
生成AIと法律問題 -vol.5-著作権法③

こんにちは!
生成AIを使う際に生じる法律問題を、自分の頭の整理も兼ねて簡単に説明しています。
2024年3月19日に、文化庁の著作権分科会から、「AIと著作権に関する考え方について」が発表されました。
文化審議会著作権分科会(第69回)(第23期第2回)
AI と著作権に関する考え方について
https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/bunkakai/69/pdf/94022801_01.pdf
こちらは、2023年12月に発表された素案から、パブリックコメントを経て、報告という形でまとめられたものになります。
こちらの詳説も追々していきたいなと思っておりますが、まずは、今までのブログの続きへの引用という形で触れたいと思います。
以下、2024年3月15日版の「AIと著作権に関する考え方について」を、「考え方」といいます。
生成AIと関連する著作権法上の論点は以下のとおりです。
1 著作者・著作権者
2 著作物性
・プロンプトの著作物性
・ 生成物の著作物性
3 著作物の利用
・学習モデル構築における著作物の利用(著作権法30条の4)
・生成物による既存の著作物の著作権侵害
4 著作者人格権
前回は、上記「2 著作物性」について解説しました。
今回は、上記「3 著作物の利用―学習モデル構築における著作物の利用」について解説していきます。
3 著作物の利用―学習モデル構築における著作物の利用
(1) 前提
① 利用行為
著作権は、他人による無許諾の著作物の利用を禁止する効力を持っています。
著作権者は、自己が著作権を有する著作物を無許諾で利用する人に対して、著作権侵害を理由として、差止請求や、損害倍書請求をすることができます。
「利用」行為の内容は、著作権法21条~27条に列挙されています。複製、上演、上映、公衆送信、口述…翻案などです。
② 権利制限規定
著作権法21条~27条の利用行為であっても、著作権法の権利制限事由(法30条以下)に該当する場合は、著作権侵害は成立しません。
これらは、著作権者の著作権が制限される(著作権者の著作権を制限する)規定なので、「権利制限規定」と呼ばれます。
私的使用のための複製(法30条)、図書館等における複製(31条)、教育・試験のための利用(33条)などが有名な権利制限規定かと思います。
利用行為と権利制限規定の関係はこんな感じ。
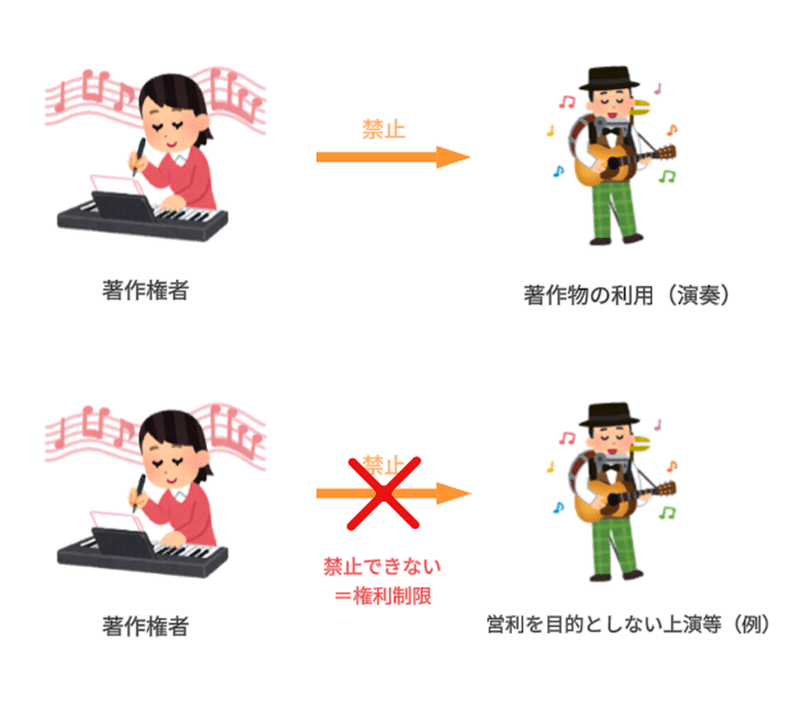
そして、生成AIが関わるのは、このうち、「著作物に表現された思想または感情の享受を目的としない利用」(30条の4)と、「電子計算機による情報処理及びその結果の提供に付随する軽微利用」(47条の5)です。
(2) 生成AIの場面における著作物の「利用」と「権利制限」
① 著作物の「利用」
まず、生データを加工して、学習用データセットを作成する行為、及び、これらを学習用プログラムに入力する行為は、いずれも著作物の複製(法21条)に該当します(他にも、既存の学習済みモデルに対する追加的な学習、検索拡張生成(RAG)において、生成AIへの指示・入力に用いるためのデータベースの作成も、複製に該当します(考え方5(1)ア(ウ))。)。
また、作成した学習用データセットをウェブ上で公開する行為は、著作物の公衆送信(23条1項)に該当します。
複製、公衆送信はいずれも著作物の利用行為になりますので、原則として、利用のためには著作権者の許諾が必要となります。
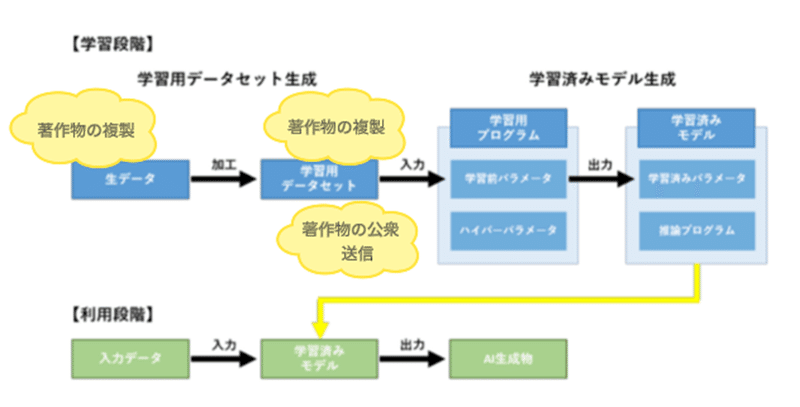
大規模言語モデルでは、大量の著作物が学習用データとなりますので、これら全てについて個別に著作権者から許諾を得るのは非現実的です。
そこで、このような学習用データの加工や入力については、権利制限規定である著作権法30条の4や、47条の5に基づき、著作権者の権利が制限されることになります。
② 著作権法30条の4
著作権法30条の4の条文は以下のとおりです。
第30条の4(著作物に表現された思想又は感情の享受を目的としない利用)
著作物は、次に掲げる場合その他の当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合には、その必要と認められる限度において、いずれの方法によるかを問わず、利用することができる。ただし、当該著作物の種類及び用途並びに当該利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 著作物の録音、録画その他の利用に係る技術の開発又は実用化のための試験の用に供する場合
二 情報解析(多数の著作物その他の大量の情報から、当該情報を構成する言語、音、影像その他の要素に係る情報を抽出し、比較、分類その他の解析を行うことをいう。第四十七条の五第一項第二号において同じ。)の用に供する場合
三 前二号に掲げる場合のほか、著作物の表現についての人の知覚による認識を伴うことなく当該著作物を電子計算機による情報処理の過程における利用その他の利用(プログラムの著作物にあつては、当該著作物の電子計算機における実行を除く。)に供する場合
30条の4を翻訳すると、(i)1~3号の場合を含む「当該著作物に表現された思想又は感情を自ら享受し又は他人に享受させることを目的としない場合」(以下、「非享受目的の場合」といいます。)で、(ii)著作権者の利益を不当に害しない場合に、著作権者の許諾なく、著作物を利用することができるということです。
以下、(i)(ii)のそれぞれの論点を解説します。
(i) 非享受目的の場合
なぜ非享受目的の場合は、原則として自由に著作物を利用できるのでしょうか。
著作物の価値は、著作物に表現された思想や感情を享受することの対価、つまり、ピンクの豚の絵を描いて、それを見た人が「ピンクの豚だ、かわいいな~」と思うことに、著作物としての価値があるということです。
人々がその絵を「ピンクの豚の絵だ」と思わないような、そう思わせることを目的としないような利用形態は、少なくとも著作権法が保護する利用形態ではありません。
そのため、その著作物に表現された思想や感情を享受する目的ではない場合、つまり「非享受目的」での利用(技術開発のために使うだけ、大量の情報を解析するために使うだけとか)には著作権者への保護が及ばず、自由にすることができるのです。
AI学習のための著作物の複製・公衆送信は、基本的に2号(情報解析の用に供する場合)にあたるとされています(考え方5(1)イ(ア))。ただし、「非享受目的」でない場合は、2号も満たさないので、著作物の無断利用は許されません。
そして、著作物の思想・感情を享受する目的(享受目的)と非享受目的が併存している場合は「非享受目的」であると言えません。利用目的のうちに一つでも享受目的がある場合、「非享受目的」とは言えないのです(考え方5(1)イ(イ))。
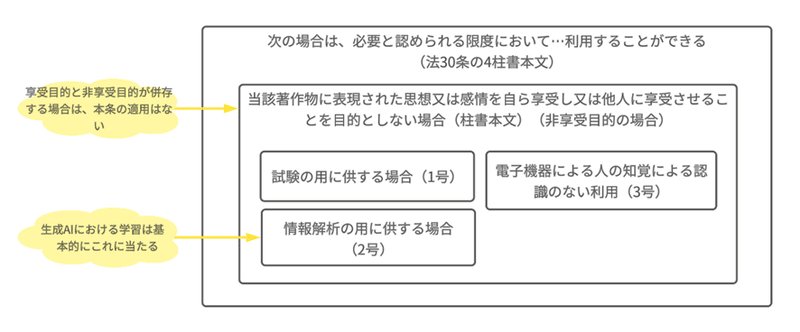
享受目的と非享受目的が併存するのは、以下のような場合をいいます(※注釈は筆者による)。
既存の学習済みモデルに対する追加的な学習のうち、意図的に、学習データに含まれる著作物の創作的表現の全部又は一部を出力させることを目的とした追加的な学習を行うため、著作物の複製等を行う場合。
この例として、「意図的に過学習を行うこと」が挙げられています。が、過学習は一般的に失敗であり、過学習を行わせたモデルを用いたサービスを作る意味はなく、実際にそのようなサービスはないと思います。
そのため、AI事業者が(著作権法の潜脱目的以外に)意図的に過学習を行わせることが実際にあるのかは謎です。
既存のデータベースやインターネット上に掲載されたデータに含まれる著作物の創作的表現の全部又は一部を、生成AIを用いて出力させることを目的として、これに用いるため著作物の内容をベクトルに変換したデータベースを作成する等の、著作物の複製等を行う場合
この例として、検索拡張生成(RAG)が挙げられています(考え方5(1)イ(ウ))。2024年3月15日版の考え方では、素案の段階よりもかなり詳しくこの解説がなされています。
RAGは、「生成AIによって著作物を含む対象データを検索し、その結果の要約等を行って回答を生成する手法」の一つとして挙げられています。なんじゃそりゃ。
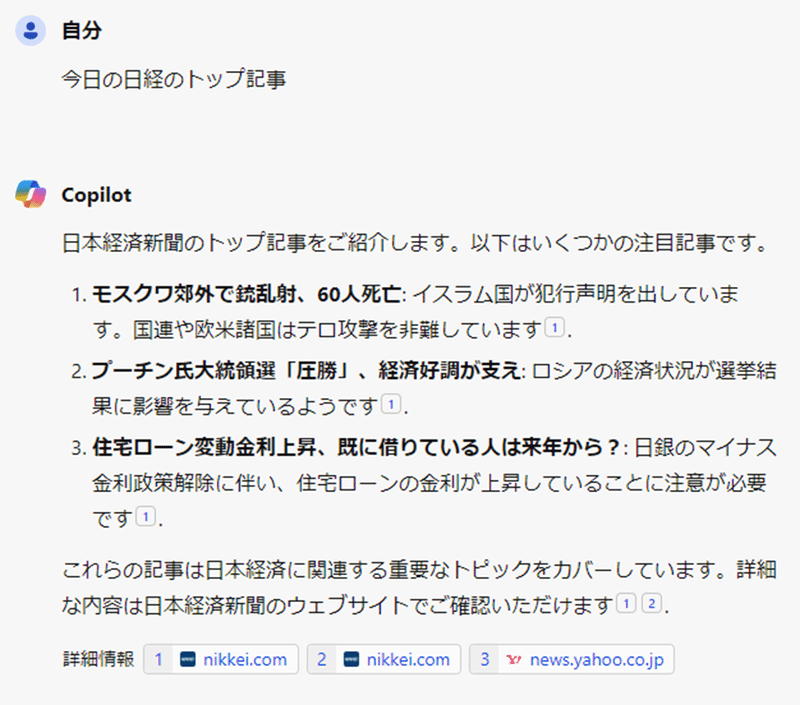
たとえば、Microsoft Copilot(Chat GPTを導入した文章テキストの生成AI)で、「今日の日経のトップ記事」と入力すると、以下のような回答があります。
ちなみに、Chat GPTで同じことを聞いても答えてくれません。

Copilotは、ChatGPTと違い、Bing(検索エンジンの一種)検索を使った検索拡張生成(RAG)を利用しており、インターネット上の情報から回答を生成しています(ユーザが入力したプロンプトに応じて自動的にBing検索を行い、その検索結果をも結果もプロンプトとして自動入力しています。)。
そのため、質問時点でインターネット上に掲載されている情報をもとに回答を生成することができます。
Copilotは検索対象をインターネットとしていますが、検索対象を社内文書とすることもできます。社内文書の検索を容易にする目的で、RAGを使用した自社サービスを作成している会社もあります。
これが「生成AIによって著作物を含む対象データを検索し、その結果の要約等を行って回答を生成する手法」です。
そして、考え方は、「インターネット上に掲載されたデータに著作物が含まれる場合であって、著作物の内容をベクトルに変換したデータベースの作成等に伴う著作物の複製等(※Copilotの上記回答の際に行われる追加のデータ学習のことです)が、生成に際して、当該複製等に用いられた著作物の創作的表現の全部又は一部を出力することを目的としたものである場合には、当該複製等は、非享受目的の利用行為とはいえず、法第30条の4は適用されないと考えられる」としています(考え方5(1)ウ)。
たとえば、Copilotの上記1つめの回答の元データは以下だと思われます。
・モスクワ郊外で銃乱射、60人死亡 イスラム国が犯行声明
・国連や欧米「テロ攻撃を非難」 モスクワ郊外の銃乱射で
Copilotが生成した回答(要約)は、上記2記事に「ですます」を付けてくっつけているだけなので、「著作物(日経の上記2記事)の創作的表現の全部又は一部を出力することを目的とした」と言える可能性があります。ただし、一般的に記事のタイトルだけでは「著作物」に当たらないため(知財高判平成17.10.6〔読売オンライン事件〕)、Copilot(Microsoft)としては適法であると整理している可能性もあります。
一方で、回答にあたり元となるウェブサイトの表現をそのまま回答に用いてしまうこともあるかと思います。この場合学習は、非享受目的の利用行為とはいえず、法第30条の4は適用されないことになります。
このような難しい例でなくとも、
例えば、有名キャラクターの画像1枚をプロンプトに入れて画像を生成する場合など、元の画像がある程度反映されたコンテンツを、閲読・鑑賞等に利用することを想定してプロンプトとして入力する場合も、享受目的があると言えそうです(福岡真之介「ユースケースにみるAlコンテンツ生成に対する内部規約の要点」(ビジネス法務2023.11))。
(ii)著作権者の利益を不当に害しない場合
「著作権者の利益を不当に害することとなる場合」か否かは、著作権者の著作物の利用市場と衝突するか、あるいは将来における著作物の潜在的市場を阻害するかという観点から判断されることになります(考え方5(1)エ(ア))。
ここで、クリエイター側がよく主張している、「作風を特定のクリエイターに寄せた画像生成AIが出てきてしまったら、寄せられたクリエイターの作品が売れなくなってしまう。」という主張は、「作風や画風を流用するための学習について、上記30条の4の但書に該当する場合として、30条の4による権利制限が適用されない(=自由に使ってはいけない)と解するべきである」という主張と整理できます。
しかし、そもそも、作風や画風といったアイデア等が類似するにとどまり、既存の著作物との類似性が認められない生成物は、これを生成・利用したとしても、既存の著作物との関係で著作権侵害とはなりません。
この点については、考え方も以下のとおり述べています。
著作権法が保護する利益でないアイデア等が類似するにとどまるものが大量に生成されることにより、特定のクリエイター又は著作物に対する需要が、AI生成物によって代替されてしまうような事態が生じることは想定しうるものの、当該生成物が学習元著作物の創作的表現と共通しない場合には、著作権法上の「著作権者の利益を不当に害することとなる場合」には該当しないと考えられる。
素案の段階ではこれ以上のことは書かれていませんでした。しかし、パブコメを通じてクリエイター側からさらなる反論があったことを受けて、考え方では以下のように追記がなされています。
他方で、この点に関しては、本ただし書に規定する「著作権者の利益」と、著作権侵害が生じることによる損害とは必ずしも同ーではなく別個に検討し得るといった見解から、特定のクリエイター又は著作物に対する需要が、AI生成物によって代替されてしまうような事態が生じる場合、「著作権者の利益を不当に害することとなる場合」に該当し得ると考える余地があるとする意見が一定数みられた。また、アイデア等が類似するにとどまるものが大量に生成されること等の事情が、法第30条の4との関係で「著作権者の利益を不当に害することとなる場合」には該当しないとしても、当該生成行為が、故意又は過失によって第三者の営業上の利益や、人格的利益等を侵害するものである場合は、因果関係その他の不法行為責任及び人格権侵害に伴う責任の要件を満たす限りにおいて、当該生成行為を行う者が不法行為責任や人格権侵害に伴う責任を負う場合はあり得ると考えられる(後掲(3)ウも参照)。
作風が同じものが大量に生成される場合であっても、特定のクリエイターの需要が代替されることがあり得、その場合は「著作権者の利益を不当に害することとなる」と言える可能性がありそうです(ただ、「意見が一定数みられた」としているだけなので注意。)(「既存の著作物とアイデア等が類似するが、表現として異なる生成物が市場において取引されたとしても、これによって直ちに当該既存の著作物の取引機会が失われるなど、市場において競合する関係とはならないと考えられる。」としていたので、クリエイターに対する一定の歩み寄りがあったのかなと思います。)。
③ 著作権法47条の5
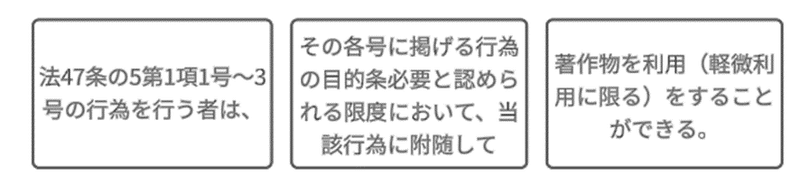
著作権法47条の5第1項1号・2号の条文は以下のとおりです(太字は筆者による。カッコ内は一部省略しています。)。
第47条の5第1項(電子計算機による情報処理及びその結果の提供に付随する軽微利用等)
電子計算機を用いた情報処理により新たな知見又は情報を創出することによつて著作物の利用の促進に資する次の各号に掲げる行為を行う者…は、公衆への提供等…が行われた著作物…について、当該各号に掲げる行為の目的上必要と認められる限度において、当該行為に付随して、いずれの方法によるかを問わず、利用(当該公衆提供等著作物のうちその利用に供される部分の占める割合、その利用に供される部分の量、その利用に供される際の表示の精度その他の要素に照らし軽微なものに限る。以下この条において「軽微利用」という。)を行うことができる。ただし、当該公衆提供等著作物に係る公衆への提供等が著作権を侵害するものであること…を知りながら当該軽微利用を行う場合その他当該公衆提供等著作物の種類及び用途並びに当該軽微利用の態様に照らし著作権者の利益を不当に害することとなる場合は、この限りでない。
一 電子計算機を用いて、検索により求める情報…が記録された著作物の題号又は著作者名、送信可能化された検索情報に係る送信元識別符号…その他の検索情報の特定又は所在に関する情報を検索し、及びその結果を提供すること。
二 電子計算機による情報解析を行い、及びその結果を提供すること。
法47条の5は、法30条の4の「享受目的」がある場合でも、適用することができます。
ただし、その権利制限の範囲は「軽微利用」に限られます。
この規定は、大量の情報を収集し、解析し、そこから新たな情報を抽出することによってさまざまな情報提供サービスが可能となる一方で、そのようなサービスは、そこで利用する著作物を直接提供するものではないので、無許諾での利用を許そう、というものです。
例えば、検索エンジンで検索した結果の表示は、世界中のサイトの情報をクローリングして収集保存、整理、解析して、検索結果(著作物の題号、著作者名、送信元識別符号(URL)等)を公衆送信することになりますが、これらの権利を制限しなければ、その検索エンジンは、許諾が得られたサイトからしか情報を収集できなくなり、不便極まりないことは明らかです。
したがって、軽微利用であれば無許諾で利用可能としたのが、本条です。
Copilotの回答生成が許容されるのは本条が理由なのかもしれないです。が、考え方には法47条の5が適用される場面についての詳しい記載がありませんので、今後適用場面が明らかになるのかなと思います。
(3) まとめ
生成AIの学習段階で問題となる著作権の権利制限規定は、法30条の4及び法45条の7であり、法30条の4では「非享受目的かつ著作権者の利益を不当に害しない」ことが、法45条の7では享受目的がある場合でも「1~3号の行為に該当し、軽微利用である」ことが、適用の要件でした(簡略化しています。)。
考え方では、上記「非享受目的」に該当する場面や、「著作権者の利益を不当に害」する場合に該当する場面について、詳細に述べられていますので、こちらを中心に解説してみました。
次回は、著作物の利用―生成物による既存の著作物の著作権侵害について整理していきます。
それでは今日はこの辺で🐑
めえめえ
この記事が気に入ったらサポートをしてみませんか?