
人の認知が組み込まれたGAN -HumanGAN-

こんにちは。スキルアップAI編集部です。
敵対的生成ネットワーク(generative adversarial network;GAN)をはじめとした生成系の発展は目覚ましく、「写真が証拠になる時代は終わった」といわれるほど高品質な画像の生成ができるようになってきました。
本記事では、そのような生成系の中でも一風変わったHumanGAN[1]と呼ばれるものを紹介したいと思います。
そもそものGANの仕組みについてはこちらの記事をご参照ください。
1.HumanGANとは
HumanGANとは、Fujiiら[1]によって提案された新しい学習の方法です。 HumanGANはその名が意味するように人間が関わるGANであり、このGANでは人間がDiscriminator(=判別器)の役割を担います。
図1に、通常のGANとHumanGANの違いを示します。私の知る限りHumanGANのように人間とインタラクティブに学習が進むGANは他に存在しません。
ところで、人間がDiscriminatorを担うことにどんな利点があるのでしょうか。
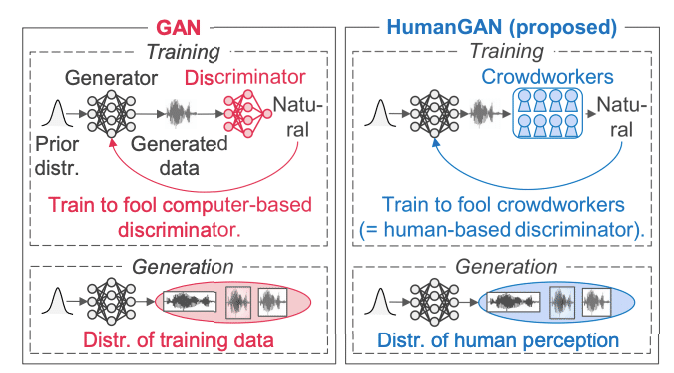
図1:通常のGANとHumanGANの違い
(参考文献[1]より引用)
2.HumanGANの利点
人間がDiscriminatorを担う利点として、Fujiiらは以下の2点を挙げています。
1. 人間は学習初期のDiscriminatorよりも識別能力が高い
2. 正解データの分布を人間が感覚的に決定できる
GANでは、Discriminatorの識別性能が低ければGenerator(=生成器)が生成するデータの質も当然下がってしまいます。人間は、学習初期のGeneratorに騙されない程度の能力を持っており、人間がDiscriminatorの役割を担うと、Generatorの学習がよりうまくいきます。
2点目の「正解データの分布を人間が感覚的に決定できる」については、音声を生成するGeneratorを例に考えてみましょう。
まず、人間が介入しない通常のGANの枠組みで学習を進めることを考えます。正解データとして人間の会話をたくさん集め学習を始めます。学習の過程において、Generatorが機械で合成されたような音声を生成したとします。Discriminatorがうまく学習できていればこの音声は偽物と判断されるため、Generatorは次第にこのような音声を生成しないようになっていきます。
ここで重要なのは、Generatorは正解データの分布の中にあるようなデータを生成できるように学習が進んでいくということです。学習が進んでいくほど、正解データの分布の外にあるようなデータが生成されなくなっていきます。
次に、人間がDiscriminatorを担っている場合を考えます。正解データは必要ありません。学習途中のGeneratorが機械で合成されたような音声を生成したとします。
人間は、Generatorに対し、その合成音声を音声として認めたいならば音声に聞こえると返し、認めたくないならば音声に聞こえないと返します。これを続けると、Generatorは、Discriminatorを担っている人間が認めた音声を生成するようになっていきます。
つまり、正解データの分布を人間が感覚的に決定できるということです。少し機械合成っぽい音声も音声として認めたいのであれば、それを生成させるようにすることもできますし、鳥の聞きなしも音声として認めたいのであれば、それを生成させるようにすることもできます。
3.HumanGANの欠点
HumanGANには当然欠点もあります。最大の欠点としては学習に時間がかかるということです。これは人間の返答を待たなければならないためであり、マシンパワーではどうにもなりません。
[1]ではクラウドソーシングで人を集めて学習を進めていますが、大規模なネットワークを用いたGeneratorの学習はやはり難しく、シンプルな構造のGeneratorが用いられています。
4.HumanGANの学習
通常のGANの学習方法をご存じの方は、HumanGANがどのように学習を進めているのかを疑問に思ったのではないでしょうか。
通常のGANでは、Discriminatorの出力を用いて計算された勾配が、誤差逆伝播法(backpropagation)によってGeneratorに伝えられます。
誤差逆伝播法とは、多層階層型ニューラルネットワークの学習方法で、入力層へ或る情報が与えられたら、出力層はそれに対応した或る情報を出力しなければならない場合の学習方法です。
Discriminatorが人間では、出力結果をGeneratorに伝えることができず、学習を進めることができません。
そこで、HumanGANではNatural Evolution Strategiesと呼ばれる方法を用いてDiscriminatorの結果をGeneratorに伝えています。
Natural Evolution Strategiesとは、データの摂動を用いて勾配を求める方法であり、簡単に言えばブラックボックス化されたシステムの勾配を近似的に求める方法と言えます。感覚的には数値微分に近いので、そのようなものを想像してください。
この学習方法はHumanGANの大きなコントリビューションの1つです。
5.HumanGANの出力結果
[1]によると、HumanGANの目的は、現実から得られるデータよりも広い範囲のデータを生成できるようになることです。
図2は、HumanGANにより生成された音声データが実際の音声データよりも広い範囲のデータを生成していることを示しています。

図2. 実際の音声データとナチュラルな音声と認識されるデータの範囲
(参考文献[1]より引用)
まず、1番左の図をみてください。これは被験者実験の結果です。
X軸とY軸は、被験者実験に用いたデータを次元削減したあとの第一主成分と第二主成分を意味します。カラーマップの色は0-1の範囲であり、値が1に近いほど、被験者はそのデータをナチュラルな音声と判断したことを意味します。被験者が判断したデータのうち、実際に音声だったのは白い丸の中のデータだけです。
これより、人は、実際の音声データよりも広い範囲をナチュラルな音声と認めることがわかります。
残りの5つの図は、1番左の図に、白い点をプロットしたものです。
白い点は、HumanGANによって生成されたデータを表しています。学習が進むにつれて白い点が白丸部分に近づいていますが、白丸の内側にすべて集まっていません。
これより、実際の音声データよりも広い範囲のデータを生成できているということがわかります。
6.もっと詳しく学びたい方へ
本記事では、HumanGANを紹介しました。スキルアップAI では、2月にGAN(敵対的生成ネットワーク)講座を開講します。この講座では、様々なGANを学ぶことができます。是非ご検討ください。
GANを深層学習の基礎から学びたいという方は、現場で使えるディープラーニング基礎講座をご検討ください。
また、スキルアップAIでは実践的AI勉強会『スキルアップAIキャンプ』を毎週無料で開催しております。
G検定・E資格の取得に止まらず、実務でのAI活用に必要な様々な実践的テーマを取り上げています。
1月28日には、GANをテーマに取り上げ、「GANの系譜を2時間で押さえよう GAN100本ノック」を開催します!ライブ配信で参加もできますので、この機会に是非ご参加ください。
詳細はこちら
7.参考文献
☆☆☆
スキルアップAIのメールマガジンでは会社のお知らせや講座に関するお得な情報を配信しています。
配信を希望される方はこちら
また、SNSでも様々なコンテンツをお届けしています。興味を持った方は是非チェックしてください♪
Twitterはこちら
Facebookはこちら
LinkedInはこちら
この記事が気に入ったらサポートをしてみませんか?