A Brief Introduction to Graph Neural Network(GNN)

Caution
本記事はNeural Networkに関するある程度の知識を前提とします。
とはいえ、ノリは適当です。
筆者が最近独学した内容に基づいているので、説明が正しいという保証はどこにもありません。
以上の点をご理解いただいた上で、エッセイを読むくらいの感覚で読んでいただけると幸いです。
第1章 Convolutional Neural Network(CNN)
Convolutional Neural Network(CNN)を爆速で雑に解説します。まあ、この記事の題名でまんまと引っかかっている皆さんなので、CNNは分娩された瞬間から知っているかもしれませんが、筆者の復習のためにも書かせてください。
Neural Networkの概要
まず、Neural Networkの基本的な仕組みについて雑に解説します。
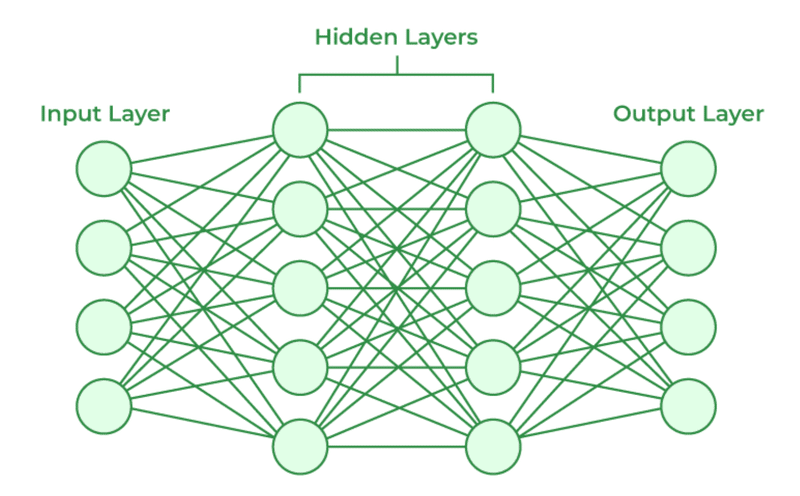
まずは構成について。Neural Networkは「入力層」「中間層」「出力層」の3つの層で構成されています。「入力層」は文字通り、入力に用いるデータの特徴量を格納するニューロンの集団です。「出力層」はそのNeural Networkが出力として返す値を格納するニューロンの集団で、これを用いて回帰や分類を行います。「中間層」は「入力層」と「出力層」をつなぐ、表には出てこない層ですが、入力データが中間層を通過する仮定で、特徴量が巧妙に加工・選択されることで回帰や分類が可能となります。
特に中間層のニューロンではReLU関数やシグモイド関数などの非線形関数による演算(一般に活性化関数と呼ぶ)が施されます。出力層では(モデルの利用目的により違いはあれど)Softmax関数などが使われます。また、各層に属するニューロンは層の間で結合されており、単純に線形和が施されることが一般的です。
次に学習について。Neural Networkにおける「学習」とは、一言で言えば、訓練データに適応するように「重み」と「バイアス」を調整することです。調整の方法は、さまざま有りますが、一番単純で代表的な手法としては、確率的勾配降下法(SGD)があります。また勾配の計算には誤差逆伝播法が用いられます。そして、誤差として定義する損失関数としては交差エントロピー誤差がよく用いられます。
これらを設定した上で、Neural Networkによって出力された結果と、教師データを、損失関数に代入して誤差を計算し、各重みパラメータを勾配方向に微小量更新する、というステップを繰り返すことで学習が行われます。

(補足1)ミニバッチ学習
CNNに進む前に2つほど補足を。まずは、ミニバッチ学習について。
訓練データから無作為に選び出されたデータ(このデータのひとかたまりをミニバッチという)を用いて、ミニバッチごとに学習を行う手法をミニバッチ学習と呼びます。主に、訓練データが大量にあるときに、計算量を減らすのが目的です。
(補足2)Adam
この後で登場するので一応、メモ書き程度に書いておきます。Adamは、一言で言えばSGDの効率性を改良したような最適化手法の一つで、パラメータの更新に用います。他にも似たような最適化手法はたくさん有りますが、あとはみなさんが勝手に調べてください。
Convolutional Neural Network(CNN)の概要
CNNは先のNeural Networkと構成や学習方法に関して、ほとんど変わりませんが、「畳み込み層」と「プーリング層」を組み込んでいるという点が特徴的です。
畳み込み層
そもそもなぜ畳み込みを行うのかというと、先のモデルのように、隣接する層のすべてのニューロン間で結合があるような計算様式(全結合層と呼ぶ)では、入力データの形状など、空間的な大域的情報をうまく反映できません(画像認識などが良い例)。そこで、畳み込みを行うことを通して、入力データの局所的な演算を繰り返し行うことで、大域的情報を反映した特徴量を構成する、という手法が考えられました。
したがって、畳み込み操作は、言わば全結合層における重みパラメータの局所的バージョンと言えます。
畳み込みにはフィルターと呼ばれる配列を用います。フィルターを用いた具体的な計算法は下の図を見てください。また先ほどのNeural Networkにおけるバイアスにあたるものも、フィルター後の特徴マップ全体にスカラーを加算することで実装されています。またフィルタは特徴量の種類ごとに設定することが一般的で、同一種類に対しても複数用意します。

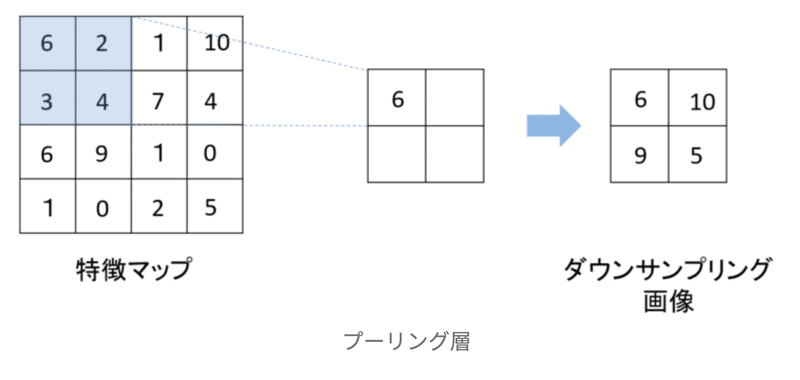
プーリング層
プーリング層は、中間層における特徴マップのサイズを縮小する役割があります。このおかげで、入力データに対するロバスト性がある程度備わります(画像認識の文脈で言えば、入力データのずれみたいなものに対応できる)。プーリングの仕方もさまざまですが、一番代表的なのは、それぞれのウィンドウ(特徴マップ上で一回に考慮する配列のこと)における最大値をそのウィンドウにおける代表値としてそのまま取ってくる手法です。
(補足3)パディング
畳み込み層の処理を行うとデータのサイズが小さくなって、畳み込みを何回か繰り返したら超小さくなるのでは、と思った方もいるでしょう。実用上、サイズを変えたくないという時などには、畳み込みを行う前に、入力データの周囲を固定のデータ(0とか)で囲うことで、データのサイズを調整します。これをパディングと言います。
(補足4)ストライド
フィルターを適用する位置の間隔をストライドと言います。それだけです。要するに畳み込み操作を入力特徴マップに対してどれくらい重複を許すかという値。
具体例で復習
はい。以上でCNNの解説を終わります。多分、前提知識がある人でないと「は?何を言っているんだ、コイツは」となってしまうくらいの、雑さだと思います。ごめんなさい。時間があったら加筆して、初学者でも理解できるように書きますが、多分文章量が倍になります。面倒なので今は書きません。最後に入力データが画像であると仮定してCNNの仕組みをざっと復習しましょう。(主に著者のために)
データセットには10種類のクラスに分類される画像とそのラベル(クラス名)があると仮定します。ピクセル数は100と仮定します(荒すぎるだろ、というツッコミは弾圧します)。画像はカラーの場合、RGB(いわゆる色の3原色)の強さの組み合わせで表されるので、1枚の画像につき100ピクセルのそれぞれにR、G、Bの強さが256段階で与えられています。
バッチ数を64とすると、入力データは4次元配列(バッチ数、特徴量、縦、横)となります。このデータを畳み込むために使うフィルタは4次元配列(縦、横、特徴量(面倒なのでチャンネルと同義として用いている)、フィルタ数)となります。また、バイアスは2次元配列(バイアスの大きさ、特徴量)になります。よって畳み込みによって出力されるデータは4次元配列(バッチ数、縦、横、特徴量)となりますね。
プーリング層に関しては、先の出力データに非線形関数(ReLU関数など)を作用させたデータを入力として使うことを考えましょう(ここでデータサイズに変化はない)。プーリングを施したあとも、4次元配列(バッチ数、特徴量、縦、横)になります。で、CNNでは最後に全結合層とReLU層を何回か挟んで、Softmax関数を施して出力層とするケースが多いです。
この時の全結合層はプーリング後における出力データを、バッチに含まれるデータごとに線型結合するので、その結果は2次元配列(バッチ数、特徴量)となります。それ以降はこの配列のまま出力層までデータが流れます。
第2章 Basis of Graph Theory
ここまでで8000文字に到達してしまいました。この記事はCNNの解説をしたくて書いたわけじゃないのに。。。
気を取り直して、この章ではGNNで用いるグラフ理論の用語について雑に解説します。
ノードとエッジ
グラフを構成する要素は「ノード」と「エッジ」の2つです。ノードが点、エッジがノード同士をつなぐ線というイメージですね。前者が駅、後者が線路みたいな。
グラフの分類の仕方はさまざまですが、例えばエッジに方向性があるかどうかという違いは決定的でしょう。方向性がなく、単に「つながり」だけを考慮するグラフを無向グラフ、エッジに方向性を持たせるものを有向グラフと言います。
またエッジに対して重みを考えるかどうかも重要な点です。重みがあるものは「重みつきグラフ」と言います。ちなみに重みがあって方向性があるグラフは「重みつき有向グラフ」と言います。
また、グラフ$${G}$$は一般に、ノードの集合$${V}$$とエッジの集合$${E}$$の組で表されます。
$$
G=(V,E)
$$
隣接行列
グラフを計算の入力に使う際には、扱いやすい形にする必要があります。その代表格が「隣接行列」です。隣接行列(adjacency matrix)は、ノードの対がグラフ中で接続されているか否かを示す正方行列で、例えば$${i}$$番目のノードと$${j}$$番目のノードとの間にエッジが存在する場合は隣接行列$${A}$$の$${A_{i,y}}$$を1、エッジが存在しない場合は0とします。ゆえに、無向グラフの場合は、その隣接行列は対称行列になります。
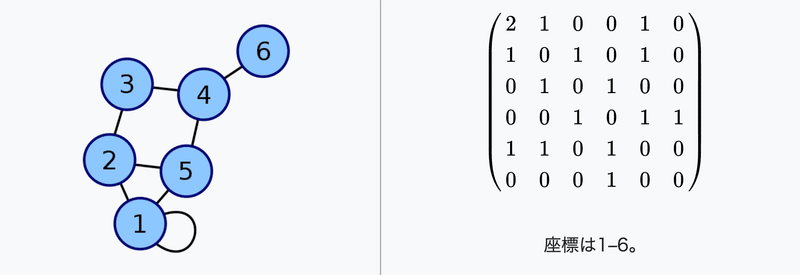
次数行列
それぞれのノードに接続するエッジの数を次数と呼び、$${i}$$番目のノードの次数を行列の$${(i,i)}$$の値とした正方行列を次数行列と呼びます。
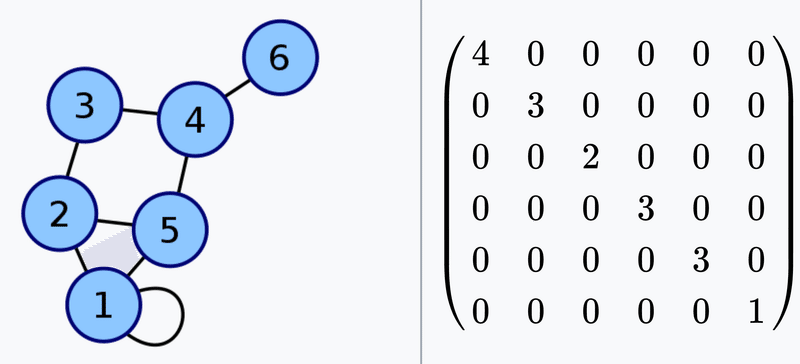
ラプラシアン行列
のちに重要となるのがラプラシアン行列$${L}$$というもので、次数行列$${D}$$と隣接行列$${A}$$を用いて、以下のように定義されます。
$$
L=D-A
$$
これが一体何を表しているのか、ということが気になる方もいると思うが、簡単に言えば、ノードの次数とエッジの入出力に関する情報を全て表現しているというのが特徴です。(他にも数学的な解釈はいろいろできますが、本題ではないので各自で調べてください)

接続行列
これはおまけ程度ですが、最後に接続行列を紹介します。これは、各ノードにおける入出力のエッジの組みを表現した行列となります。無向グラフの場合は、エッジ$${j}$$によって接続されているノードが$${i_1}$$と$${i_2}$$である場合、接続行列$${B}$$の$${(i_1,j)}$$と$${i_2,j}$$の要素が1となります。
ちなみに$${L=BB^{T}}$$が成り立ちます(これが$${L}$$がラプラシアン行列と呼ばれる所以でもある)。
これ以上の解説はこの記事などを参照してください。
第3章 Graph Neural Network
さて、ここまでで既に1万字ですが、ようやくGNNの内容に入っていこうと思います。
まず、GNNとは何なのか、という話ですが、簡単に言えばNeural Networkにおける入力がグラフであるもののことです。
つまり、入力データとして用いるのはグラフの隣接行列(これがグラフの構造を反映しているため)と各ノード(またはエッジも含む)の特徴量(一般にベクトル)の2つです。
GNNでできることはさまざまですが、主に「ノードの分類・回帰」「エッジの分類・回帰」「グラフの分類・回帰」などがあります。
基本的な考え方やワークフローはCNNの時とほとんど変わらないので、ここまで読んでいただいている奇特な方にとっては、習得が容易でしょう。
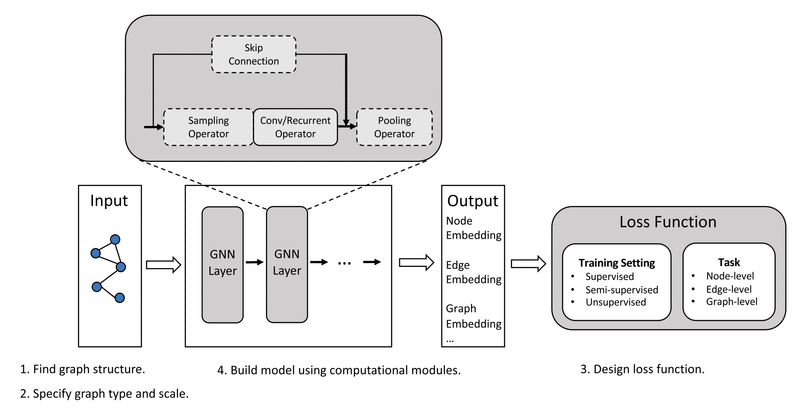
参考までに、CNNのときの例と比較して述べようと思います。例えばCNNの例において、入力として用いた画像データはGNNにおけるグラフになります。画像データの1ピクセルがグラフの1ノードに当たります。また、前者では1ピクセルにつき3つの特徴量(RGB)がありましたが、これがGNNにおいては1ノードに紐付けされている特徴量となります。また、GNNにおける隣接行列は、画像データでいうところのピクセル同士の繋がりに等しく、画像データの場合はメッシュ構造になっているので、縦横斜めの計8つのエッジがあると捉えることができますね。

第4章 Graph Convolutional Neural Network
GNNにおいても、畳み込み操作を考えることが一般的です。
CNNの例では、畳み込み操作はある一定範囲においてフィルタ操作を施すことによりその範囲における特徴量の集計を行いました。
GCN(Graph Convolutional Neural Network;グラフ畳み込みニューラルネットワーク)においても、概念は同じです。グラフにおける情報の流れは、そのグラフ構造に強く依存すると考えられ、あるノードのもつ情報はそのノードに接続している(もしくは近くにある)ノードの持つ情報から影響を受けると考えられます。したがって、各ノードごとでその周辺のノードの(隠れ)特徴量を集計することで、そのノードにおける新たな隠れ特徴量を得るという操作をします。これこそが畳み込みの概念です。
CNNにおけるフィルタは、GCNにおいては、周辺のノードを集計する際の各ノードに対する重みづけに対応します。通常は直接接続しているノードを集計に用いるので、周辺ノード群がCNNにおけるウィンドウ内に属するピクセルに相当します。ゆえに、グラフ上で畳み込み操作を繰り返すことで、グラフ上のより大域的な情報を反映できるようになるということですね。

なんだか、言葉で説明されてもよくわからない、という方もいると思うので、数式で書くとこんな感じです。(こっちの方がわかりにくいという人もいるかも知れない)
ちなみに、一口にGCNと言っても色々な学習則が考案されているので、今回はおそらく一番一般的なKipf & Welling (2017)を紹介します。
$$
H^{(l+1)}=\sigma (\tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2} H^{(l)} W^{(l)})
$$
$${H^{(l)}}$$はl番目のニューラルネットワークの層で、0番目が入力データの特徴量(多次元配列)に相当します。$${\tilde{A}}$$は$${\tilde{A}=A+I}$$で定義され、$${A}$$が入力データの隣接行列、$${I}$$は隣接行列と同じサイズの単位行列を表します。単位行列を入れることで各ノードの現在の情報を次の層における同ノードの情報へ反映させる役割があります。$${W^{(l)}}$$はl番目の層において、周辺ノードの情報をそれぞれどれくらい集計の際に反映させるかという「重み」の配列に相当し、GCNNではこの値を学習させることとなります。$${D}$$は次数行列で、この辺りは掘り下げるとちょっと難しくなるのですが、$${\tilde{D}^{-1/2}}$$で$${\tilde{A}}$$を挟んであげることで、各ノードのスケールを調整しています(正規化)。今はあまり気にしなくていいです。
$${\sigma}$$は活性化関数です。ReLU関数などを適用します。
これがGCNにおける(一般的な)学習則です。GCNではこの学習則を用いて、以下のようなワークフローを組むことでモデルを構築します。
簡単ですね。

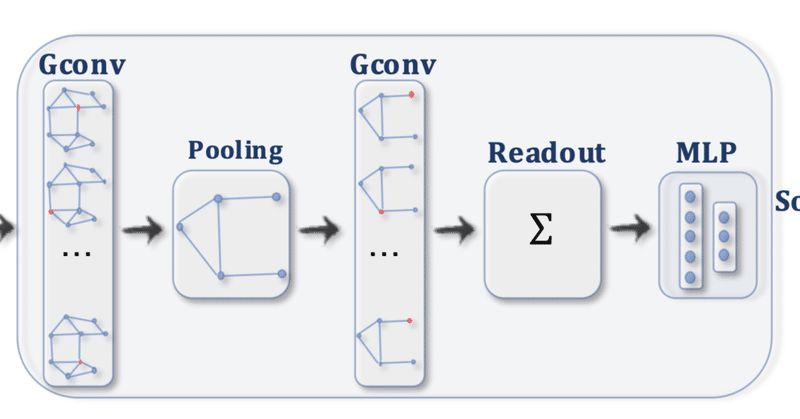
第5章 Self-Attention Graph Pooling
畳み込み層があるということは、プーリング層もあるのでは!?と思ったそこのあなた、鋭いですね。
あります。ありますが、畳み込み層よりは研究があまり進んでいません。CNNの時はPoolingによってロバスト性を得るという目的がありましたが、GNNの場合はあまりそのモチベーションがないからかも知れません。強いて言えば、計算量の削減とかに使えるのかな?(にわかなので、適当に言っています。多分間違っている)
プーリングの代表的な手法はいくつかありますが、今回はSelf-Attention Graph Poolingという手法を紹介します。雑に。
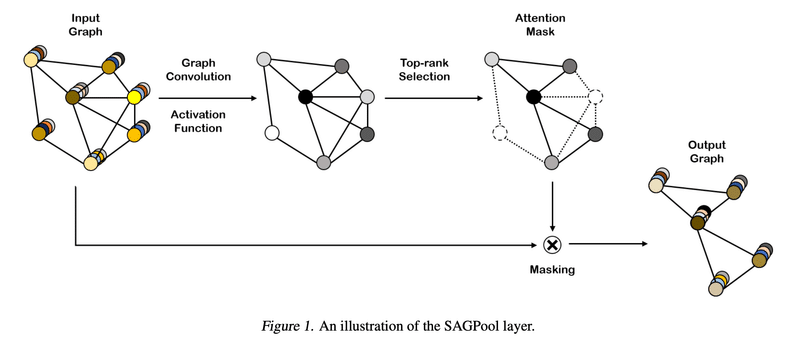
Poolingにはグラフの構造を保つものとそうではないものがあります。今回のSAGPoolは構造を保つタイプです。ざっくり言えば、各ノードに対して重要度スコアを計算し、その上位数十%を採用して、残りを無視して出力を行います。
気になる重要度スコアの計算法に関してですが、これは結構簡単で、先ほどのGCNのアルゴリズムをそのまま援用しています。イメージとしては先ほどの各層における隠れ特徴量に重要度スコアのベクトルを1行加えたという感じですね。
このPoolingは先ほどのGCNの手法と組み合わせて使われます。(下図)
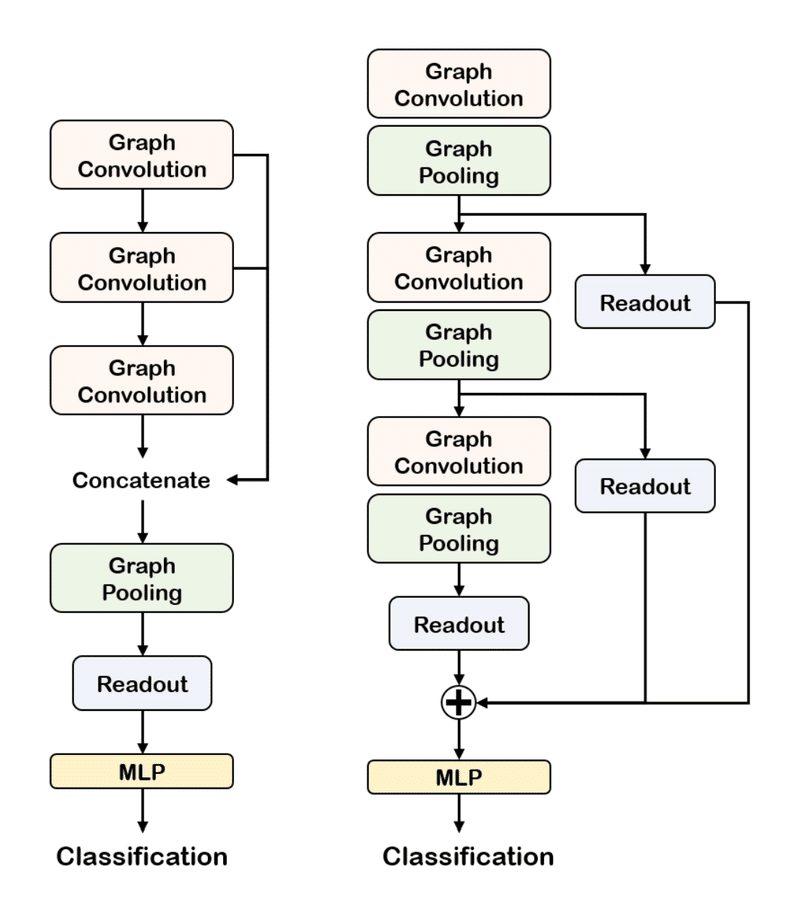
第6章 Pythonによる実装例
実装に関して参考になるのは、こちらです。
これを読んだだけで、即座に実装できる方はもう、これ以降の記述を読んでも、得るものは有りません。今までありがとうございました。
筆者は、機械学習素人なので(最近課金した)GhatGPTくんと相談しながら半日かけて、なんとか実装できました。そこで、備忘録のためにもここにGNNの実装例と簡単な解説を記しておきます。
! pip install torch_geometric
import torch
import torch.nn.functional as F
from torch.nn import Linear
from torch_geometric.nn import GCNConv, SAGPooling, global_mean_pool
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
class GNN(torch.nn.Module):
def __init__(self, num_node_features, num_classes):
super(GNN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, 32)
self.conv3 = GCNConv(32, 64)
self.pool = SAGPooling(64, ratio=0.5)
self.readout = torch.nn.Linear(64, 64)
self.mlp = torch.nn.Sequential(
torch.nn.Linear(64, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, num_classes)
)
def forward(self, x, edge_index, batch):
x = F.relu(self.conv1(x, edge_index))
x = F.relu(self.conv2(x, edge_index))
x = F.relu(self.conv3(x, edge_index))
x, edge_index, _, batch, _, _ = self.pool(x, edge_index, None, batch)
#x = self.readout(x)
x = global_mean_pool(x, batch)
x = self.mlp(x)
x = F.log_softmax(x, dim=1)
return x
dataset = TUDataset(root='/tmp/PROTEINS', name='PROTEINS')
dataset = dataset.shuffle()
train_dataset = dataset[:250]
test_dataset = dataset[250:]
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GNN(dataset.num_node_features, dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # weight_decay=5e-4
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
#for data in train_loader: # Iterate in batches over the training dataset.
for data in train_loader:
out = model(data.x, data.edge_index, data.batch)
loss = criterion(out, data.y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
def test(loader):
model.eval()
correct = 0
for data in loader: # Iterate in batches over the training/test dataset.
out = model(data.x, data.edge_index, data.batch)
pred = out.argmax(dim=1) # Use the class with highest probability.
correct += int((pred == data.y).sum()) # Check against ground-truth labels.
return correct / len(loader.dataset) # Derive ratio of correct predictions.
for epoch in range(1, 1000):
train()
train_acc = test(train_loader)
test_acc = test(test_loader)
print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}, Test Acc: {test_acc:.4f}')まずは最初の数行に関して。
! pip install torch_geometric
import torch
import torch.nn.functional as F
from torch.nn import Linear
from torch_geometric.nn import GCNConv, SAGPooling, global_mean_pool
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoadertorch_geometricのinstallが必要です。
それ以降は必要なパッケージのインポートです。5行目のtorch_geometric.nnに関しては非常に色々なGNNのモデルがモジュールとして用意されているので便利です(詳細は先ほどのURLから)。
この例では畳み込みにGCNConvを、プーリングにSAGPoolを用いています(どちらも原理について、この記事で扱いました)。global_mean_poolは最後のReadOutで用います。
TUDdatasetは、たくさんのDatasetが含まれています。モデルの性能評価に使います。
DataLoaderは、、、まあ、とりあえず、入れておいてください。あとで使います(急に投げやり)。
次。モデルの構築パートです。
class GNN(torch.nn.Module):
def __init__(self, num_node_features, num_classes):
super(GNN, self).__init__()
self.conv1 = GCNConv(num_node_features, 16)
self.conv2 = GCNConv(16, 32)
self.conv3 = GCNConv(32, 64)
self.pool = SAGPooling(64, ratio=0.5)
self.mlp = torch.nn.Sequential(
torch.nn.Linear(64, 32),
torch.nn.ReLU(),
torch.nn.Linear(32, num_classes)
)
def forward(self, x, edge_index, batch):
x = F.relu(self.conv1(x, edge_index))
x = F.relu(self.conv2(x, edge_index))
x = F.relu(self.conv3(x, edge_index))
x, edge_index, _, batch, _, _ = self.pool(x, edge_index, None, batch)
x = global_mean_pool(x, batch)
x = self.mlp(x)
x = F.log_softmax(x, dim=1)
return xGCNというクラスを作っています。__init__(self, num_node_features, num_classes)の部分でパラメータの初期化を行います。
そこから数行はdef forward以下で実際に計算方法を構築するときに使う関数を定義しています。16とか32という数字は隠れ特徴量の次元です。
forward以下はネットワークの計算手順です。GCNConvを3回行った後に、SAGPoolを施し、各特徴量の線形和を計算した後に、特徴量の平均値を取って各ノードの特徴量の代表値とします。最後に、全ノードの全結合を計算して、ソフトマックス関数に代入して、グラフのクラス分類予測値(確率に相当)を計算しているだけですね。
次はデータセットの準備です。まあ、ここは本質的ではないのでいいでしょう。
dataset = TUDataset(root='/tmp/PROTEINS', name='PROTEINS')
dataset = dataset.shuffle()
train_dataset = dataset[:250]
test_dataset = dataset[250:]
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GNN(dataset.num_node_features, dataset.num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # weight_decay=5e-4
criterion = torch.nn.CrossEntropyLoss()datasetを読み込んだら訓練データとテストデータに分割して、それぞれをバッチサイズを指定した上でDataLoaderに渡しています。moleを先ほどのGNNに指定して必要な引数を打ち込みます。最適化手法はAdam、損失関数は交差エントロピー誤差としていますね。
次はいよいよ学習です。
def test(loader):
model.eval()
correct = 0
for data in loader: # Iterate in batches over the training/test dataset.
out = model(data.x, data.edge_index, data.batch)
pred = out.argmax(dim=1) # Use the class with highest probability.
correct += int((pred == data.y).sum()) # Check against ground-truth labels.
return correct / len(loader.dataset) # Derive ratio of correct predictions.データをモデルに入力して、各クラスへの分類(ソフトマックスの値)を出力として受け取り、その正答率を計算しています。
最後。
for epoch in range(1, 300):
train()
train_acc = test(train_loader)
test_acc = test(test_loader)
print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}, Test Acc: {test_acc:.4f}')epochは世代数を表し、学習を何回繰り返すかという値です。今回は適当に300にしています。各世代でのモデルの訓練データでの正答率と、テストデータでの正答率を同時に表示できるようにしてあります。
はい。以上です。詳しいことは先のページを参照してください。
お疲れ様でした。
参考文献・引用一覧
『ゼロから作るDeep Learning』
https://www.geeksforgeeks.org/artificial-neural-networks-and-its-applications/
https://medium.com/data-science-365/overview-of-a-neural-networks-learning-process-61690a502fa
https://ja.wikipedia.org/wiki/%E9%9A%A3%E6%8E%A5%E8%A1%8C%E5%88%97
https://ja.wikipedia.org/wiki/%E6%AC%A1%E6%95%B0%E8%A1%8C%E5%88%97
https://pytorch-geometric.readthedocs.io/en/latest/index.html
この記事が気に入ったらサポートをしてみませんか?