記事一覧



進化的アルゴリズムをもちいたChatVector加算の最適化
はじめにこれまで何度かChatVectorやそれに類することを施行してきましたが、元のモデル+ChatVectorの加算はいつも1:1で実施してきました。それでもある程度上手くいっていましたが、この加算比率をSakanaAIのEvoLLMのように最適化するということができるらしいです。
ただ、調べた限りコードが落ちていなかったので自分なりに調べて試してみたというのが本記事の内容になります。
1.
Chat VectorとMath Vectorは併用できるのか
はじめにこの記事は以下記事の続きになります。
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
この発想から、Chat能力以外にも能力の切り貼りはできるのかという検証が前記事までの趣旨となります。
結果以下の通りです。
⭕️ Chat(論文)
× Code
⭕️ Math Reasoning
なので
Chat VectorならぬMath Vectorは作れるのか
はじめにこの記事は以下記事の続きになります。
Chat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
この発想から、Chat能力以外にも能力の切り貼りはできるのかという検証が本記事の趣旨となります。
今回は以下の能力について試したいと思います。
数学的推論能力
結論だけ書くとある程度うまくいきました。検証記録
Chat VectorにならぬCode Vectorは作れるのか
はじめにChat Vectorと呼ばれる、重みの足し引きでFine TuningなしにChat能力を事前学習モデルに付与できるという技術あります。
つまりこういうことですね。
ChatVector = Llama2-chat - Llama2
でChat能力を抽出し、
New-Model-chat = New-Model + ChatVector
でNew-ModelにChat能力を付与でき
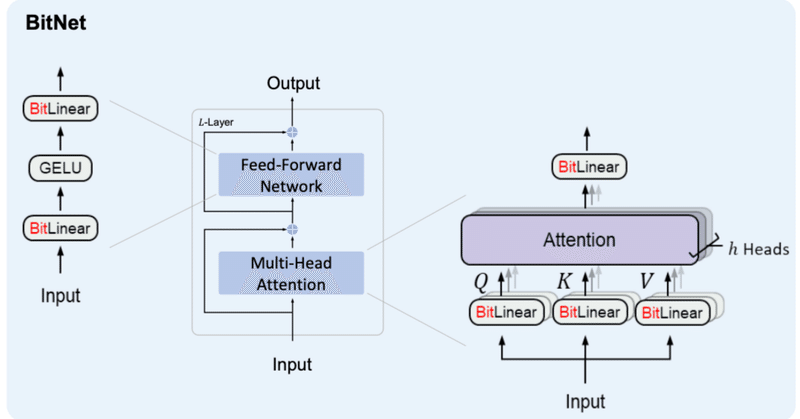
BitNet&BitNet b158の実装④
はじめに前回、BitLinear b158の実装を行いました。前回までの内容は以下をご参照ください。
4. BitNet b158の検証BitNetの検証と同様、
BitLlamaでBitLinear158bを利用できる様に修正
事前学習ができるか(Lossが下がるか)確認
を行います。
4-1. BitLlamaの修正
modeling_bit_llama.pyにおいて、BitLin
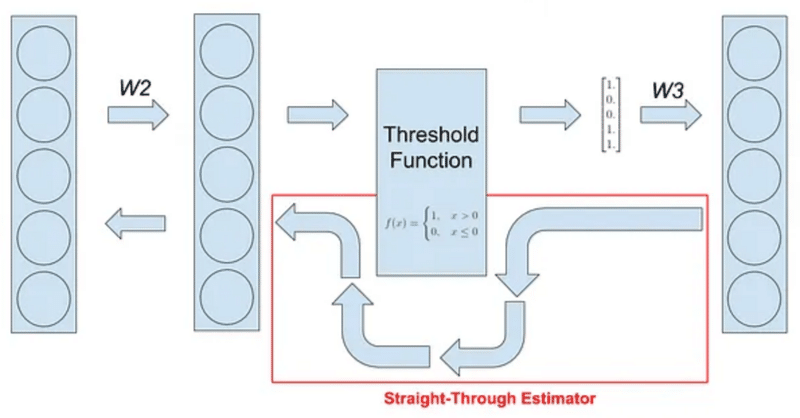
BitNetにおけるSTE(Straight-Through Estimator)の実装
はじめに現在、私は以下のような試みをしています。
BitNetとは
BitNetとはweightとactivationを量子化する手法の1つで、特にweightを{-1, 0, 1}の3値に量子化するBitNet b158はベースとしているLlama2の性能を上回ることを示し、注目を浴びました。
その実装の中で、量子化(つまりFloat16や32ではなくより離散的な値を扱う様にする処理)を行
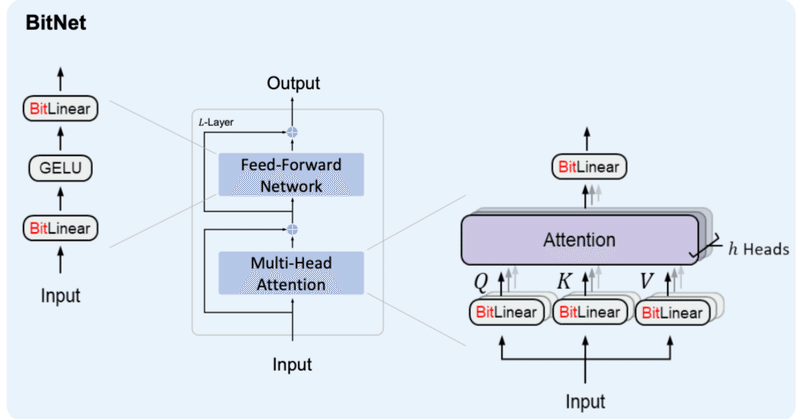
BitNet&BitNet b158の実装③
はじめにBitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、記事を分けることとしました。前回までの内容は以下をご参照ください。
2日連続での投稿となるので前後関係をお気をつけください。
3. BitNet b158これまでに作成したBitLinearを修正していく形でBitNet b158用のBitLinear b158を作成していきます。
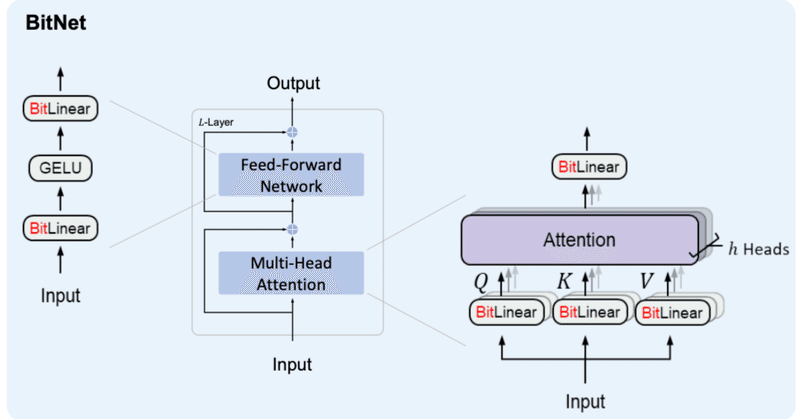
BitNet&BitNet b158の実装②
はじめに少し間が空いてしまいましたが、BitNetおよびBitNet b158の実装を続けていこうと思います。
ボリュームが大きくなってきたため、ページを分けることとしました。前回までの内容は以下をご参照ください。
2. BitNetの検証今回は、前回作ったBitNetの検証を進めていこうと思います。
検証内容としては、
BitLlamaの構築
事前学習ができるか(Lossが下がるか)確認
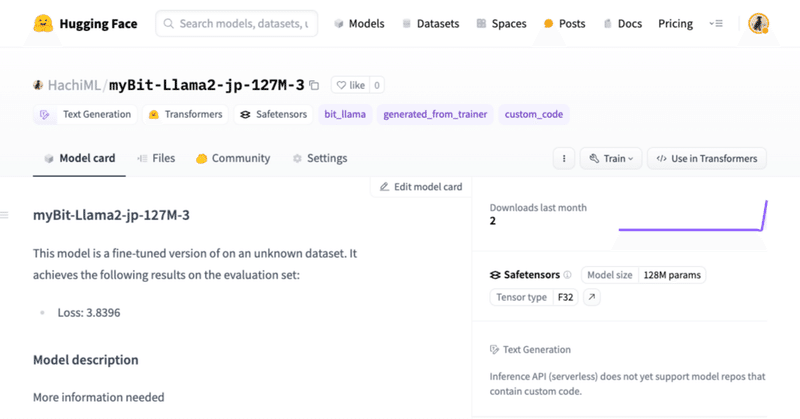
自作アーキテクチャのモデルをHuggingFaceにプッシュする方法
はじめに現在、私は以下のような試みをしています。
その中で、自作アーキテクチャ(Transformersに実装されていない)モデルをHuggingFaceにpushすると、当たり前ではありますがそのアーキテクチャでは重みをloadできないことに気づきました。
なので、
自作アーキテクチャ(Transformersに実装されていない)モデルをHuggingFaceにpush
できる限り簡単にA
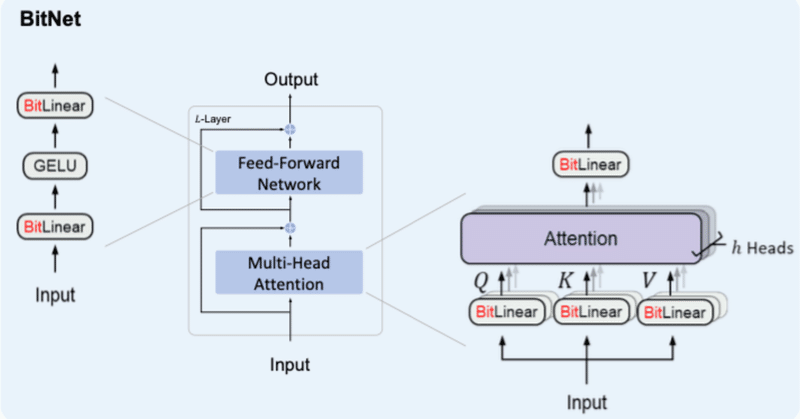
BitNet&BitNet b158の実装①
はじめに先週発表された論文『The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits』は多くの人に衝撃を与えたと思います。
それまで量子化とは、有り体に言えば性能を犠牲にメモリ等のコストを抑える手法でした。しかし、BitNet b158(*)では量子化手法としては初めてオリジナルを超える性能を出す可能性を魅せてくれました。
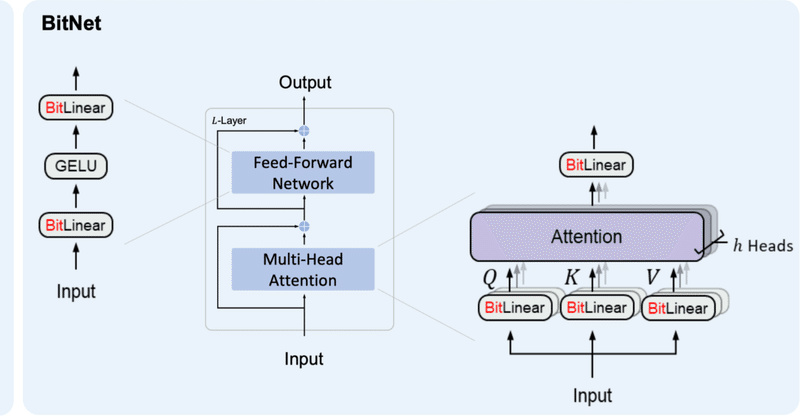
既存日本語LLMをBitNetで置き換えて実行してみた
はじめに昨夜からBitNetという1bit量子化LLMが話題になっていました。
簡単な概要としては、
既存のLLMが1パラメータをFP16やBF16などのfloat型で扱っているものを、1パラメータで{-1, 0, 1}しか扱わない様にした。
計算に使う情報量を削ることで、処理速度の向上、メモリの節約が叶う。
3B params以上ではベンチマークスコアの平均で同サイズのLlamaを上回る結
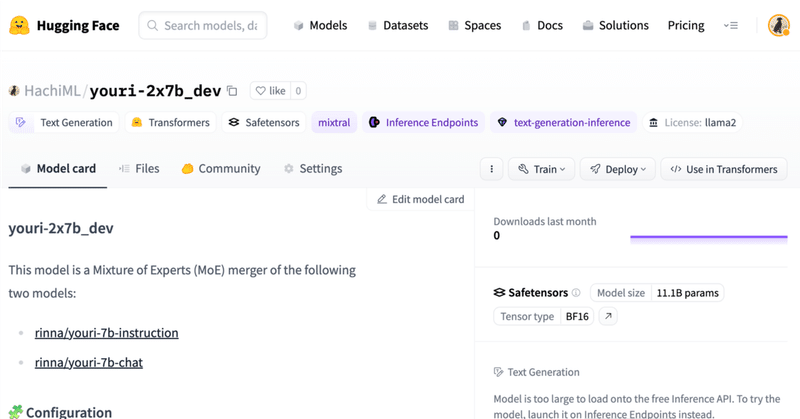
Mergekitを使ったMoE(Mixture of Experts)作成のテクニック
はじめに以前行ったMergekitを使った日本語MoEの作成(以下記事)がそこそこ上手くいったものの、かなり手探りで実施した感があった。
そんな中、有志でベストプラクティスがまとめられているのを知ったのでその要約を自分のためにここにまとめようと思う。
忙しい方は4. まとめ だけ読めば雰囲気は確認できると思う。
1. 概要章の構成は以下の通り。
Overview
What makes a
Google Colab:Mergekitによる日本語モデルMoEの作成
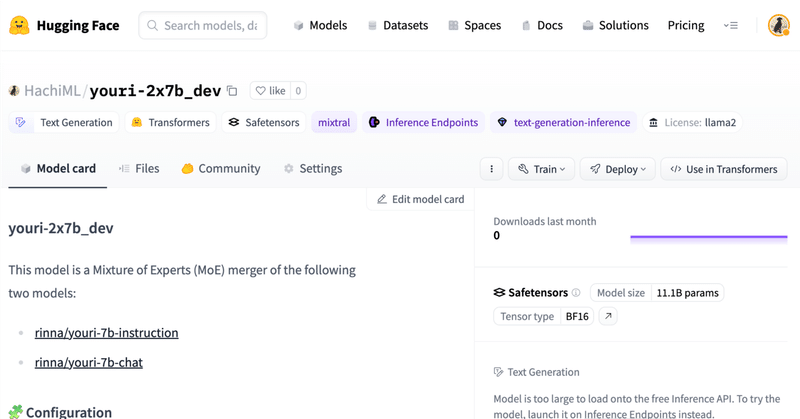
0. はじめにMistral AIによるMixtral -8x7bモデルの成功により、最近MoE(Mixture of Experts)モデルが流行ってきている気がします。
他にもPhi-2のMoEであるPhixtual-2x2bとかありましたね。
それに倣って、日本語モデルのMoEも作ってみたくなって試してみました。
以下が作ってみたモデルです。
1. Configファイルの作成config
既存日本語ベンチマークについての調査結果
LLMの日本語性能を確認するためのベンチマークとして、
・現状使われているもの
・使えそうなもの
について調べてみました。
1. 課題感近年、ChatGPTを筆頭としたLLMの成功・活躍から、多くのLLMが発表されています。英語のモデルに遅れてではありますが、そうした流れを受けて日本語に強いモデルも出てきてはいます。
英語モデルは多様な観点でその能力を測るベンチマークが多く整備されています。そ