1 億ユーザー 1 億商品棚の実現に向けた、パーソナライズされた商品レコメンド機能の裏側(Part 1 背景・経緯編)

こんにちは、カウシェの AI チームの tatsuya(白川達也)です。
2022 年 11 月に入社してから検証・実装していた商品レコメンド機能がリリースされました(現状 iOS 版でのみ先行配信されています)。カウシェでは初めての機械学習にもとづく機能だったこともあり、リリースまでこぎつけるには超えないといけないハードルがあって時間がかかってしまったのですが、そのあたりの背景や経緯を踏まえ、実装の裏側を公開してみたいと思います。
本記事は「Part 1 背景・経緯編」です。カウシェで始めての機械学習系の機能である商品レコメンド機能の仕様がどのような経緯で始まり、どう開発されていったのかについて説明しています。大変でした。
技術詳細だけお知りになりたい方は 「Part 2 実装編」をご覧ください。
100 万ユーザー 1 商品棚という課題
カウシェは複数人で一緒に購入することでお得に楽しく買い物ができる「カウシェ」というソーシャルコマースアプリを開発・運営しています。
現状、カウシェの商品は基本的には Shopify 上で管理されており、アプリ上に表示する商品コレクション(商品をなんらかのトピックにまとめて紹介する機能)も Shopify 上で編集されています。

カウシェにはこの商品コレクションの設計など、商品プロモーションのプロが集った Promotion チームがあり、様々な切り口で商品の魅力訴求を日々試行錯誤してくれています。
一方、こういった編集作業はマニュアルで行われるうえ、Shopify 由来の商品コレクションはパーソナライズができないため、下記のような課題も発生していました。
人力でプロモートできる商品点数には限界があり、商品の魅力とは無関係な理由で日の目を浴びない商品が発生してしまう。
ユーザーの興味関心は本来多様なはずなのに、Shopify 由来の商品コレクションの内容はパーソナライズさせられないため、ユーザーの興味関心の多様性に対して個別最適化できない。
商品コレクションは手動の調整やランキングの変化がない限り商品の表示順序が固定されてるため、ユーザーの目にとまる上位商品の露出は固定されやすい。
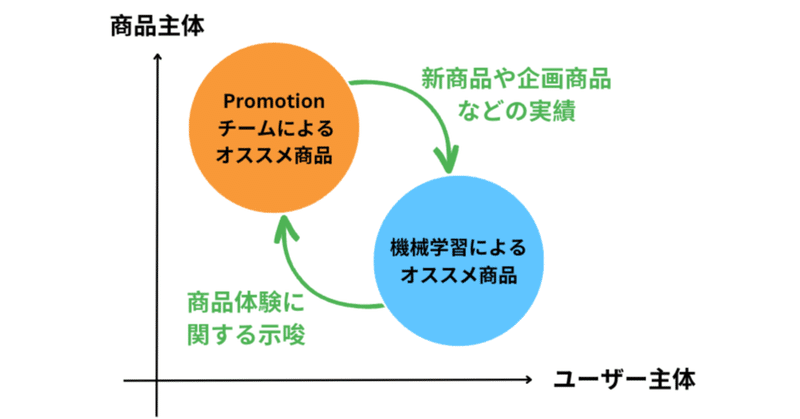
上記のような課題を解決するために、商品との出会いに対するパーソナライゼーションを実現したいと考え、機械学習に基づく商品レコメンド機能を実装することになりました。標語的に言えば、「1 億ユーザー 1 億商品棚」です。ユーザーひとりひとりに最適化された商品接触体験を提供し、より多くのユーザーにカウシェを利用してもらえるようにすることが目標です。
この商品レコメンド機能は Promotion チームの活動と補完的なものでもあります。機械学習はデータを必要とするため、新しい商品をレコメンドしたり、アプリ利用開始間際のユーザーにレコメンドを提供したりすることは原理的に難しいです。ChatGPT などの登場により将来的にはある程度可能になる部分もあるかもしれませんが、現状、商品をプロモートするための切り口を新たに見出すことも難しいです。そのため、これらは Promotion チームにいるプロにおまかせし、機械学習によるコレクションではそこで開拓された兆しを増幅し、パーソナライズさせていくことを目指します。逆に商品レコメンドから Promotion チームへ還元される示唆もあると思っています。
今回作成したもの
本記事執筆次点では iOS 版でのみの先行配信ですが、下記のようなパーソナライズされたコレクションが HOME 画面に出るようになっています。

現行、主にユーザーの閲覧履歴をもとに 1 日に 1 回レコメンドを更新しています(表示されない方は商品閲覧などをしながら 1 日お待ち下さい)。まだまだ多様性の確保や商品の選定、並び順の最適化、リアルタイム処理など改善の余地はたくさんあるのですが、なんとかファーストバージョンのリリースができました。小さい機能ですが、これを起点にパーソナライズされた体験の拡大を目指しています。
リリースまでの時系列
アプリに初めて機械学習系の機能を実装しようとしたとき何が起きるのかについては、あまりまとまった情報が共有されていないかもしれません。そのため、未来の誰かの参考になればと思い、今回の機能のリリースがどのような経緯を辿って実現されたのかを現在視点で振り返りつつまとめてみたいと思います。
2022 年 11 月 -- 企画〜データ分析〜データ分析基盤の整備
私は 11 月半ばにカウシェに入社しました。入社早々、機械学習エンジニアとして何を実装すべきかを相談し、機械学習をもちいたレコメンド機能を作成することになりました。カウシェでは当初から体験のパーソナライズに課題をもっていました。
ロジックの当たりをつけるためにデータ分析を進めるなかで、データウェアハウス(カウシェの場合、BigQuery)の整備も必要なことに気づきました。機械学習を使った機能はデータをもとに組み上げられるため、その機能をプロダクトとして提供するならば、データもプロダクトと同等の品質で取り扱われる必要があると考えています。しかし当時のカウシェのデータウェアハウスでは、
本番環境と開発環境でデータの有無が異なる
一部の重要データがスプシ由来で取得されていて読み取りが不安定
データウェアハウスの有用なテーブルなどが分析者により分析目的で手動で組み上げられており、将来にわたり安定運用できるか不明
などの問題がありました。そのため、データウェアハウスの整備も同時進行させることにしました。
2022 年 12 月 -- PoC 〜 ロジック決定 〜 Design Doc
機械学習基盤・データ基盤の選定をしながら、レコメンド機能を実現するためのロジックを試行錯誤しました。
機械学習基盤・データ基盤に関してはなるべくシンプルで手触り感のある構成が良いと考え、Vertex AI Pipelines を使うことに決めました。前職時代に検証していて雰囲気がわかっていたというのもありますが、今のタイミングでまともな workflow エンジンなど整備しだすと大変そうだったからでもあります。
今回の実装を通じて模索した Vertex AI Pipelines のプラクティスについては、下記の記事にもまとめたのでご興味ある方はご覧ください
レコメンド結果を格納する DB については、カウシェにはすでに導入されており、今回の用途ではパフォーマンス的な懸念もなかったので、Cloud Spanner を利用することにしました。
ロジックに関してはかなり早期におよその構成は決まりました。カウシェの場合、すでに結構な量のデータが揃っていたのですが、先述の通り、手動で管理された商品がユーザーに届けられていたのもあり、データのバイアスが気になりました。そのため、閲覧・購入情報に依存しすぎたレコメンド(Collaborative Filtering など)は避けたほうが良いと考え、コンテンツベースのレコメンドロジック(商品のテキスト情報の類似度を利用し、閲覧した商品と類似する商品をレコメンドするロジック)にしました。

設計においては、「芋づる式」であることも意識しました。具体的には、商品はベクトルに変換してベクトル検索可能にしておくことで、将来の使い回しをしやすくしました。また、いきなり Two-Tower Model などを組むことも考えたのですが、あえてもっと原始的で手触り感のある実装をするようにもしました。
このあたりの実装方針については下記の記事にもまとめたので、より深く知りたい方はご覧ください。
ロジックを作りつつ、Promotion チームにいるドメインエキスパートからもヒアリングし、ロジックに対する要件を詰めていきました。ドメインエキスパートの話はいつもとてもおもしろいです。カウシェでの体験品質を担保するためのビジネスルールをひとつひとつロジックに変換していきました。
これらもろもろの情報を最終的には Design Doc に落とし込んでいきました。Design Doc には機能のおおまかな仕様のほか、なぜその機能が必要なのか、どうしてその実装で良いのかなどの思想を背景知識とともに記述されています。これにより、実装に関係する誰もが継続的に同じ目線を持てるようにしています。
下記は、Design Doc に記した概念レベルのデザインです。

この全てが今回のレコメンドで実現されたわけではないのですが、現在もこの方針で実装し、改善を計画中です。Design Doc は概念レベルの内容を記した「概要編」と技術的な詳細を記した「詳細編」のふたつを用意し、相手に合わせて出し分けるというようなこともしました。ともあれ、Source of Truth をみんなで参照しながらアイデアと実現可能性を高めていくのは非常に大事だと思います。
このあたりまでの動きは、下記の入社エントリーにも詳細に記載しているのでもしご興味あればご覧ください。
なお、この頃は、「レコメンドってどれくらいで実装できますか?」と聞かれたときに、「2月半ばとかには実装完了できるんじゃないですか」などと軽々しく答えており、後々、自分の読みの甘さを後悔することになります。ごめんなさい。
2023年1月 -- データウェアハウスの設計・整備 〜 デモアプリを使ったロジック作り込み
8 割くらいの時間をデータウェアハウスの設計・整備に費やしていた気がしますが、Vertex AI Pipelines で実際にロジックを組んでみたり、Streamlit でデモを作っていろんな人に見せながら体験の検証したりしつつ、ロジックの微調整を進めていきました。
ユーザーが閲覧した商品に類似する商品をレコメンドすることは決めていたのですが、その商品をどういう順番で提示すべきかを決める必要がありました。議論の末、ユーザーが買いたくなる商品を買いたくなる順に配置するようにするという大雑把な方向性を決たので、BigQuery を叩いて特徴量抽出をしLightGBM に食わせて可視化して眺める…というのをひたすら繰り返していました。
2023年2月 -- データウェアハウスの設計・整備 〜 Python 開発環境構築 〜 本実装
この月も半分くらいはデータウェアハウスの設計・整備をしていた気がしますが、商品レコメンドもロジックはほぼ固まったので本実装を開始しました。
カウシェはモノレポで開発しているのですが、Python での実装は初だったので、Python で開発できる環境の構築からはじめました。運良く Poetry のグループ機能を使ってモノレポで手軽に開発できる方法を見つけたので、ブログにしました。いまも同じ方法で開発していますが、快適です。
ロジックはローカルにほぼすべて実装済みだったので、コードの整理をしつつモノレポ側に移行して行きました。
いつもながら、テストをどこまで書くかというのが結構悩ましかったです。結局、テストに関しては lint と単体テストを中心に行うことにしましたが、e2eテストをうまく導入できなかったのが心残りです。
商品レコメンド用の CI/CD も整えました。CI では下記の観点を中心にテストするようにしています。
lint(pysenをつかっています)
単体テスト
パイプラインがコンパイルできるかのテスト
パイプラインが動くかどうかは、現状、手元で実行させて確認しています。パイプラインの簡単なテスト方法をご存じの方がいたらぜひ教えてほしいです。
2023 年 3 月 & 4 月 -- バックエンド・クライアント開発 〜 ロジック開発完了
実は 3 月に組織改編があり、当初より少し遅れて 3 月からバックエンド・クライアントサイドの実装が開始されました。
レコメンド結果はデータベースにバッチ計算で格納しておく仕組みにしていたのですが、露出の固定化を防ぐために、そこから読み出す際に、並び順を多少ランダマイズさせるようにしていました。これが一因で、関係者間で仕様を調整するのにちょっと手間取りました。そもそも自分の API 仕様定義もだいぶ緩かったです。
API 仕様のやり取りの中で色々教えていただいた弊社の柴田さんが、最近、 WEB+DB PRESS Vol.134 に「仕様ファーストでいこう! 実践API設計 堅牢で,保守性に優れたWebサービスの実現」という記事を寄稿されていたのですが、思い当たる節だらけでした笑 おすすめです。
機能の実装を始めたときから QA をどうするかというのは話題に上がっていました。何を出力すべきか正解がなかったりして、機械学習機能の QA は難しいです。今回は以下のようにデータベースへの書き込み前後で責任境界を切り分けました。
レコメンド結果の作成に対する QA
意図したレコメンド結果が間違いなく作られているかに関する QA
これは白川が中心となり実施
レコメンド結果の表示に対する QA
作られたレコメンド結果が適切に表示されているかに関する QA
これは QA チームが他の機能開発に対するQAと同等のプロセスで実施
前者の機械学習特有の QA をどうこなすかは今後の課題です。
全体を振り返って
商品レコメンドの開発だけをしていたわけではないのですが、「芋づる式 AI 開発」を掲げておきながら、芋づる式に関連する基盤と環境の整備タスクも発生して、なかなか大変でした。現代のソフトウェア開発は、良くも悪くも様々な仕組みやプラクティスの上に成り立っているので、そこに異物を差し込もうとすると土台からの改善が必要になりがちです。組織も横断的に巻き込むことになりがちです。
レコメンド実装 → 利用するデータの整備 → データウェアハウスの整備
Python実装 → Python実装環境の整備 → モノレポの管理方法 & CI/CD の整備
…
ぐっと目をつぶってサボることもできるのですが、どうせいつか早期にやらねばならないタスクですし、ボディーブローのように聞いてくる部分なので今回はそれぞれ真面目に向き合って取り組んでみました。
世の中に同じ課題にぶつかっている方はいると思います。同じ課題感を感じる当事者同士でプラクティスを公開・共有しあえたら良いなと感じています。
以上、「Part 1 背景・経緯編」でした。技術的な詳細は「Part 2 実装編」に続きます。
カウシェにご興味を持った方がいらっしゃいましたら Twitter @s_tat1204 もしくは YOUTRUSTのカジュアル面談 などでお気軽にお声がけください。軽い気持ちでご応募頂いて話を聞いてみる、というのも大歓迎です!ぜひよろしくお願いします。
この記事が気に入ったらサポートをしてみませんか?