
ポーカーAIを作ってみよう!(ガバガバ説明)

あけましておめでとうございます()
4ヶ月ぶりにしっかりとした投稿をするBuzzWordsです。
最近はcakewalkで自分のラップのビートを作成したり、
Blenderでモデリングを勉強したりしてます。
(下が自作のキャラです。色すら付けてない…笑)

そして、今回はAI(人工知能)に関しての記事を書いていきます。
といっても、中の人は社会科学(マーケティング)専攻の文系なので多少の(多めの)ガバ要素は許してにゃんまげ
ということでガードは張ったのでレッツゴー!(笑)
導入(今更な人は飛ばしてください)
さて、まずはAIというものの説明をしていきたいと思います。
みずほ情報総研さんがわかりやすい分類表を挙げていたので拝借。
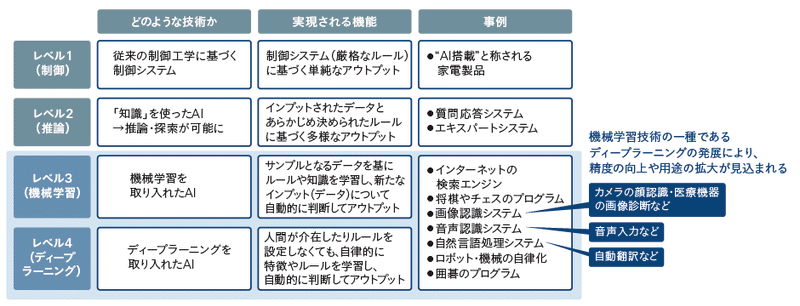
まず、人工知能ですらない「レベル1」。
例えば、エアコンみたいなイメージでしょうか?
20℃と設定したら、現在の気温を一定の間隔で取得して、20℃超えてたら下げて、20℃を下回ってたら上げるみたいな。
それにしても、「"AI搭載"と称される」だなんて!あら奥さん!
最高に猛毒ではございませんか!!(誉め言葉)
続いて、「レベル2」応答システム等らしいですね。
例えば、
「"明日"の"天気"を教えて!」
と言ったら、あらかじめ仕込んだルールをもとに
「こいつ!"明日"と"天気"って言いおったぞ!
せや、明日の天気教えたろ!」
って感じでしょうか。
上記2つはルールに則って行動してるだけなので、
「人工無能」なんて風に呼ばれております。
(ちなみに、「人工無能」っていうタイトルで曲作ってます。
1番はできた。)
さて、「レベル3」の人工知能と「レベル4」のディープラーニングです。
分かりやすい例として、オセロ(リバーシ)AIを例に考えてみましょう。
オセロ(リバーシ)ロボットを人工知能で作る際の方向性の例としては、
・オセロにて良い手は相手の選択肢を減らすことができる手
(打ちたくないとこに打たないといけなくなるから)
・では、数ターン後の「相手の選択肢が減るような手」(&「自分の選択肢は多くなる手」)を洗い出してみよう!
となるのがよく見るAIの実装かと思います。(Min-Max法って呼ばれるやつです。)
重要な点は、このオセロロボットはこうすれば「相手の選択肢が減る」といった「ルール」は人間が設定していることです。
では、オセロロボットをディープラーニングで作るとなると、、、
ひたすらに「こんな盤面だったらこれを打つとよい!」というデータを数万件ほど用意して、それを参考にして「ロボットが学習していく」という感じになります。
つまりは、学習法を間違えるとルール上置けませんよ!っていうところに置こうとしてしまうっていうことですね。
確か、Alpha碁がこの方法でAIを作ってましたね。
(ちなみに、略称はDQN(Deep-Q-Network)なので、日本人はよく
「ドキュン」じゃん!「ドキュン」じゃん!ぷぎゃあぁぁwwww
と喜びます(怒られそう))
以上、みずほ情報総研さんの画像からAIとは?を学んでいこうのコーナーでした(?)
データセットを用意しよう
さて、さっそくBuzzWordsが作ったポーカーAIの作成手順をもとにディープラーニングの作り方を追っかけてみましょう。
上記のオセロの例では
「こんな盤面だったらこれを打つとよい!」
でしたが、今回のポーカーでは
「こんな手札だったらこういう風に交換するといい!」
というデータを作っていきます。
ちなみに、一部コードを抜粋するとこんな感じです。
(以下で説明します。)
# Pythonのコードです
# ……
for b1, b2, b3, b4, b5 \
in itertools.product(range(2), range(2),range(2),range(2),range(2)):
self.game.change_hand(change=[b1, b2, b3, b4, b5])
self.game.calc_hand()
# 最適な交換を探る
if self.game.compare_hand(0, 1) == 1:
for x in range(len(self.game.players[1].hand)):
self.game.players[1].hand[x].num = copy.deepcopy(self.game.players[0].hand[x].num)
self.game.players[1].hand[x].pic = copy.deepcopy(self.game.players[0].hand[x].pic)
self.best_result = self.game.players[0].result
self.best_change[0] = b1
self.best_change[1] = b2
self.best_change[2] = b3
self.best_change[3] = b4
self.best_change[4] = b5
self.game.back_change_hand(change=[b1, b2, b3, b4, b5])
# ……
ちゃんと説明すると、
手札を変えて、今までで一番だったらメモっておいて、また手を戻す。
というアカギもびっくりのイカサマを手札5枚(変える/変えない)の全パターンにて検証するということです。
今回はそんな「最善手」データを500,000個用意しました。
よくAI用語でデータマイニングなんて言葉を聞くことがありますが、本質的にはこの「イカサマ」と近い選別をしているのではないでしょうか。
数十万、数百万といったデータの中から良いデータを引っ張ってくる(採掘する:mining(マインクラフトのマイン))という作業がAI開発に必要になってきます。
確かに、完全ランダムなデータを集めても、ルール違反な結果になりかねなかったり、良くない手を打つ羽目になりますからね~
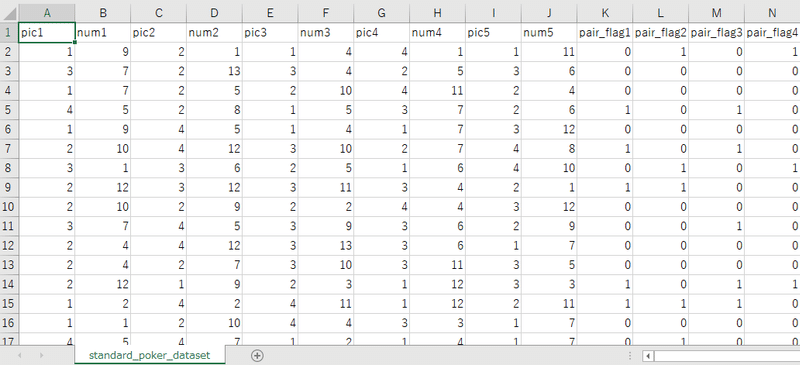
ちなみに、上みたいな感じで関係のないデータもいろいろと拾うようにしています。
ここが現実の「ルール」を意識してしまっている節があるので、今回のAIはニューラルネットワークではない?という見方もできそうな気がするので、難しいところですね。まあ、AIには変わらない。
今回のデータは「元々のカード(数字・絵柄)」、「元々のそろい具合(他4枚と数字がかぶっている枚数)」、「元々の役」を数値化して集めています。
最初のころは「元々のカード(数字・絵柄)」のみだったのですが、それだとツーペアやスリーカードでも無慈悲に交換してしまっていたため、
「そろい具合」を追加してみました。
しかし、今度はその「そろい具合」ばかりに目が行き、ストレートやフラッシュの際にも交換して改悪してしまっていたため、「役」も渡すようにしました。
ということで、この章では
・人工知能・ディープラーニングにはデータが必要不可欠
・しかし、ただ闇雲に使うわけではなく良いデータを選別する必要がある
・集めるデータの種類によって学習結果が変わることがある。多角的に集めるべし。
といったことがわかりました。
次は学習のフェーズです。
学習
さて、次は上記で用意したデータセットを用いて(機械)学習していくフェーズです。
学習って何を学習するの?というのを説明するために、
ニューラルネットワークというものを学んでいきましょう。
ニューラルネットワークはシナプスの結合によりネットワークを形成した人工ニューロン(ノード)が、学習によってシナプスの結合強度を変化させ、問題解決能力を持つようなモデル全般を指す。
(Wikipediaより引用)
というもので、遺伝子のつながりをプログラムで模したものとなっています。
そして、この「遺伝子のつながり」には3種類の「層」というものがあります。
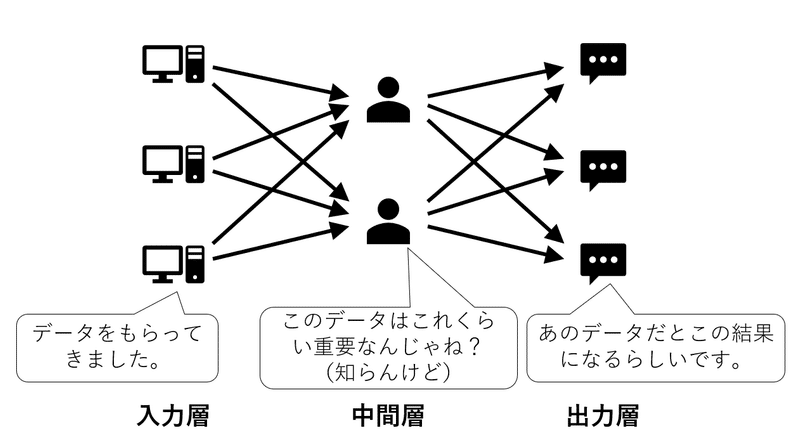
①入力層:
読み込んだデータを0から1に変換して次の中間層に渡す層です。
そのまんまみーや。
②中間層:
ニューラルネットワークの要である中間層。
この層は、入力層(または一個前の中間層)からもらったデータに適当に重要度(重み)をつけて次の層(中間層または出力層)に渡すという層です。
この「重み」をどの程度にするのかを決めるのが「学習」なのです。
③出力層:
入力層から受け取ったデータに中間層の重みづけを加味した結果を出す層です。
というように、中間層の重みを決定していくのが「学習」というものです。
ちなみに、「数十万・数百万」という膨大な「良いデータ」で検証することで「適当」さを薄めているのです。
とはいえ、あまりデータについて学習しすぎると、データにない動きができなくなってしまう(過学習してしまう)ので注意が必要です。
以下が実際の実装です。
import numpy as np
import tensorflow as tf
import pandas as pd
# ……
model = tf.keras.Sequential([
tf.keras.layers.Dense(16, input_shape=(16,), activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(5, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# ……
GoogleのAIフレームワーク「TensorFlow」を使って実装してみました。
「tf.keras.layers.Dense」というのが各層を表しています。
ちなみに、Dropoutという部分で過学習を防いでいます。
詳細は公式リファレンスから勉強してみましょう。(丸投げ)
ちなみに、model.compile(...)で学習したデータをモデルとして保存できましたので、そちらを使って学習結果をテストして(実際に遊んでもらって)みましょう。
……(中略)
better NO_ROLE => ONE_PAIR
better ONE_PAIR => THREE_CARD
worse TWO_PAIR => ONE_PAIR
better ONE_PAIR => TWO_PAIR
better NO_ROLE => FOUR_CARD
better ONE_PAIR => THREE_CARD
better NO_ROLE => ONE_PAIR
better NO_ROLE => ONE_PAIR
worse THREE_CARD => ONE_PAIR
better NO_ROLE => THREE_CARD
better NO_ROLE => ONE_PAIR
better NO_ROLE => TWO_PAIR
worse TWO_PAIR => ONE_PAIR
better NO_ROLE => ONE_PAIR
better NO_ROLE => ONE_PAIR
better NO_ROLE => ONE_PAIR
better: 270 so so: 705 worse: 25
こんな感じで、27%で改善、2%で改悪といった結果になっています。
このAI作成が面白いのは、「データセット」の作成法を変えると結果も変わってくるということです!
例えば、結果がワンペア、ツーペア、スリーカード、フルハウス、フォーカードのデータしか用意しないと、現在の手でペアを作ろうと奮闘しますし、フラッシュ系だけのデータのみを用意すると色を揃えようと頑張ってくれて、、、
そりゃ信号だってローランド見たら惚れて真っ赤になっちゃうよなぁ、って感じで赤信号かわいい。
間違えた。
TensorFlowモデルかわいい
(「俺か、俺以外か。」読んだからって突然のローランド様やめいwww)
ということで(?)、学習とは
・与えられたインプット(データ)に対して「適当に」重要さをつけて次に渡していくという工程の中の、重要度つまり「重み」を最適にしていく作業。
・その「適当」さは膨大な正解データによって薄まる
・とはいえ、気を付けないとデータにない行動に対処できない「過学習」状態になってしまう
っていう感じでしょうか。
総括
今回は
①AIって何ぞや?(「ドゥクドゥク(スクラッチ音)、私AIです。みたいなフローやめろ、下品だ。」的な事例(?)も踏まえつつ。)
②AIにとって重要な「データ」の用意について(自作でデータを作る実例含め)
③AIはデータをどのように学んでいくのか?(そもそも学ぶって何?的な話含めて、めちゃんこざっくり)
といった手順でAI開発の概要をさらってみました。(大味になっちゃった感はありますが)
本格的にはもっと奥深い世界ですので、色々な教材を使って一緒に学んでいきましょう(丸投げ)
それにしても、よくITのビジネス利用だ!ICT!ICT!なんて騒いでいますが、社会(法人格という人格)が本当に欲しいのは
・人工知能(予測ロボ)なのか
・人工無能(いった通りに動くロボ)なのか
・「ロボットのように働く人間」なのか
BuzzWordsマネージャーの周りの人がいろいろと苦労している話を年末年始に聞いてなんだかなぁ…と思っている中で、労働の負担を減らすヒントとなればとAIを学んでみましたが、ただそれだけで解決できるような簡単なお話でもありませんね。(知ってた)
こんなことばっかり言っていると、
「何を若造が!もっと社会のために働くんじゃ!」
「わしが若いころはもっと○○だったもんじゃ!」
「若いころの苦労は買ってでもするもんじゃ!」
なんていう老ga…ごほんごほん、
有害なご老人にぶちぎれられそうですが
(ちょっと!隠した意味!笑)
なんというか社会が豊かになってもそれが誰かの犠牲のもとに成り立っているのは心苦しいなぁ…なんて。。。
どこかでぼろがでるから誰の得にもならないんじゃないかなんて。
とはいえ、消費活動は人間のエゴですからね。その需要と供給の最適なバランスを見つけて、次世代の無用な心身の負担を減らしていきたいものです。
(以下、そんなことを教えてくれる面白い記事(ステマ界の帝王))
そのためにも、IT、マーケティング、その他もろもろ、色々な知識を身に着けて思考の選択肢を増やしていけるようになりたいものです。
あ、ちなみに中の人の周りは「逆老害」ばっかりで人的には楽しい日々を送っております。
(仕事内容は難しい。まぁ、そう簡単にはいかないさ。)
それでは、皆様も実験の日々を!俺こそがBuzzWords!!
AIの勉強で参考にさせていただいた本&AI以外で最近読んだためになった本)
・「ニューラルネットワーク自作入門」Tariq Rashid[著] 新納 浩幸[監訳](マイナビ出版)
ニューラルネットワークを学習コストの少ないプログラミング言語のPythonで自作してどのように動くのかを追っかけていく本です。
学習の章の「入力層」とかの図が何言ってるのか解説してくれてます。
・「リバーシのアルゴリズム」Seal Software 著
ちょいと古めの本ですが、リバーシAIを作る際のノウハウが書かれています。Min-Max法の件とかが深く学べると思います!
CD-ROMでリバーシアプリもついているよ(まじで何度やっても勝てなかった…)
・「Python データサイエンスハンドブック」 Jake VanderPlas [著] 菊池 彰 [訳]
AIをPythonで実装する際には、
Python->Numpy(フレームワーク)->TensorFlow(フレームワーク)といった感じでステップアップすることが多いので勉強しておいて損はないです(というか、してないと薄めの知識になってしまいそう?)
まあ、そういう知識のステップアップをしなくても使えるのがフレームワークのメリットでもあるので自分に合った学習を。
以下、AI以外&最近読んだ本です。
・「俺か、俺以外か。」ROLAND 著
セルフブランディングというか、生き様から生まれるパンチライン集。
なぜこの人の吐息が名言に変わるのかの一端を見れた一冊。
といっても、この本を「もう読んでる人」か「これから読む人」しかいないから宣伝しても無駄か。
自分らしい生き方をするためのヒントになりました。
・「売上を、減らそう。たどりついたのは業績至上主義からの解放」 中村朱美[著]
佰食屋というお店で実践されている従業員が幸せになれて利益(売上-損失)もしっかりと保証される魔法の仕組みの裏話です。
既存のシステムにズバズバと切り込みを入れていて、めちゃくちゃ斬新な方だな~と感じました。
しかもそれが、便利な世の中にするためとかじゃなくて、みんなが「安心して暮らせるための革新さ」というパラドックスをシステムで実現している感じが見ていて爽快です。
ということで、AIに関係のないお話もたくさんありましたが、皆さんの勉強になったのであれば幸いです。
ちなみに、こんな感じでちょっとふざけてて、ちょっと勉強になって、何かのヒントになるような投稿を自分のペースでしておりますので、ぜひフォローお願いします!(決まったぁ~ドヤァ~(台無し感))
この記事が気に入ったらサポートをしてみませんか?