【地球沸騰化を可視化】NASA表面温度データの上昇速度を分析して100年予測をしてみた(地球かなりやばい状態)

先日、あるデータサイエンス関連のオンラインイベントの一環で、久しぶりにKaggle上でデータアナリシスのノートブックを作成しました。
ちなみにKaggle(カグル)とは:
予測モデリングと分析コンペティションのプラットフォームで、データサイエンティストや研究者が複雑なデータセットの予測と分析のための最高のモデルを生み出すことを競うコンペティションを常時開催しています。また、Kaggleは公開データプラットフォームを提供し、ユーザーがさまざまな分野のデータセットを見つけたり公開したりできるようになっていて、データサイエンス実践者のコラボレーティブなコミュニティに貢献しています。さらに、Kaggleはデータサイエンスの教育と開発のためのさまざまなツールやリソースを提供していて、ユーザーがコードを実行し、データ分析を行い、その洞察をプラットフォーム上で直接共有できるカーネル(スクリプトやノートブック)があります。
そして今回作成したノートブックがこちらです。
今日はこのノートブック内で行った地球表面温度の上昇速度のデータ可視化とその分析結果を用いた100年予測の簡単な流れを紹介していきたいと思います。
🛒データの取得
データはKaggle内で公開されているデータカードを直接ノートブックに取り込みました。
Global Surface Temperatures Data By NASA (kaggle.com)
データソースはNASAです。
このデータセットでは、気温の表記が通常とは異なります。ここで使われているのは「アノマリー」という指標で、従来の気温表記(例:20°Cや30°C)ではなく、0.25°Cや0.50°Cといった比較的小さな値で示されています。
アノマリーとは:
「アノマリー」は一般に「例外」や「異常値」という意味合いで用いられます。気象学的な意味合いにおいては、特に地球温暖化の文脈で重要な概念となり、1850年から1900年までの平均気温と比較した際の、ある年の平均気温の偏差を示します。

データの重複やNull値の有無を確認し、クリーニングを行った後、探索的データ解析(EDA)へと進みます。
タイムシリーズ
まずは全体的な気温の上昇を見るためにタイムシリーズで可視化します。
以下のコードでは季節ごとの温度異常を同一グラフ上にプロットしています。年を通じて温度異常がどのように変化するか、そして特定の季節が温暖化の影響をどの程度受けているかを視覚的に示しています。
# Mapping of columns to season names for the legend
season_info = {
'J-D': 'All Year Around',
'DJF': 'Dec-Jan-Feb (Northern Hem\'s meteorological Winter)',
'MAM': 'Mar-Apr-May (Northern Hem\'s meteorological Spring)',
'JJA': 'Jun-Jul-Aug (Northern Hem\'s meteorological Summer)',
'SON': 'Sep-Oct-Nov (Northern Hem\'s meteorological Fall)'
}
# Set the seaborn color palette so that each season gets a distinct color
sns.set_palette("colorblind")
# Plot each season on the same graph
plt.figure(figsize=(12,6))
for col, title in season_info.items():
plt.plot(df['Year'], df[col], marker='o', label=title)
plt.title('Temperature Anomalies by Season')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly (°C)')
plt.grid(True)
plt.legend()
plt.show()
1970年代から全体的に気温が上昇し続けている事が分かります。
ボックスプロット
このボックスプロットは、各変数(月および季節)を説明しています。データフレームに含まれる各列に対して、色覚障害者にも配慮したカラーパレット「colorblind」を使用してボックスプロットを作成しています。この可視化により、年間を通じた気温のばらつきや季節ごとの温度分布が明らかになります。
# Set the color palette to 'colorblind'
palette = sns.color_palette("colorblind")
plt.figure(figsize=(20,10))
# Loop through each column (excluding 'Year')
for i, column in enumerate(df.columns.drop('Year')):
# Create a subplot for each column
plt.subplot(3, 6, i+1)
# Use modulo to cycle through the colorblind-friendly palette
color = palette[i % len(palette)]
sns.boxplot(y=df[column], color=color)
plt.title(column)
plt.tight_layout()
plt.show()
ヒートマップ
このヒートマップは、1880年から2023年までの期間における月別、季節別、および年間全体の気温異常値の相関を視覚的に示しています。sns.heatmapを用いて、相関係数を色で表現し、各セルにはその数値が注記されています。これにより、異なる月や季節の気温異常がどの程度相関しているかが一目でわかります。
months_columns = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
df_months = df[months_columns]
corr_matrix = df_months.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corr_matrix,
annot = True,
cmap='flare',
linewidth=3,
square=True)
plt.title('Correlation Matrix Heatmap for January to December (1880-2023)')
plt.show()


📈トレンド分析
線形回帰(ベースモデル)
まずはベーシックな線形回帰から始めます。
ちなみに線形回帰は、統計学における最も基本的な予測モデルの一つであり、2つ以上の変数間の関係をモデリングするために使用されます。線形回帰モデルは、独立変数(説明変数)と従属変数(目的変数)間の線形関係を見つけることを目的としています。このモデルは、データセット内の点を最もよく表す直線(線形関係)を見つけることによって、一方の変数の値から他方の変数の値を予測します。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
# Mapping of columns to season names
season_names = {
'J-D': 'All Year',
'DJF': 'Winter',
'MAM': 'Spring',
'JJA': 'Summer',
'SON': 'Fall'
}
X = df['Year'].values.reshape(-1, 1)
for col, season in season_names.items():
y = df[col]
model = LinearRegression().fit(X, y)
print(f"\nTrend Analysis for {col}:")
print(f"Slope: {model.coef_[0]}")
print(f"Intercept: {model.intercept_}")
y_pred = model.predict(X)
plt.figure(figsize=(10, 6))
plt.scatter(df['Year'], y, label='Observed')
plt.plot(df['Year'], y_pred, color='red', label='Fitted Line')
plt.xlabel('Year')
plt.ylabel(f'Temperature Anomaly ({season})')
plt.title(f'Temperature Anomaly with Linear Trend Line ({season})')
plt.legend()
plt.show()
移動平均方法
移動平均法は、時系列データを分析する際に使用されるシンプルな平滑化技術の一つです。この方法は、時系列データの短期的な変動を平滑化し、長期的なトレンドを明らかにするために利用されます。移動平均法は、データの一定期間にわたる平均値を計算し、それを連続的に更新していくことにより、時系列の平滑化を行います。移動平均を計算する際には、一定期間の幅(Window)を設定することが可能です。今回は
ウィンドーサイズ=10に設定し、10年ごとの移動平均値を可視化していきます。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
palette = sns.color_palette("colorblind", 3)
window_size = 10 # try different size of window
df['Moving_Avg'] = df['J-D'].rolling(window=window_size).mean()
plt.figure(figsize=(10,6))
plt.scatter(df['Year'], df['J-D'], alpha=0.6, label='Observed Anomaly')
plt.plot(df['Year'], df['Moving_Avg'], color=palette[1], label=f'{window_size}-Year Moving Average')
plt.plot(df['Year'], y_pred, color=palette[2], label='Linear Trend Line')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly')
plt.title(f'Temperature Anomaly with {window_size}-Year Moving Average')
plt.legend()
plt.show()
青い点は観測された異常値です。オレンジ色の線は10年間の移動平均で、緑色の線は線形トレンドラインです。
📉統計分析
Kaggleノートブックでは数種類の統計分析をカバーしましたが、ここではANOVAを紹介します。
ANOVA(分散分析)
まずは分散分析、この場合では一元配置分散分析を試みます。ちなみに分散分析とは、異なるグループの平均値の違いを比較するために使用される統計手法です。異なるグループ間の平均値に差があるかどうかをチェックする時に役立ちます。このデータ分析では、それぞれのシーズンの平均値に差があるかどうか、もっと言えば春夏秋冬で温度の上がり下がりに差があるのかどうかを統計手法を使って確かめます。
ただ、分散分析をする前に幾つかチェックしておくことがあります。分散分析はパラメトリック検定で正規分布を仮定の上に成り立っています。なので、それぞれのグループのデータが正規曲線に分布しているかどうか確かめる必要があるので、その作業を先に行います。
Q-Qプロットは正規曲線に分布しているかどうか視覚的にチェックする方法です。
import scipy.stats as stats
import matplotlib.pyplot as plt
seasons = ['DJF', 'MAM', 'JJA', 'SON']
for season in seasons:
plt.figure()
stats.probplot(df[season], dist="norm", plot=plt)
plt.title(f'Q-Q Plot for {season}')
plt.show()

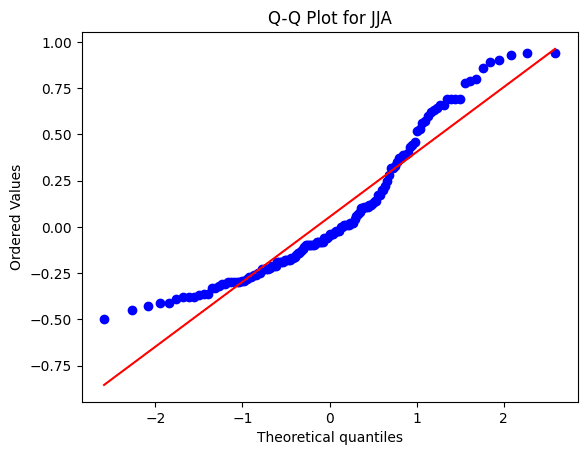

通常なら、データがQ-Qプロット上で直線に沿って配置されている場合は、データが正規分布していると考え、分散分析を適用することができます。しかし、上記のQ-Qプロットを見ると、データが曲線を描いており、正規分布の直線的な配置から逸脱しているように見えます。このため、シャピロテストを実施し、p値を用いて数値的に正規性をチェックすることが重要です。
from scipy.stats import shapiro
for season in seasons:
stat, p = shapiro(df[season])
print(f'{season}: Statistics={stat}, p={p}')
if p > 0.05:
print('Sample looks Gaussian (fail to reject H0)')
else:
print('Sample does not look Gaussian (reject H0)')DJF: Statistics=0.9555511474609375, p=0.00013722883886657655
Sample does not look Gaussian (reject H0)
MAM: Statistics=0.9312835931777954, p=1.8837203015209525e-06
Sample does not look Gaussian (reject H0)
JJA: Statistics=0.912170946598053, p=1.1155611190361014e-07
Sample does not look Gaussian (reject H0)
SON: Statistics=0.9089100956916809, p=7.146584124484434e-08
Sample does not look Gaussian (reject H0)全ての季節データに対して非常に低いp値が得られたことは、これらのデータセットが正規分布に従っていないことを示しています。そのため、分散分析(ANOVA)のような、データの正規分布を前提とする統計的手法は適用できません。この場合、非パラメトリックな手法や他の適切な統計手法を検討する必要があります。
分散分析が使えない場合は??
クラスカル・ウォリス検定は、複数の独立したサンプル群が同じ母集団から来ているかどうかを判断するためのノンパラメトリック(非パラメトリック)検定方法です。正規分布を前提としないため、分散分析(ANOVA)を適用できない場合に有効な代替手段となります。特にサンプルサイズが小さい場合やデータが正規分布に従わない場合に有用です。
from scipy import stats
import pandas as pd
season_data = df[['DJF', 'MAM', 'JJA', 'SON']].stack()
# Creating a new data structure
season_df = pd.DataFrame({'Season': season_data.index.get_level_values(1), 'Anomaly': season_data.values})
print(season_df)
# Kruskal-Wallis test
h_stat, p_value = stats.kruskal(season_df[season_df['Season'] == 'DJF']['Anomaly'],
season_df[season_df['Season'] == 'MAM']['Anomaly'],
season_df[season_df['Season'] == 'JJA']['Anomaly'],
season_df[season_df['Season'] == 'SON']['Anomaly'])
print("Kruskal-Wallis Test Results: H-Stat =", h_stat, ", P-value =", p_value)
クラスカル・ウォリス検定の結果、p値が0.05よりも高い場合、これは統計的に有意な差が存在しないことを意味します。つまり、分析された季節ごとの平均気温には、統計的に有意な差異が認められず、これらの季節の違いが全体の気温の変動に大きな影響を与えているとは言えないことになります。この結果から、気温の上昇や下降は季節的な変動よりも、他の要因によって主に引き起こされている可能性が示唆されます。
変化点分析
ここでは変化点の検出をします。変化点分析の方法としてはバイナリー分割という時系列データの構造的変化を特定するのに適した方法を使用します。
import ruptures as rpt
points = df["J-D"].values
print(points)
# Search, binary segmentation
algo = rpt.Binseg(model="rank").fit(points)
result = algo.predict(n_bkps=5) # number of breakpoints to detect
print(result)
# Plotting
plt.figure(figsize=(10,6))
plt.plot(df['Year'], points, label='J-D')
palette = sns.color_palette("colorblind")
# Addinv vertical lines for change points
for i, cp in enumerate(result[:-1]):
year = df['Year'].iloc[cp]
color = palette[i+1]
plt.axvline(x=year, color=color, linestyle='--', label=f'Change Points {i+1}')
plt.text(year, max(points), f'{year}', color=color, verticalalignment='top', horizontalalignment='right')
print(f"Change Point {i+1}: Year {year}, Position {cp}")
plt.xlabel('Year')
plt.title('Change Point Detection for All-Year')
plt.legend()
plt.show()
5つの変化点を異なる色で縦線で表示してみました。
1930年、1940年、1945年、1980年、そして2000年に大きな気温の変化の変化点が検出されました。
変化点1 - 1930年: この点は、顕著な温暖化フェーズの始まりを示している可能性があります。これは、産業化の初期の影響によるものかもしれません。
変化点2 - 1940年: 10年後、この点は温度トレンドにおける別のシフトを示唆しています。1940年頃は、一時的な冷却期の始まりをマークし、その後には急激な温度上昇が続きました。この変動は、自然気候変動などの要因によるものかもしれません。
変化点3 - 1945年: 1940年代半ばは、第二次世界大戦の終結など、歴史的な理由で重要です。これは、戦時中の産業活動を通じて大気状態に影響を与えた可能性があります。
変化点4 - 1980年: 1980年代初頭は、地球温暖化の始まりを示し、20世紀の終わりから21世紀にかけての継続的な温暖化トレンドが観測されました。
変化点5 - 2000年: 2000年には重要な変化点がありました。21世紀初頭は、世界中で最も暖かい年を観測しており、気候変動の影響が加速していることを示唆しています。
🔮100年予測🌡️
ARIMAモデル(自己回帰和分移動平均モデル)を使って100年予測をしていきます。ちなみにARIMAモデルとは時系列データの予測技術で、自己回帰(AR)、差分化(I)を使ってデータを定常状態にすること、および移動平均(MA)の成分を組み合わせたものです。時系列データ内のパターンを分析する事により、過去のデータを理解し未来のデータポイントを予測するために活用されます。トレンドや季節的パターンを示すデータを扱う際に多用途なモデルです。
今回はpmdarimaというモジュールのauto_arimaを使って未来予測を可視化していきます。
from pmdarima import auto_arima
# Forecasting for 100 years
n_periods = 100
forecast, conf_int = model.predict(n_periods=n_periods, return_conf_int=True)
# print(forecast)
# print(conf_int)
# Adjusting future_index for yearly data
# Ensure that 'ts' index is in DateTime format and the frequency is Yearly ('Y')
future_index = pd.date_range(start=ts.index[-1] + pd.offsets.DateOffset(years=1),
periods=n_periods,
freq='Y')
print(future_index)
# Plotting the forecast with the historical data
plt.figure(figsize=(10, 5))
plt.plot(ts.index, ts, label='Historical')
plt.plot(future_index, forecast, label='Forecast', color='red')
plt.fill_between(future_index, conf_int[:, 0], conf_int[:, 1], color='pink', alpha=0.3)
plt.title('Forecast for the Next 100 Years')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly (°C)')
plt.legend()
plt.show()
このグラフでは青い線、赤い線、そしてピンクのエリアがあります。
青い線は、過去の気温異常の実際のデータを表しています。これは過去の観測値を基にしており、歴史的な気温の変動を示しています。
赤い線は、将来の気温異常に対する予測値を表しています。この線はモデルによって生成された予測を示しており、未来における気温の変化の傾向を表しています。
ピンクのエリアは、予測値の信頼区間を表しています。このエリアは、予測の不確実性を可視化していて、将来の気温がこの範囲内に収まる可能性が高いことを示しています。ピンクのエリアが広いほど、予測の不確実性が大きいことを意味します。信頼区間は通常、特定の信頼水準(例えば95%)に基づいており、真の値がこの区間内に存在する確率を示しています。
このグラフを通じて過去のデータと将来予測を比較する事ができ、予測の不確実性についても理解する事ができます。
パリ協定のベンチマークと目標値
from pmdarima import auto_arima
# Forecasting for 100 years
n_periods = 100
forecast, conf_int = model.predict(n_periods=n_periods, return_conf_int=True)
# print(forecast)
# print(conf_int)
# Adjusting future_index for yearly data
# Ensure that 'ts' index is in DateTime format and the frequency is Yearly ('Y')
future_index = pd.date_range(start=ts.index[-1] + pd.offsets.DateOffset(years=1),
periods=n_periods,
freq='Y')
# print(future_index)
# Plotting the forecast with the historical data
plt.figure(figsize=(10, 5))
plt.plot(ts.index, ts, label='Historical')
plt.plot(future_index, forecast, label='Forecast', color='red')
plt.fill_between(future_index, conf_int[:, 0], conf_int[:, 1], color='pink', alpha=0.3)
# Add a horizontal line for the +1.5 anomaly
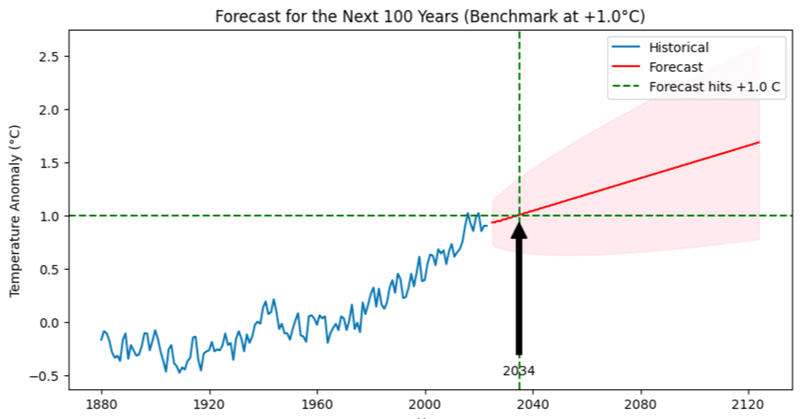
plt.axhline(y=1.0, color='green', linestyle='--')
# Return the first True index
hit_10_index = np.argmax(forecast>=1.0)
plt.axvline(x=future_index[hit_10_index], color='green', linestyle='--', label='Forecast hits +1.0 C')
plt.annotate("2034",
xy=(future_index[hit_10_index],1.0),
xytext=(future_index[hit_10_index], -0.5),
arrowprops=dict(facecolor='black', shrink=0.05),
ha='center')
plt.title('Forecast for the Next 100 Years (Benchmark at +1.0°C)')
plt.xlabel('Year')
plt.ylabel('Temperature Anomaly (°C)')
plt.legend()
上のグラフでは緑の点線で目標値を加えました。
この分析での地球温暖化評価の目標は次の理由から+1.5°Cから+1.0°Cに調整されました。
パリ協定は、気候変動のリスクを減らすために、産業革命前のレベルを基準として全球平均気温の上昇を1.5°C未満に抑えることを目指しています。しかし、協定は産業革命前の期間を特定していませんが、1850年から1900年が広く受け入れられています。このNASAのデータセットでは、気温の異常に対する参照期間として1951年から1980年を使用しており、これは産業革命前ではありません。この期間はすでに産業革命前の基準よりも暖かいため、1.5°Cの直接的な増加はパリ協定の目標を正確に表していません。分析によると、20世紀半ばは産業革命前のレベルより約0.3°Cから0.4°C温暖であったことが示されています。したがって、この特定の分析のために+1.0°Cに目標値を調整し、この差異を考慮して協定の目標をより正確に反映することにしました。
上記を踏まえてた上での可視化によると、以下のような予測が立てる事ができます。
1951年から1980年の平均に対する+1.0度セルシウスの気温異常のベンチマークを用いてNASAの気候データを可視化し、その目標値が2034年に達するとの予測は、世界の様々なシステムに重大な影響を及ぼすことが予想されます。
この予測結果は、全球の気温が次の10年以内に気候変動の影響に重大な限界を超える軌道にある事を示しています。
パリ協定の目標値を超えると起こりえる現象とは
産業革命前の基準をもとに、地球の平均気温の上昇を1.5度に抑えるというパリ協定の目標を超えた場合、自然環境と人間社会に多くの深刻な影響が生じると予測されます。
気象変動の激化:極端な気象イベント、例えば熱波、ハリケーン、干ばつ、洪水、山火事の頻度と激しさが増す可能性があります。これは生態系、農業、そしてすでに脆弱なコミュニティに壊滅的な影響を与える可能性があります。
海面上昇: 気温が上昇すると、極地の氷が溶け、海面が上昇し、沿岸都市や島々が洪水に見舞われ、数百万人が移住を余儀なくされる可能性があります。これはまた、沿岸の生態系やインフラにも脅威を与えます。
生物多様性の損失: 高温と降水パターンの変化により、多くの種の生息地が失われ、絶滅に向かわせる可能性があります。この生物多様性の損失は、人間が依存している生態系サービス、例えば、受粉、水質浄化、病気管理などの生態系を乱す可能性があります。
農業への影響: 気候変動は作物の収量に影響を与え、食糧安全保障を低下させる可能性があります。一部の地域では、極端な熱、干ばつ、または洪水のために農業生産性が低下する可能性がありますが、他の地域では負の影響が利益を上回る前に一時的な生産性の向上を経験するかもしれません。
健康リスク: 熱関連の病気や死亡、水や昆虫を介して伝播する病気の拡散、悪い空気質による呼吸器系の問題など、健康に関連した問題の増加が予想されます。子供、高齢者、既存の健康問題を持つ人々など、脆弱な人口はより大きなリスクにさらされます。
経済的な影響: パリ協定の閾値を超えることの経済的影響は深刻であり、世界市場に影響を与え、気候関連災害の修復費用を増加させ、変化に適応するための莫大な投資が必要になります。これには、再生可能エネルギー源への移行、気候に強いインフラの構築、影響を受けるコミュニティの支援が含まれます。
社会的および政治的な課題: 政府間の合意形成や実行力が試されます。国家や地域が自国の経済的利益を優先する傾向があり、国際的な気候変動対策の取り組みに対するコミットメントが不均一になる可能性があります。さらに、気候変動の影響は国境を越えるため、国際協力と地球規模での対応策が不可欠ですが、政治的対立や経済的競争がこれらの取り組みを阻害することが予測され、効果的な対策の実施を複雑にしています。社会的には、気候変動による影響はしばしば最も脆弱なコミュニティに不釣り合いに大きくのしかかり、不平等の拡大を招きます。これらの課題に対処するためには、持続可能な開発と気候変動対策を支援するための国際的な枠組みを強化し、多国間での協力を促進する必要があります。
私たちが今すべきこととは
パリ協定の目標を超える地球の平均気温上昇は、自然環境だけでなく人類社会にも甚大な影響を及ぼします。未来世代に持続可能な地球を残すためには、私たち一人一人がより一層環境に優しい生活を心掛け、強力な気候変動対策を求める声を上げることが重要です。
気候変動という共通の課題に対して、あなたはどのような貢献ができますか?
あなた自身が今日から始められることは何ですか?
🌏endnotes…
詳しくはこちらのKaggleノートブックも見てみてください。
ディスコード
👩💻ディスコード上でデータコミュニティーを運営しています。現時点では英語ですが、日本語チャンネルも作ってデータ、プログラミング、AIなどの技術に興味ある人たちを迎え入れられるようにしていきたいと思っています。興味ある方はコメント欄でお知らせください。招待コードを送ります。
🖊️何か気づいたことやご意見などがあればコメント欄からお願いします。チャンネルフォローもよろしくお願いします。
🚀 疑問に思った事はデータ化して自分なりの答えを探していこうと思います。そしてその答えがどこかにいる誰かの為になる事を願っています。
この記事が気に入ったらサポートをしてみませんか?