
15章 RNN:ジュール・ヴェルヌ『神秘の島』で深層学習

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第15章 系列データのモデル化-リカレントニューラルネットワーク」の「15.3.2 プロジェクト2:文字レベルの言語モデルをPyTorchで実装する」で実装した文章自動生成器の概要と、お試しで自動生成した文章を紹介します。
15章のダイジェスト
15章では、リカレントニューラルネットワーク(RNN)にチャレンジします。
RNNは系列データと呼ばれる「順序に意味があるデータ」を取り扱います。系列データは例えば、文章データ、DNA配列データ、株価データ、音声データです。
まずは、系列データとRNNモデルの理論的な基礎を図解などで学びます。
続いて、次の2つのケースについて、RNNを実装します。
1. プロジェクト1:IMDb映画レビューの感情分析
2. プロジェクト2:文字レベルの言語モデルをPyTorchで実装(ジュール・ヴェルヌの『神秘の島』を利用)
なお、この章で扱う文章データは「英語」です。日本語を取り扱う際の処理、たとえば形態素解析などは取り扱っていません。
小説『神秘の島』調の文章生成器を動かす!
1. 小説『神秘の島』
小説『神秘の島』は1874年に出版されたジュール・ヴェルヌの作品です。
今回のモデル構築においては、Project Gutenbergにより電子書籍化されたデータを利用します。
Project Gutenbergの公式サイトを置いておきます。
次のサイトでこの小説のテキストファイル「1268-0.txt」を取得できます。
次のコードでダウンロードできました。
# 『神秘の島』テキストファイルをダウンロードする
import urllib.request
path='./1268-0.txt' # 保存先のパス・ファイル名を設定
url='https://www.gutenberg.org/files/1268/1268-0.txt'
urllib.request.urlretrieve(url, path)2. 文章生成器の概要
小説『神秘の島』の英語文章を学習して、新しい文章を生成するモデルを構築します。いわゆる文章自動生成のAIのようなものです。
始まりの文章を与えると続きの文章を書いてくれる、こんなモデルです。
ただし、生成するのは英語文章です。英語文章の小説を学習するので。
15.3.2項のタイトルにある「文字レベルの言語モデル」について少々。
文字レベルの言語モデルでは、文章や単語を「文字レベルに分解」したデータを扱います。
今回のモデルでは、たとえば、'Hello Pytho’ の文章を 'H', 'e', 'l', 'l', 'o', ' ', 'P', 'y', 't', 'h', 'o' という具合に、文章を構成する文字1つ1つに分解して、文字の並びを学習して、次の1文字を予測します。この例では、例えば 'n'を予測すると、つなげて'Hello Python’の文章が完成します。
こうして生成された文章の最後尾に、さらに1文字を予測して追加して、さらに1文字を・・・といった具合に、文字を付け足していくことで、新しい文章(長文)を生成します。
3. 訓練の概要
訓練用データ(小説・神秘の島)のデータ的な特徴は次のとおりです。
・文章に含まれる文字数:1,112,296文字
・文章に使われている文字の種類:80
モデルはこんな感じ。

損失関数はnn.CrossEntropyLoss、オプティマイザはAdamです。
モデルの訓練は、シーケンスの長さを40(つまり、1シーケンスあたり40文字)にして、10,000エポックで実施しました。
訓練処理にかかった時間はおよそ「108分」です。
GPU非搭載パソコンで処理するので、訓練時間はそこそこかかりました。
なお、事前に100エポックで試行したところ1分かかったので、10,000エポックの処理時間を100分と見込んでいました。ほほ見込みどおりです。
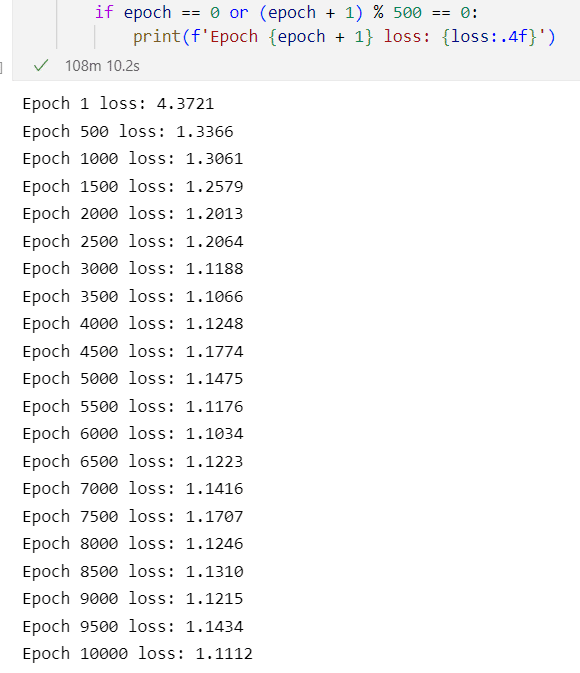
損失値1.1112の性能の良し悪しはよくわかりません。
テキストの9500エポック時の損失値は1.1048ですので、テキストの訓練モデルよりも性能が低いのかもしれません。
4. 実演:お試しで新しい文章を生成する
次の条件で文章生成器を実行して、文章を生成してみましょう。
(適度な出力結果が出るように試行錯誤しました)
開始文章:They were
生成する文章の長さ:635文字
乱数シード:9
ロジットのスケーリング係数:2.0(予測可能を高くする設定)
完成した文章は次のようになりました。
They were the piece of the water.
“Nothing,” said the engineer; “Neb,” replied the engineer, “but I am on the horizon,” said Cyrus Harding, “but I do not think that the matter?”
“It is not to the construction, and would not have guess,” answered the engineer, “that it was not less than a chouse and resource the ‘Duncan’ construction of the island.
“But the corral, and it was lighted, that at the corral!” replied the engineer; “but if that is to say, the fire for the colony, and the reporter and Ayrton,” replied the engineer; “but the sand, and all the
colony was careful to the east, for the hunters, crowned to the sea by the island.
DeepLで翻訳してみましょう。
翻訳結果は次のようになりました。
彼らは、水の作品だった。
"何も、"エンジニアと答えた。"ネブ、"私は地平線上にある、"サイラス・ハーディングは、"しかし、私はその問題を考えていない?
"それは建設にではなく、推測していないだろう、"エンジニアは、"それはチャウスとリソースよりも少なかったこと、島の'ダンカン'建設に答えた。
"しかし、家畜小屋で、それが点灯していた!"エンジニアは答えた。"しかし、それはコロニーのための火災、記者とアイルトン、と言うことであれば、"砂、およびすべての。
コロニーは、東に注意していた、ハンターのために、島によって海に戴冠した。
「They were the piece of the water. ~彼らは、水の作品だった。~」
なんて詩的な表現!
始まりは感動的です。1文1文に区切ってみると、言葉が何とか成立している感じです。
しかし、文脈が整っておらず、また、登場人物の発言部分が適切に区切られていないなど、文法上の雑さが目立ち、文章全体がおかしな様相を醸しています。DeepL翻訳による日本語訳も揺らいでいます。
これはこれで味わい深いのかもしれません。
もしやこれは、シュルレアリスムのオートマティスム小説なのかも!?
ちなみに、シュルレアリスム小説といえばアンドレ・ブルトンの『溶ける魚』ですね!
リカレントニューラルネットワークに話を戻します。
このモデルは簡易的なものであり、大した文章を生み出すことはできないでしょう。
訓練にあたっては、長編の小説を「40文字という短い文章に刻んで学習」しています。新しく生み出す文章が長くなればなるほど、おそらく奇っ怪なテクストを編み出すに違いありません。
けれども、AIが小説を生成する、と言うことがどういうことなのか、を考えさせられるモデルでありました。
まとめ
今回は、ジュール・ヴェルヌの小説『神秘の島』を学習して文章を生成するモデルについて、PyTorchでリカレントニューラルネットワークを実装しました。
英語読解能力が不足しており、英語文章のニュアンスを理解しかねるため、学習した結果がどうなのかについて、言及することは出来ません。
ただ、著作物を学習に使うことの危うさのようなことを実感いたしました。
# 今日の一句
print('We were the piece of the earth.')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はリカレントニューラルネットワークの学習アルゴリズムであるBPTTにて訓練時に求める勾配計算の式を紹介します。
$$
\cfrac {\partial L^{(t)}}{\partial \boldsymbol{W}_{hh}} =
\cfrac {\partial L^{(t)}}{\partial \boldsymbol{o}^{(t)}} \times
\cfrac {\partial \boldsymbol{o}^{(t)}}{\partial \boldsymbol{h}^{(t)}} \times
\left(
\displaystyle \sum^t_{k=1}
\cfrac {\partial \boldsymbol{h}^{(t)}}{\partial \boldsymbol{h}^{(k)}} \times
\cfrac {\partial \boldsymbol{h}^{(k)}}{\partial \boldsymbol{W}_{hh}}
\right)
$$
おわりに
「日本統計学会公式認定 統計検定2級 公式問題集[CBT対応版]」
データサイエンスの基礎を補強する上で、確率・統計の知識は欠かせないものになっています。
統計分野の資格の代表格が「統計検定」。
そして、統計検定2級の公式問題集がCBT対応になって新発売です!
CBT方式とは、コンピュータを利用して実施する試験方式です。
これまでの公式問題集は紙ベースのPBT方式試験時代の問題を掲載していました。紙の時代の問題はとても味わい深いのですが、CBT方式の問題と整合していないこともあり、CBT試験の訓練としてはいまひとつ、手応えを感じにくい面がありました。
試験対策がしやすくなった今が、統計検定2級にチャレンジするいいタイミングではないでしょうか。
いずれは、このnoteで統計検定2級のCBT試験解読の記事を書いてみたいです(時間がほしいです)。
お知らせ
MADAOコミュニティからのお知らせです。
あの宇宙旅行の前澤友作さんが数十万人のメンバーを集めて会社をつくるコミュニティを運営しています。
ただいま、前澤さん主催の大規模ミーティングの開催準備中です!
ぜひ、コミュニティのホームページをご覧ください。
コミュニティに参加したい!という方は、このホームページにて入会手続きができます。
以上です。
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?