
Photo by
tenohiradesign
ChatGPTでスクレイピング

本格的なスクレイピングはできないけれど単一のURLから情報を抜き出すことはできる。
ChatGPT-4(Web Browsing)の場合は簡単でURLと抜き出したい情報を入れればOK。ただしかなり時間がかかるので、自分でプログラム書いたほうが早いかと思います。
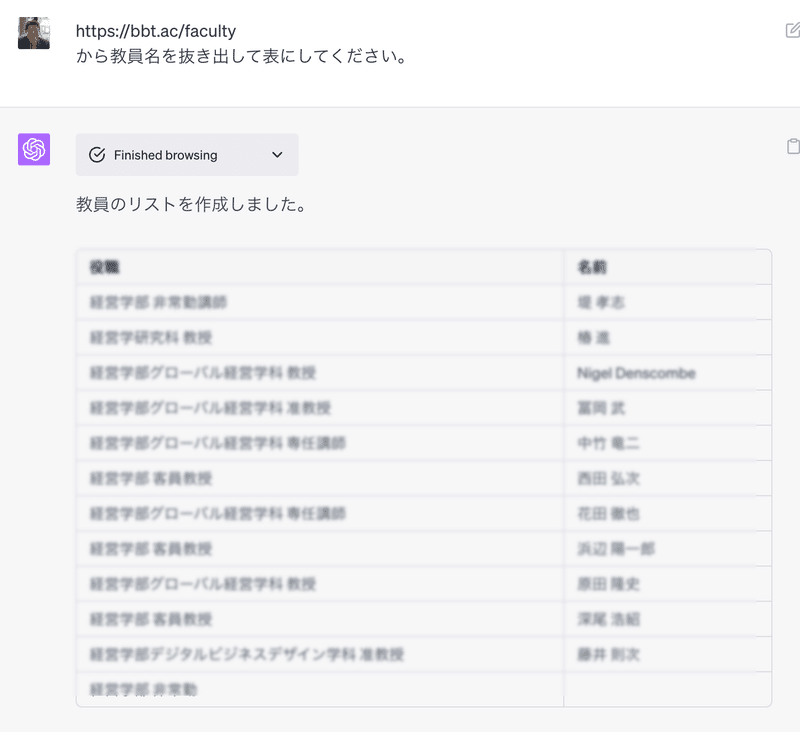
ChatGPT-3.5の場合はWeb Browsingの機能がないのでHTMLのソースを貼り付ける必要がある。

ChatGPT-4でスクレイピングを実施し、Google Colabで実行可能なコードをリクエストするとコードを出力してくれるけれど、そのままではではうまく行かない。このようなときはChatGPT‐3.5で使ったHTMLのソースをもとにまずは動くサンプルを作る。
from bs4 import BeautifulSoup
html_code = '''
<div class="fThum">
<a href="https://bbt.ac/faculty/kenichi-omae.html">
<div class="fThum-img">
<picture>
<source media="(min-width: 480px)" srcset="https://bbt.ac/wp-content/uploads/2021/06/193ef1315ff58e598669eedb1c47bea2-552x290.jpg 1x, https://bbt.ac/wp-content/uploads/2021/06/193ef1315ff58e598669eedb1c47bea2-1104x580.jpg 2x" alt=""" />
<img src=" https://bbt.ac/wp-content/uploads/2021/06/193ef1315ff58e598669eedb1c47bea2-960x504.jpg" alt="" />
</picture>
</div>
<div class="fThum-txt">
<div class="fThum-yaku">学長</div>
<div class="fThum-kata"></div>
<h4 class="fThum-name">大前 研一</h4>
</div>
</a>
</div>
<li class="facInd-item">
<div class="fThum">
<a href="https://bbt.ac/faculty/tatsuaki-ohara.html">
<div class="fThum-img">
<picture>
<source media="(min-width: 480px)" srcset="https://bbt.ac/wp-content/uploads/2021/06/a61b20f270cba4ec47a8d85f069399d9-1-552x291.jpg 1x, https://bbt.ac/wp-content/uploads/2021/06/a61b20f270cba4ec47a8d85f069399d9-1-1104x581.jpg 2x" alt=""" />
<img src=" https://bbt.ac/wp-content/uploads/2021/06/a61b20f270cba4ec47a8d85f069399d9-1-960x505.jpg" alt="" />
</picture>
</div>
<div class="fThum-txt">
<div class="fThum-yaku">経営学部長/グローバル経営学科長</div>
<div class="fThum-kata">経営学部グローバル経営学科 教授</div>
<h4 class="fThum-name">大原 達朗</h4>
</div>
</a>
</div>
</li>
<!--他の教員情報も同様に追加-->
'''
soup = BeautifulSoup(html_code, 'html.parser')
faculty_list = []
items = soup.find_all('h4', class_='fThum-name')
for item in items:
faculty_list.append(item.text.strip())
print(faculty_list)
ChatGPT-4から生成したコードは次の通り。
# 必要なライブラリをインストールします
!pip install beautifulsoup4 requests
# ライブラリをインポートします
import requests
from bs4 import BeautifulSoup
import pandas as pd
# データを取得するURL
url = "https://bbt.ac/faculty"
# requestsを使用してウェブページを取得します
response = requests.get(url)
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# 教員名と役職を含む要素をすべて抽出します
faculty_elements = soup.find_all('a', {'class': 'faculty-name'})
# 教員名と役職を格納するリストを初期化します
faculty_list = []
# 各要素から教員名と役職を抽出し、リストに追加します
for element in faculty_elements:
role = element.find('div', {'class': 'faculty-role'}).text.strip()
name = element.find('div', {'class': 'faculty-name'}).text.strip()
faculty_list.append([role, name])
# リストをPandasのDataFrameに変換します
faculty_df = pd.DataFrame(faculty_list, columns=['役職', '名前'])
# DataFrameを表示します
print(faculty_df)
このコードは実行してもHTMLのタグの指定がうまく行っていないので、3.5で出力したときのコードと組み合わせる。最終的な簡易コードは次の通り。
# 必要なライブラリをインストールします
!pip install beautifulsoup4 requests
# ライブラリをインポートします
import requests
from bs4 import BeautifulSoup
import pandas as pd
# データを取得するURL
url = "https://bbt.ac/faculty"
# requestsを使用してウェブページを取得します
response = requests.get(url)
# BeautifulSoupオブジェクトを作成します
soup = BeautifulSoup(response.text, 'html.parser')
# 教員名と役職を含む要素をすべて抽出します
items = soup.find_all('h4', class_='fThum-name')
faculty_list = []
for item in items:
faculty_list.append(item.text.strip())
# リストをPandasのDataFrameに変換します
faculty_df = pd.DataFrame(faculty_list, columns=['名前'])
# DataFrameを表示します
print(faculty_df)
この記事が気に入ったらサポートをしてみませんか?