
18章 GNN:分子の分極率をグラフニューラルネットワークで予測する

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第18章 グラフニューラルネットワーク-グラフ構造データでの依存性の捕捉」の「18.4 PyTorch Geometricライブラリを使ってGNNを実装する」をGoogle Colabで実行した結果を紹介します。
今回はGPUを使っています。
18章のダイジェスト
18章では、グラフニューラルネットワーク(GNN)に挑戦します。
次の図のように、グラフデータは丸で示した「ノード」(頂点)と線で示した「エッジ」(辺)によってノード間の関係性を表現するデータ構造です。
路線図、分子構造、PERT図などがグラフデータの例になります。
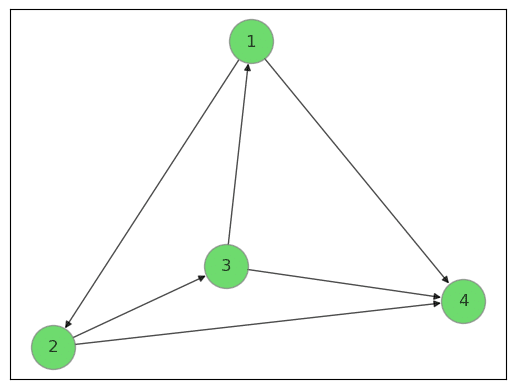
グラフ構造とグラフ畳み込みの概念を理解した後に、PyTorch Geometricを利用して、QM9データセットを学習して等方性分極率を予測します。
グラフ構造、グラフニューラルネットワークの概念やアウトプットのイメージがぼんやりしているので、実践を進めることが楽しみです。
QM9は、量子化学計算に基づいた機械学習用の大規模データセットです。
13万超の低分子化合物とラベルの情報が含まれています。
等方性分極率は、分子の電荷分布が外部電場によって歪められる度合い、だそうです。
次のサイトでQM9データセットを取得できます。
分極率については、Wikipediaをご一読ください(ちんぷんかんぷん)。
グラフニューラルネットワークをやってみて
1. 分子とグラフニューラルネットワーク
分子の結合とグラフのエッジ特徴量
分子は原子が結合したものです。
原子どうしの結合の仕方が単結合か二重結合かなど、分子にとって結合のタイプは重要な特徴量になります。
分子の結合は、グラフのデータ構造に置き換えると、エッジ(辺)にかかる特徴量=エッジ特徴量になります。
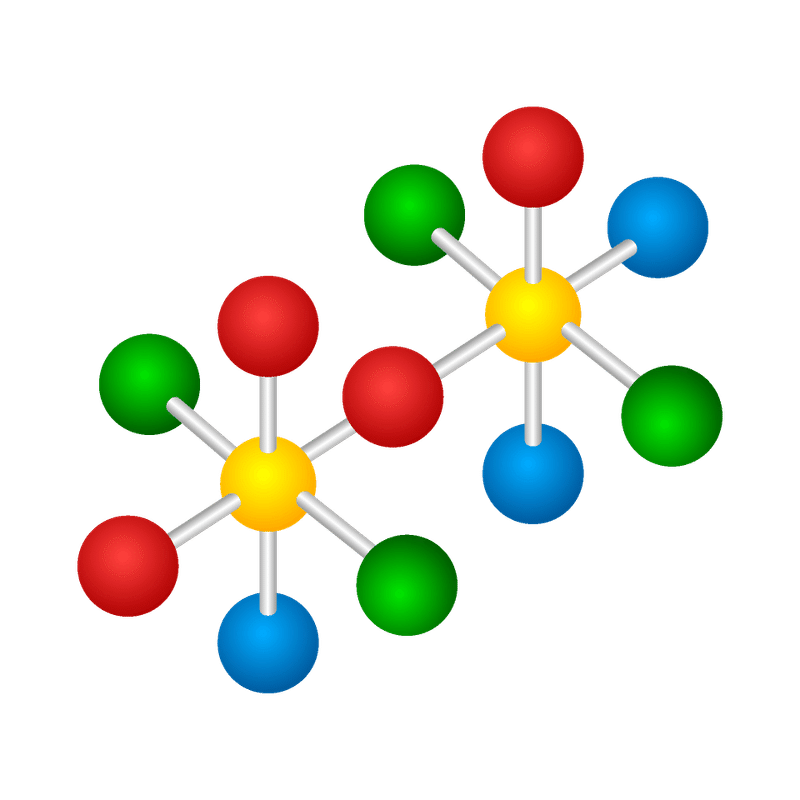
QM9データセットと特徴量
テキストでは、QM9データセットをPyTorch Geometricのdatasets.QM9を利用して読み込みます。エッジ特徴量の情報は、Dataオブジェクトの edge_attr に格納されます。
ちなみに、ノード特徴量はDataオブジェクトの x に、予測対象となる等方性分極率はDataオブジェクトの y のインデックス位置1に格納されます。
エッジ特徴量とグラフ畳み込み
エッジ特徴量をグラフニューラルネットワークのグラフ畳み込み層で利用します。
テキストでは、グラフ畳み込みの実装にPyTorch Geometricのtorch_geometric.nn.NNConv層を利用します。
NNconv層の数式表現は次のようになります(なるそうです)。
$$
\boldsymbol{X}^{(t)}i = \boldsymbol{WX}^{(t-1)}_i +
\displaystyle \sum_{j \in N(i)} \boldsymbol{X}^{(t-1)}_j \cdot h_{\theta}(e_{i,j})
$$
数式の記号は次のような内容を表すそうです。
$${\boldsymbol{X}}$$はノードラベル行列(おそらく)
$${\boldsymbol{W}}$$はノードラベルの重み行列
$${h}$$はエッジラベルに基づき、重みの集合$${\theta}$$によってパラメータ化されたニューラルネットワーク
また、$${N(i)}$$はノード$${i}$$の近傍の集合を表し、インデックス$${j \in N(i)}$$は近傍のノードを表します。
グラフ畳み込みの実装イメージ
テキストのサンプルコードでは ExampleNet クラスでグラフ畳み込み層を実装しています。
xはノード特徴量、edge_indexはエッジリスト、edge_attrはエッジ特徴量です。
# ExampleNetクラス(テキストのサンプルコードの抜粋)
class ExampleNet(torch.nn.Module):
def __init__(self, num_node_features, num_edge_features):
....
self.conv1 = NNConv(num_node_features, 32, conv1_net)
....
def forward(self, data):
....
# 1つ目のグラフ畳み込み層
x = F.relu(self.conv1(x, edge_index, edge_attr))
....2. 訓練前の準備
意外に時間がかかること
Google Colabを実際に使ってみて、時間を取られたのがライブラリのインストール処理です。
Google Colabにはたくさんのライブラリがインストール済みなのですが、今回のグラフニューラルネットワークの実装では、以下の3つのライブラリのインストールが必要でした。
# 必要ライブラリのインストール
!pip install torch-geometric
!pip install torch-scatter
!pip install torch-sparseインストールにかかった時間は以下のとおりです。
PyTorch Geometric : 16秒
torch-scatter : 14分
torch-sparse : 32分
下の2つは、PyTorch Geometricが内部処理で使用しているものです。
インストールしないと、torch_geometric.datasets等のインポート処理でエラーになります。
これらのインストールに14分、32分と時間を要しています。
時間がかかる理由は不明です(ご存じの方、教えてください!)。
Google ColabでPyTorch Geometricを使う時は、インストール時間がかかることを念頭において計画を立てましょう。
3. 訓練処理
テキストのコードをそのまま実行します。
訓練データ110,000個、検証データ10,831個、テストデータ10,000個を用いました。
テキストではエポック数を4回で打ち切っています。
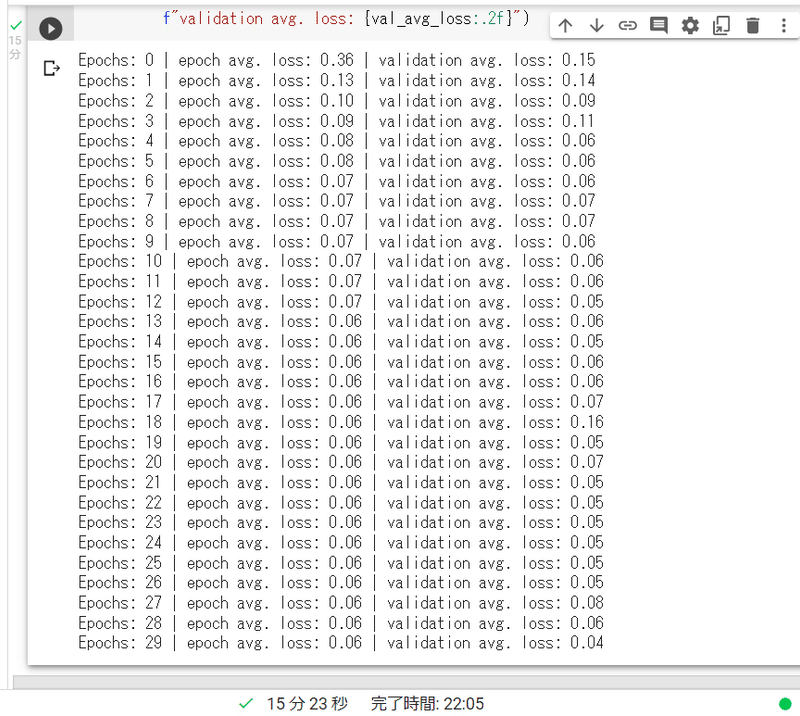
今回、Google ColabのGPU環境で、エポック数を①4エポック、②30エポックの2パターンで訓練してみました。
訓練処理にかかった時間は次のようになりました。
①4エポック:2分
②30エポック:15分23秒
1エポックあたりおよそ0.5分でした。
100エポックの訓練でもおそらく1時間はかからないでしょう。
4. 性能値
30エポック
予測する等方性分極率は連続値の目的変数であり、損失関数は平均二乗誤差(MSE)です。
訓練データのMSEは0.06、検証データのMSEは0.04になりました。
テキストの4エポックでの性能値は、訓練データで0.09、検証データで0.07です。
30エポックの方が損失値が低くなったようです。
予測値と正解値のプロット
テストデータ10,000個の予測値と正解値のプロットは次のようになりました。
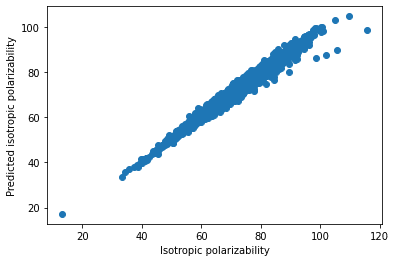
対角線に集まっており、精度良く予測できている感じがします。
ただ分極率が高くなるほど、ばらつきが高くなるような傾向も見られます。
5. グラフニューラルネットワークと創薬
今回は、分子を題材にして、グラフデータ構造とグラフニューラルネットワークの関係に触れることができました。
ところで、テキストによると、グラフニューラルネットワークは創薬と深い関係があるそうです。
最近では、「TorchDrug」という、創薬のためのPyTorchベースの機械学習プラットフォームが開発され、グラフ機械学習、深層生成モデル、強化学習の手法をサポートするライブラリ等を提供しているそうです。
# TorchDrugのインストール
pip install torchdrugまとめ
今回は、Google Colabの環境で、PyTorch Geometricライブラリを利用して、QM9データセットを用いてグラフニューラルネットワークのモデル訓練を行い、低分子化合物の等方性分極率を予測しました。
グラフニューラルネットワークによる分子構造の解析が創薬につながることも学びました。
機械学習が社会に役立つ技術であり続けることを願わずにはいられません。
同様に、社会のために機械学習を利用することが我々の責務なのかもしれません。
# 今日の一句
print('-'*33)楽しくPython機械学習プログラミングを学びましょう!
雑記
ちなみに、いまだにパソコン環境にPyTorch Geometricライブラリをインストールできていません。。。
インストール時にコンフリクトが見つかり、Examining conflictの処理が走ってしまいます。
困ったものです・・・。
おまけ数式
noteでは数式記法を利用できます。
今回はグラフラプラシアンに基づくグラフ畳み込みの式を紹介します。
$$
\boldsymbol{X}^{\prime} = \boldsymbol{Q}(\boldsymbol{Q}^T\boldsymbol{X}⦿ \boldsymbol{Q}^T\boldsymbol{W})
$$
$${\boldsymbol{Q}}$$はグラフラプラシアン行列$${\boldsymbol{L = Q \lambda Q}^T}$$の直交行列であり、その列は$${\boldsymbol{L}}$$の固有ベクトルです。また、$${\boldsymbol{W}}$$は訓練可能な重み行列、⦿演算子は内項の要素ごとの乗算を表します。
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「AI・データサイエンスのための 図解でわかる数学プログラミング」
ビジネスの現場では今後、数学的知識の必要度が高くなると言われています。
この書籍は、図解によって数学的な考え方を直感的に説明し、Pythonのコードを動かしてみて計算を体感することを目的に書かれています。
カバーする領域は、確率統計、機械学習、数理最適化、数値シミュレーション、深層学習です。
この書籍では、最適ルート探索問題、シフトスケーリング問題といった数理最適化と数値シミュレーションのネットワークモデルあたりでグラフ表現を利用しているようです。
ディープラーニング、Python、数学を一体として学習できるチャンスですね!
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?