
ニューラルネットワークを用いた常微分方程式の解法

abstract 常微分方程式の解をニューラルネットワークを応用して数値的に解く方法を紹介します。またPython言語の autograd パッケージを用いたコーディングの例を示します。
1 Introduction
常微分方程式(ordinal differential equation, ODE)とは、一変数関数 $${x(t)}$$ に対して $${t}$$ と $${x(t)}$$ および $${k}$$ 階の導関数 $${x^{(k)}(x)=\displaystyle\frac{d^{k}x}{dt^{k}}(t)}$$ で定義される方程式
$$
f\left(t, x(t), x^{(1)}(t),\cdots,x^{(n)}(t)\right) = 0
$$
のことです。
常微分方程式はさまざまな分野で重要な役割を担っています。例えば物理学には、時刻 $${t}$$ での質点の位置 $${x(t)}$$ を、その質点の質量 $${m}$$ と力 $${F}$$ で表すNewtonの運動方程式があります。これは、次のような常微分方程式です。
$$
mx^{(2)}(t)-F=0
$$
興味のある常微分方程式について、解を求めることはとても重要です。しかし、典型的な常微分方程式であれば解の公式が知られていますが、一般的には初等的な関数で表せるとも限りません。そこで、常微分方程式を数値的に解くことは興味のある話題になります。
この記事では、ニューラルネットワーク(neural network)を使って数値的に解く方法を紹介します。まず、第2章では常微分方程式の例題を与えます。次に、第3章ではニューラルネットワークを用いて常微分方程式を解く方法を説明します。最後に、第4章では第3章で説明した方法を参考に、第2章で紹介した例題を解きます。
2 例題
例題として以下の常微分方程式を考えましょう。
$$
x'(t)+2tx = 0,\quad x(0)=1
$$
この常微分方程式は解析的に解くことができます。常微分方程式を式変形して、両辺に積分を適用すると、次のような式が得られます。
$$
\displaystyle\int \frac{x'}{x}dt = \int -2tdt
$$
この不定積分を計算すると、正の実数 $${C}$$ を用いて $${x(t)=C\exp(-t^2)}$$ と表せることがわかります。あとは初期値条件 $${x(0)=1}$$ から $${C=1}$$ が得られます。すなわち、この常微分方程式の解は
$$
x(t) = \exp(-t^2)
$$
です。
3 ニューラルネットワークを用いた解法
以下では、例題の常微分方程式をニューラルネットワークで数値的に解く方法を与えます。
常微分方程式の解 $${x(t)}$$ をニューラルネットワーク $${g(t;w)}$$ で表しましょう。このとき、解の表現を初期値条件を満たすように作ります。例題の場合、初期値条件は $${x(0)=1}$$ です。これを用いれば、以下のような表現が考えられるでしょう。
$$
x(t;w) = 1 + tg(t;w)
$$
また、ニューラルネットワークの重み $${w}$$ を求める方法を与えます。パラメータ $${w}$$ の値が適切であれば、解の表示式 $${x(t;w)}$$ は常微分方程式
$$
x'(t;w) + 2tx(t;w) = 0
$$
を満たすはずです。つまり、ニューラルネットワークのパラメータ $${w}$$ は十分に離散化された時刻の値 $${t_1,\cdots,t_n}$$ をとった時、各点で常微分方程式がどれだけ満たされているかは以下のように測ることができます。
$$
L(w) = \displaystyle\frac{1}{n}\sum_{i=1}^{n}\left(x'(t_i;w)+2t_ix(t_i;w)\right)^2
$$
これを損失関数に採用し、最小にするように学習させれば良いわけです。このパラメータ $${w}$$ の値は、通常のニューラルネットワークの学習と同様に勾配降下法を用いて求めることができます。
4 Python言語を用いた計算
4.1 import文
以下では、autograd パッケージを用います。
# import文
import autograd.numpy as np
import autograd.numpy.random as npr
from autograd import grad, elementwise_grad
import matplotlib.pyplot as plt4.2 多層ニューラルネットワークの実装
多層ニューラルネットワークのアーキテクチャを実装する前に、隠れ層の活性化関数 tanh を実装しましょう。ReLU関数のかわりにtanh関数を用いているのは、常微分方程式の解が微分可能であることを仮定しているからです。tanh関数は次のように定義できます。
$$
\tanh(z) = \displaystyle\frac{\exp(z)-\exp(-z)}{\exp(z)+\exp(-z)}
$$
# tanh関数
def tanh(z):
return (np.exp(z)-np.exp(-z))/(np.exp(z)+np.exp(-z))時刻に対応する変数 $${t}$$ の値を入力して、関数 $${x(t)}$$ を出力するようなニューラルネットワークを準備します。アーキテクチャには、隠れ層を一層だけ持つ多層ニューラルネットワークを用います。
# 多層ニューラルネットワーク
def mlp(t, w):
# 隠れ層・出力層のパラメータの取得
w_hidden = w[0]
w_output = w[1]
# 時刻tを同時に入力できるようにする
n_points = np.size(t)
t = t.reshape(-1, n_points)
inputs = np.concatenate((np.ones((1, n_points)), t), axis = 0)
# 隠れ層の計算
z_hid = np.matmul(w_hidden, inputs)
hiddens = tanh(z_hid)
hiddens = np.concatenate((np.ones((1, n_points)), hiddens), axis = 0)
# 出力層の計算
outputs = np.matmul(w_output, hiddens)
return outputs4.3 ニューラルネットワークを用いた解の表示
第3章の説明に従い、ニューラルネットワークを用いた解の表示の実装を与えます。以下に数式を再掲します。
$$
x(t;w) = 1 + tg(t;w)
$$
# ニューラルネットワークを用いた解の表示
def solution(t, w):
return 1 + t*mlp(t, w)4.4 損失関数の実装
第3章の説明に従い、損失関数を実装します。以下に数式を再掲します。
$$
L(w) = \displaystyle\frac{1}{n}\sum_{i=1}^{n}\left(x'(t_i;w)+2t_ix(t_i;w)\right)^2
$$
# 損失関数(ODE損失)
def loss(w, t):
dx = elementwise_grad(solution, 0)(t, w) # x'(t;w)
err = (dx + 2.0*t*solution(t, w))**2 # (x'(t;w)+2tx(t;x))^2
return err.mean()4.5 勾配降下法の実装
一般的な勾配降下法の定義にならって実装します。以下に、勾配降下法によるパラメータ $${w}$$ の更新式を掲げます。$${\lambda}$$ は学習率とよばれ、分析者が正の実数を設定します。また、$${L(w)}$$ は4.4節で掲げた損失関数です。
$$
w_{k+1}\leftarrow\displaystyle w_k-\lambda\frac{\partial L}{\partial w}(w_k)
$$
# 勾配降下法
def gradient_descent(t, n_hidden, n_iter, lr):
# 隠れ層と出力層のパラメータの初期値を決める
w0_init = npr.randn(n_hidden, 2)
w1_init = npr.randn(1, n_hidden+1)
w = [w0_init, w1_init]
# 勾配降下法の計算
dloss = grad(loss, 0) # 導関数 ∂L/∂w
for i in range(n_iter):
g = dloss(w, t) # wでの勾配ベクトル
w[0] = w[0] - lr * g[0] # 勾配降下法の更新式
w[1] = w[1] - lr * g[1]
#print(f"loss: {loss(w, t)}") # 損失の値をログで出力したい場合
return w4.6 常微分方程式の解の計算
これまでにコーディングした関数を用いて、第2章で掲げた例題の常微分方程式の数値解を求めてみましょう。数値解を求めるには、以下のハイパーパラメータを事前に設定しておく必要があります。
# ハイパーパラメータの設定
n_pts = 100 # tの値を離散化するときの個数
n_hidden = 100 # 隠れ層のunitの個数
n_iter = 10000 # 勾配降下法の繰り返しの回数
lr = 0.001 # 勾配降下法の学習率準備が整ったので、数値解を求めます。
# 解の計算
t = np.linspace(-1.5, 1.5, n_pts) # 離散化した時刻t
w = gradient_descent(t, n_hidden, n_iter, lr) # 求めたパラメータの値解いた結果を確認するため、以下のようにグラフに表示します。
# 解をグラフに表示する
x_mlp = solution(t, w) # ニューラルネットワークを用いた解
x_exact = np.exp(-t**2) # 手計算で求めた厳密な解(参考: 第2章)
plt.plot(t, x_mlp.reshape(-1), label = "mlp")
plt.plot(t, x_exact, label = "exact")
plt.legend()
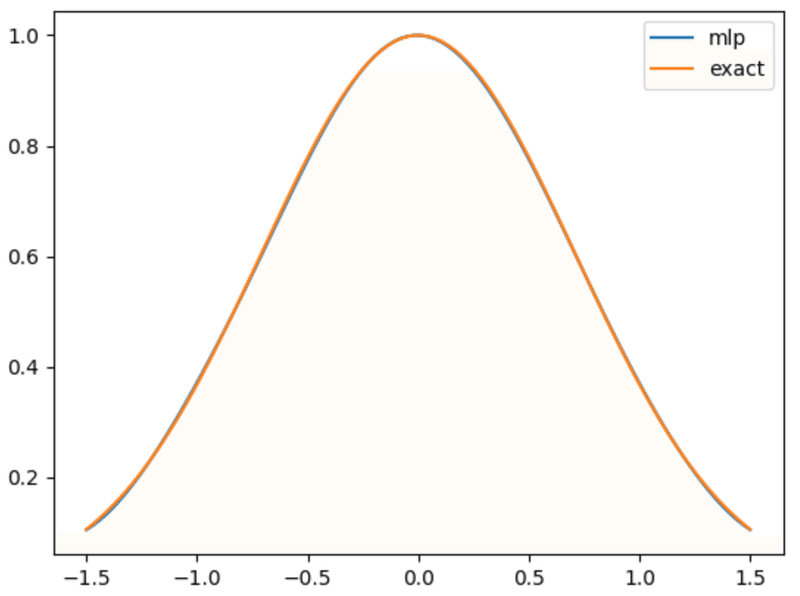
plt.show()結果は以下のようになり、ニューラルネットワークを用いて正しい解が得られていることが確認できます。
Remark 実は、同様にして波動方程式のような偏微分方程式の数値解も計算できます。
Acknowledgement
このnoteは2023年 微分方程式アドベントカレンダーへの投稿です。作成者の京大微分方程式サークルさんに感謝申し上げます。
サポートをいただいた場合、新たに記事を書く際に勉強する書籍や筆記用具などを買うお金に使おうと思いますm(_ _)m