
#05 ARアプリ「コエカタ」の絵文字の扱い方について

おはようございます、株式会社アスタスタでソフトウェアエンジニアをしているK.田中です。
今回はコエカタの絵文字の扱い方についてお話ししたいと思います。
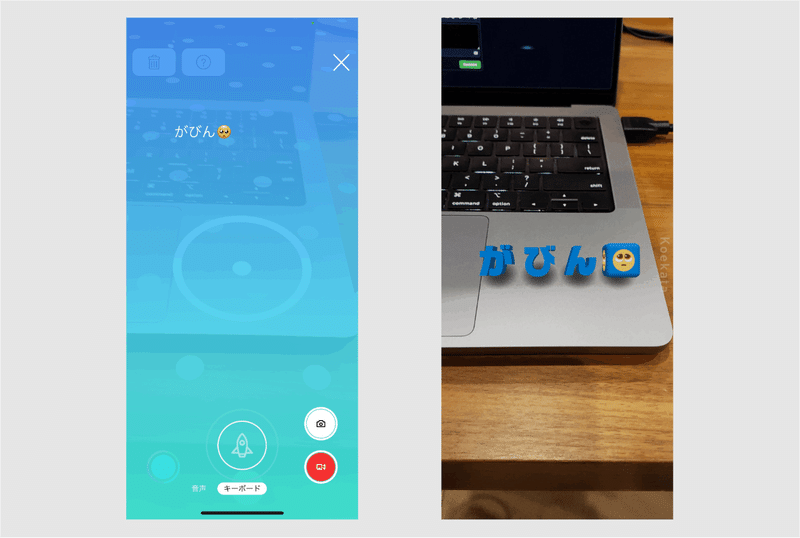
コエカタで文字や絵文字を入力して AR空間へ飛ばすと文字は立体文字に、絵文字は角丸ブロックの面に絵文字が表示されます。
これはキーボードで文字を入力した後の処理として通常の文字と絵文字部分を分けているためです。
たとえば...「がびん🥺」 と入力された場合 「がびん」 「🥺」 というように分けます。
内部ではUnicodeのByte配列に変換して、絵文字のUnicodeと絵文字画像の座標が書かれたテーブルから探し、見つかった絵文字の開始位置を記憶して
仮の文字に置き換えて通常の文字を立体化させ、仮の文字にしたところを絵文字のBOXで置き換える。というような処理をしています。

例えば、「😁」という絵文字のUTF-16エンコード結果は「0x3D 0xD8 0x01 0xDE」です。
このByte配列をUTF-32に変換すると、「0x0001F601」となります。この値を16進数文字列「1F601」に変換し、
座標が書かれたテーブルから該当する画像の位置を探し取得します。
テーブルは以下のような感じになります(実際は辞書なのですが..)

絵文字は一枚の画像に敷き詰められた状態で用意しsprit分割しておきます。

<https://github.com/iamcal/emoji-dataを加工>
何故一枚にまとめるのかというと
一括で読み込み、効率的にメモリ管理でき描画処理の負荷も軽減されるためです👾
以上になります💁♂️
この記事が気に入ったらサポートをしてみませんか?