
各要因の影響や、要因の組み合わせの影響を確かめる。(手段として交互作用項を導入し重回帰分析を使う)

Plan & Do

【解答】
もちろんです。
まず、必要なライブラリをインポートします:
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf次に、DataFrameを作成します:
# データの準備
data = {
"joint_type": [1, 2, 3, 1, 2, 3, 1, 2, 3, 2, 1, 3, 2, 1, 3]*10,
"bone_type": [1, 2, 3, 1, 2, 3, 2, 3, 1, 1, 2, 3, 3, 2, 1]*10,
"fascia_type": [1, 2, 3, 2, 3, 1, 1, 3, 2, 3, 2, 1, 1, 3, 2]*10,
"damage": [1, 2, 3, 2, 3, 4, 3, 4, 2, 2, 3, 1, 3, 4, 2]*10,
}
df = pd.DataFrame(data)これらのカテゴリ変数をダミー変数に変換します:
# ダミー変数化
df = pd.get_dummies(df, columns=["joint_type", "bone_type", "fascia_type"], drop_first=True)次に、重回帰分析を行い、交互作用項を導入します:
# 重回帰分析
model = smf.ols(formula='damage ~ joint_type_2 + joint_type_3 + bone_type_2 + bone_type_3 + fascia_type_2 + fascia_type_3', data=df)
result = model.fit()
# 交互作用項の導入
df['interaction'] = df['joint_type_2'] * df['bone_type_2']
model = smf.ols(formula='damage ~ joint_type_2 + joint_type_3 + bone_type_2 + bone_type_3 + fascia_type_2 + fascia_type_3 + interaction', data=df)
result = model.fit()最後に、分析結果を表示します:
# 結果の表示
print(result.summary())上記のコードにより、より多くのデータを含むデータセットでの重回帰分析と交互作用項の導入が可能になります。なお、Pythonのコードはデータの前処理や分析手法に応じて様々に変更することができますので、目的に応じて適宜修正してください。
(参考)ダミー変数とは
カテゴリーデータ(特に名義尺度のもの)は、それ自体では線形モデルで直接的に使うことは難しいです。そこでカテゴリーデータを数値化するための一般的な手法として、ダミー変数化(またはワンホットエンコーディング)が用いられます。
ダミー変数化とは、カテゴリーデータの各カテゴリを新たなバイナリ(0または1)の変数として表現し直すことを言います。例えば、「関節のタイプ」については、「Type1」「Type2」「Type3」の3つのカテゴリがあります。ダミー変数化を行うと、「関節のタイプ」は「Type1であるかどうか」「Type2であるかどうか」「Type3であるかどうか」を示す3つの新しい変数に置き換えられます。
これにより、カテゴリーデータを線形モデルで用いることができるようになります。具体的には、ダミー変数化されたデータを用いて重回帰分析を行い、各カテゴリが目的変数にどの程度影響を及ぼすかを調査することができます。
なお、ダミー変数化によって生成される変数の数はカテゴリの数よりも1つ少なくすることが一般的です。これは、完全な多重共線性(すべてのダミー変数の合計が常に一定になるという問題)を避けるためです。このため、「Type1」「Type2」「Type3」の3つのカテゴリを持つ変数をダミー変数化するときには、実際には2つのダミー変数が生成されます(例えば、「Type2であるかどうか」「Type3であるかどうか」)。ダミー変数が0の場合、それは参照カテゴリ(この例では「Type1」)であると解釈されます。
(参考)名義尺度データをダミー変数化しないとどう言った問題があるか
カテゴリカルな変数をダミー変数化せずに、数値データとしてそのまま利用する研究者がいることは確かにあります。しかしこれは、ある程度の注意が必要なアプローチであり、その理由は以下の通りです:
意味の解釈:カテゴリカル変数は、そのカテゴリの値が順序や規模を持たないため、これを数値として扱うことで、その意味が変わってしまう可能性があります。例えば、「関節のタイプ」の「Type1」、「Type2」、「Type3」があったとしましょう。これらを1、2、3という数値で表現すると、「Type2」は「Type1」の2倍、「Type3」は「Type1」の3倍であるという意味になってしまう可能性があります。しかし実際には、それぞれが全く異なるカテゴリを表している可能性があります。
数学的な誤解:数値として表現されたカテゴリカル変数をそのまま重回帰分析などのモデルに入れると、モデルはこれらの数値が等間隔である(つまり、カテゴリ間の「距離」が等しい)と仮定します。しかし、カテゴリカルデータでは、これは通常成り立ちません。
予測の偏り:カテゴリカル変数を数値データとしてモデルに入れると、モデルの予測が偏る可能性があります。ダミー変数化を行うと、各カテゴリが目的変数に与える影響を個別に評価でき、より正確なモデルを構築することが可能です。
したがって、カテゴリカル変数を適切に扱うためには、ダミー変数化を行うことが一般的に推奨されています。
Check
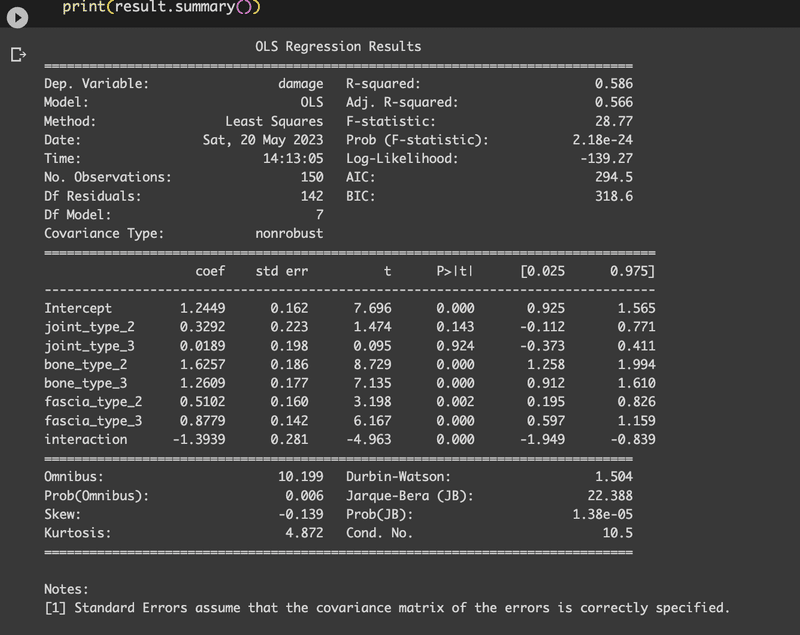

【解答】
ここで得られた結果を解釈すると:
R-squaredは0.586です。これは、あなたのモデルがデータの約58.6%の変動を説明していることを意味します。つまり、このモデルはある程度データを説明しているものの、まだ壊れ具合に影響を与える他の要因が存在する可能性があります。
F-statisticとその対応するp値(Prob (F-statistic))はモデル全体の有意性を示しています。ここではp値が非常に小さい(2.18e-24)ため、モデル全体が統計的に有意であると言えます。
個々の係数(coef)は各変数の影響を示します。例えば、`bone_type_2`の係数は1.6257で、p値が0.000(つまり有意)です。これは`bone_type_2`が`damage`に対して有意な正の影響を与えていることを意味します。同様に、`fascia_type_3`も有意な正の影響を持っています。
交互作用項(interaction)は`joint_type_2`と`bone_type_2`の組み合わせの影響を示しています。この係数は-1.3939で、p値が0.000(つまり有意)です。これは、`joint_type_2`と`bone_type_2`が組み合わさった時、その組み合わせが`damage`に対して有意な負の影響を与えることを示しています。
なお、`std err`は各係数の標準誤差を示し、`[0.025 0.975]`は各係数の95%信頼区間を示しています。これは係数の推定値がどれくらい正確かを示す指標で、信頼区間が0を含まない場合、その係数は統計的に有意と解釈できます。
最後に、すべての結果はサンプルデータに基づいています。したがって、異なるデータセットに対しては、結果も異なることに注意してください。また、これらの分析結果は関連性を示しているだけで、因果関係を示しているわけではないことにも注意が必要です。
Act

このモデルの結果から生じる可能性のある問いは以下の通りです:
他の可能な交互作用は何か? 現在、モデルは`joint_type_2`と`bone_type_2`の交互作用のみを考慮しています。他の交互作用(例えば、`joint_type`と`fascia_type`、`bone_type`と`fascia_type`の組み合わせなど)が壊れ具合にどのような影響を及ぼすのかを調査すると、更に多くの情報が得られるかもしれません。
データには他にどのような影響を与える可能性のある変数が存在するのか? 現在のモデルは関節のタイプ、骨のタイプ、筋膜のタイプのみを考慮していますが、他に影響を与える可能性のある変数が存在するかもしれません。例えば、年齢、性別、生活習慣、健康状態などが壊れ具合に影響を与える可能性があります。
モデルの精度はどの程度向上するのか? 現在のモデルのR-squaredは約0.586で、データの約58.6%の変動を説明しています。モデルを改善するためには、どのような手法が考えられるのか?
これらの問いに対応するために、以下のような分析手法が考えられます:
交互作用項の追加: 現在のモデルに更なる交互作用項を追加することで、他のタイプの組み合わせが壊れ具合にどのような影響を与えるのかを調査することができます。
新しい変数の追加: モデルに新しい説明変数を追加することで、それが壊れ具合にどのような影響を与えるのかを調査することができます。新しい変数を追加する前に、それが壊れ具合と関連性があるかどうかの初期分析(例えば、相関分析)を行うことも有用です。
モデルの改善: 現在は線形回帰モデルを使用していますが、他の種類のモデル(例えば、決定木、ランダムフォレスト、勾配ブースティング
マシンなど)を試すことも一つの選択肢です。これらのモデルは非線形の関係を捉える能力があり、場合によっては精度の向上につながるかもしれません。
なお、これらの手法を試す際には、過学習を避けるために交差検証(cross-validation)などの手法を利用することが推奨されます。また、新たな変数やモデルを追加すると、解釈の難易度が上がる可能性もあることに注意が必要です。
この記事が気に入ったらサポートをしてみませんか?