
振り返るとそこには「Python機械学習プログラミング」②承

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)の一周完走を記念して、感想を綴ります。
全19章・712ページにわたって実装を重ねた機械学習アルゴリズムとのふれあいの日々のダイジェストです。
個人的には、このテキストを一周することによって、機械学習とPythonの理解度を倍増させることができた印象です。
今回は「承」章です。
承:sklearnで軽快なMLライフ
さまざまな機械学習のライブラリを使い始めます。
3章から7章の主人公はscikit-learnです。
前章からの良い流れに乗って、自己学習曲線は順調にサクサクと心地よいカーブを描きました。
3章 分類問題-機械学習ライブラリ scikit-learn の活用
教師あり学習の分類アルゴリズムが、ぶわぁっと、一気に沸き出す章でした。
■アルゴリズム
・単層パーセプトロン:scikit-learn Perceptron
・ロジスティック回帰(一から実装):LogisticRegressionクラス
・ロジスティック回帰:scikit-learn LogisticRegression
・線形SVM:scikit-learn SVC
・カーネルSVM:scikit-learn SVC
・決定木:scikit-learn DecisionTreeClassifier
・ランダムフォレスト:scikit-learn RandomForestClassifier
・k最近傍法:scikit-learn KNeighborsClassifier
■タスク
・二値分類
・多値分類
■データセット
・Irisデータセット @scikit-learn.datasets
おなじみの顔ぶれ
活性化関数、損失関数、(対数)尤度関数と偏微分計算、正則化、サポートベクトルなどの概念を図と数式で学びつつ、ロジスティック回帰とサポートベクトルマシンのモデルを訓練してラベルを予測します。
また、ざっくりと前処理・モデル評価の機能に触れます。
層化サンプリング、標準化、正解率(accuracy)などです。
ここまでは以前に動かしたことのあるアルゴリズムだったので、円滑に進捗しました。
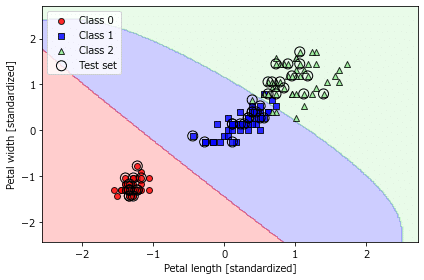
続いて、決定木に進みます。
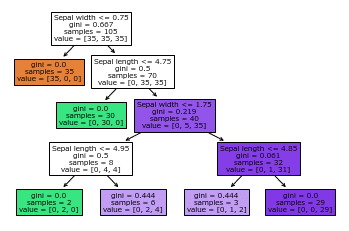
決定木のアルゴリズムを見るのは初めてなので、じっくり読みました。
ジニ不純度・エントロピー・分類誤差といった不純度の指標がありました。
テキスト掲載の具体的な数値を追いかけて、枝・葉に分かれてゆくイメージを想像しました。
XGBoostやLightGBMの中にはこんな感じの木・枝・葉がたくさん生えているんですね。
続くランダムフォレストとk最近傍法はさらっと流れてゆきまして。
分類の線引きのプロットはいつ見ても楽しいです。
x軸=1、y軸=1あたりの青い出っ張りなど、鑑賞ポイント満載です。
この章で学べる統計検定のトピックを紹介します。
📘統計検定準1級トピック
18章 質的回帰:ロジスティック回帰モデル
19章 回帰分析その他:(ロジスティック)シグモイド関数
23章 判別分析:サポートベクターマシン
32章 シミュレーション:ブートストラップ標本
4章 データ前処理-よりよい訓練データセットの構築
データ前処理を集中的に実践する章です。
機械学習アルゴリズムは「特徴量選択」との関わりを取り扱っています。
■アルゴリズム
・ロジスティック回帰:scikit-learn LogisticRegression
・k最近傍法:scikit-learn KNeighborsClassifier
・ランダムフォレスト:scikit-learn RandomForestClassifier
■タスク
・多値分類(3クラス)
■データセット
・Wineデータセット @UCI Machine Learning Repository
前処理・特徴量選択の主な実践内容は次のとおりです。
■前処理
・欠損値処理:pandas
・カテゴリ変数のエンコーディング:pandas、scikit-learn
・訓練データセット・検証データセットの分割:scikit-learn
・特徴量スケーリング:scikit-learn
■特徴量選択
・L1/L2正則化:scikit-learn LogisticRegression
・逐次特徴量選択アルゴリズム SBS(一から実装):SBSクラス
・特徴量の重要度の評価:scikit-learn RandomForestClassifier
入力データの側面から基礎固め
淡々と処理をこなしていく、こんな流れになりました。
プロットのお勧めは、ロジスティック回帰のL1正則化。
正則化パラメータ$${\lambda}$$の逆数である、ハイパーパラメータ C の値を小さくする(図では左に近づく、$${\lambda}$$の値は大きくなる)ほど、特徴量の重みが0に収束してゆくのです。
カラーパレット勢ぞろいです。

この章で学べる統計検定のトピックを紹介します。
📘統計検定準1級トピック
16章 重回帰分析:L1/L2正則化(ただし回帰の例)
29章 不完全データの統計処理:欠損値の削除法・代入法
5章 次元削減でデータを圧縮する
特徴量抽出による次元削減の3つの手法に取り組みます。
教師なしの主成分分析(PCA)、教師ありの線形判別分析(LDA)、次元削減の可視化手法 t-SNEです。
■アルゴリズム
・主成分分析 PCA:scikit-learn PCA
・線形判別分析 LDA:scikit-learn LinearDiscriminantAnalysis
・t-SNE:scikit-learn TSNE
・ロジスティック回帰:scikit-learn LogisticRegression
■タスク
・多値分類(3クラス)
■データセット
・Wineデータセット @UCI Machine Learning Repository
主成分分析、線形判別分析は統計検定でお馴染みの手法です。
統計検定の取り組みのときに主成分分析とお友達になれた(はず)なので、再会の喜びをかみしめました。
テキストは、行列の操作について、平易な文章、適度の数式、NumPyのコードをうまく繰り出していて、読者のココロをギュッとつかむでしょう。
共分散行列(np.cov)、固有値分解(np.linalg.eig)などなど。
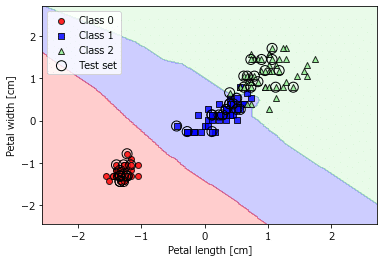
入力データの13個の説明変数から、2つの特徴量を抽出して、ロジスティック回帰でWineの分類を予測します。
次の図は、主成分分析で抽出した2つの特徴量でロジスティック回帰を行った結果のプロットです。まずまずの性能です。

この章で学べる統計検定のトピックを紹介します。
📘統計検定準1級トピック
22章 主成分分析:主成分分析の計算、寄与率、主成分負荷量
23章 判別分析:フィッシャーの線形判別分析、正準判別分析
6章 モデルの評価とハイパーパラメータのチューニングのベストプラクティス
モデルの評価とハイパーパラメータのチューニングを集中的に実践します。
また、前処理と訓練を一括りに実行できるパイプラインに取り組みます。
■アルゴリズム
・ロジスティック回帰:scikit-learn LogisticRegression
・線形SVM・カーネルSVM:scikit-learn SVC
・決定木:scikit-learn DecisionTreeClassifier
■タスク
・二値分類
■データセット
・Breast Cancer Wisconsinデータセット @UCI Machine Learning Repository
性能評価、ハイパーパラメータのチューニングの主な実践内容は次のとおりです。
■パイプライン:scikit-learn make_pipeline
■モデルの性能評価
・ホールドアウト法
・k分割交差検証法:scikit-learn StratifiedKFold
■バイアス・バリアンスの診断
・学習曲線/検証曲線:scikit-learn learning_curve
■ハイパーパラメータのチューニング
・グリッドサーチ:scikit-learn GridSearchCV
・ランダムサーチ:scikit-learn RandomSearchCV
・Successive Halving:scikit-learn HalvingRandomSearchCV
■性能評価指標
・混同行列:scikit-learn Confusion_matrix
・適合率・再現率・F1スコア:scikit-learn precision_score, recall_score, f1_score
・ROC曲線・AUC:scikit-learn roc_curve, auc
ものすごい情報量に圧倒されました。
My学習曲線が気になるところです。。。
各種ライブラリを使って簡単に性能値を可視化できたなら・・・(空目)

この章で学べる統計検定のトピックを紹介します。
📘統計検定準1級トピック
23章 判別分析:混同行列、適合率等の評価指標、ROC曲線
30章 モデル選択:交差検証法
7章 アンサンブル学習-異なるモデルの組み合わせ
複数のアルゴリズムを組み合わせたり、1つのアルゴリズムでたくさんの分類器を組み合わせたりして、モデル性能の向上を狙うアンサンブル学習の世界に突入です。
■アルゴリズム
・ロジスティック回帰:scikit-learn LogisticRegression
・決定木:scikit-learn DecisionTreeClassifier
・k最近傍法:scikit-learn KNeighborsClassifier
・多数決アンサンブル分類器(実装):MajorVoteClassifierクラス
・バギングアルゴリズム:scikit-learn BaggingClassifier
・Adaboostアルゴリズム:scikit-learn AdaBoostClassifier
・勾配ブースティングアルゴリズム:xgboost XGBClassifier
■タスク
・二値分類
■データセット
・Irisデータセット @scikit-learn.datasets
・Wineデータセット @UCI Machine Learning Repository
多数決アンサンブルクラスを実装をします。
ちなみに、著者はscikit-learnの多数決アンサンブルクラス「VotingClassifier」を実装したのだそうです。すごい。
多数決アンサンブルクラスを利用して、ロジスティック回帰+決定木+k最近傍法の多数決でアヤメを予測します。
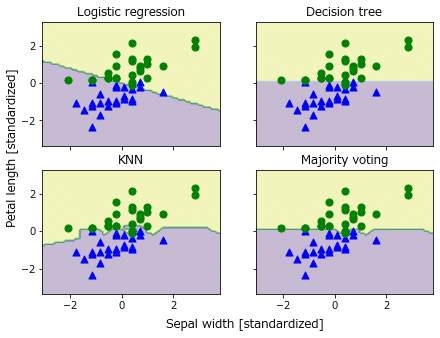
勾配ブースティングの二値分類
勾配ブースティングのゾーンでは、数字例を用いたノードの分割の様子がとても分かりやすくて、理解が進みました。
一方で、XGBoostの使い方の説明は超あっさり。
緩急の使い分けが三振の山を築く秘訣なのかも(表紙へ)。
おまけ:scikit-learnの勾配ブースティング
「scikit-learnはLightGBMにヒントを得て、HistGradientBoostingClassifierを実装している」とテキストに書かれていました。
テキストはこのアルゴリズムのサンプルコードを提供していないので、ネットで調べて、実験してみました。
このサイトの内容を参考にしました。ありがとうございました!
Kaggleの「タイタニック号データセット」を用いて、複数モデルの性能値「交差検証法による正解率」を比較しました。
このときはランダムフォレストに軍配が上がったようです。
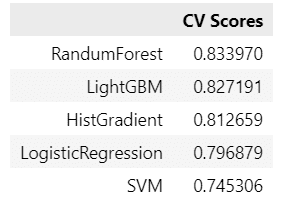
この頃から、テキストの内容を飛び出して、ネットで情報を収集して、いろいろな実験を試みるようになりました。
つまり、沼にハマり始めたのです。
そして、テキストのサンプルコードの裏に隠された落とし穴にハマり始めたのも、この頃なのです・・・。
「破」へ続く
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「日本統計学会公式認定 統計検定2級 公式問題集[CBT対応版]」
【決定】新連載「のんびり統計」が始まります!
現在、数記事を書き溜めているところです!
新連載では「統計検定2級 公式問題集[CBT対応版]」をテキストにします!
統計学に興味をお持ちの方と一緒に学習を進める気持ちで書きます!
データサイエンスの基礎固めとして、また、データ分析の手始めとして、確率・統計を学んでみませんか?
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?