をエッジ予測の タスクにおいてノードのエンコーダーとして使用すると精度が上がることが分かる.
5. 考察
この章では, この論文に対する考察をする. ノード 分類とエッジ予測の2つのタスクにおいてニューラルネットワークである R-GCN が精度を発揮したのは, 対象ノードの特徴を, そのノードと関係のあるノードの特徴を加味した上で多くの層に値を通すことで, より表 現力の高い特徴をできたためであると考える. ノード分類では, 直接予測対象のノードの特徴量に基づいて分類するのではなく, 他のノードの特徴も含めた特徴に基づいて分類することで精度の高い分類ができたと考察 する. 例えば, Figure 1 で Mikhail Baryshnikov のラベルであるバレーダンサーを予測する際, アメリカ, 大学, 受賞した賞を加味すると, Mikhail Baryshnikov の属するクラスを予測するのは Mikhail Baryshnikov 単 体で予測するより精度が上がるのは明らかである (ただし直接的な関係のあるノードまでしか加味されない). エッジ予測のタスクでも同じことが言える. 他のノードの情報量も加えたノードの特徴に基づいて予測すると精度が上がると考えられる. このようにニューラルネットワークの特徴である, 多様な情報量の加算からの特徴抽出というものが, グラフにおけるノード分類, エッジ予測に効いたと考察する.
最後に
今回は、R-GCNについて解説してみました。誤植や間違っている点などがあればお願いします。
独り言 : note初めて使ってみたけど、数式使えないのやりにくい...
この記事が気に入ったらサポートをしてみませんか?