ガバメントクラウド先行事業における「性能」「可用性」要件を整理する

前回は、ガバメントクラウド先行事業に関連する要件に対して、どのようなスタンスで今後整理していくかについて、まとめさせていただきました。まだご覧になっていない方は、まずは以下をお読みいただけるとスムーズです。
今回の先行事業における単一のクラウドサービス事業者として、有力なのはAWS(Amazon Web Service)です。Native Public Cloudの筆頭とも言えるので、こちらのクラウドサービスで「性能」及び「可用性」の要件について整理していきたいと思います。
17業務に求められる要件
まずは、どんな要件が求められるのかを、事前に整理します。
性能については、自治体規模によって求められるものが変わってくるので、特に明確なものはありません。どちらかと言えば、既存のシステム構成と同様の性能が出ることが求められることになります。
可用性については、以下のURLにある「地方自治体の業務プロセス・情報システムの非機能要件の標準(標準非機能要件)」に具体的なサービスレベルの記載があります。こちらには99.5%を担保するように書かれています。
これらの観点から以下の検討を進めていきます。
AWSの仮想マシンサービス『EC2』
AWSの仮想マシンを提供するEC2というサービスを見ていきましょう。このサービスは以下の特徴があります。簡素化している説明になりますので、網羅していない箇所があるかもしれませんので、ご了承ください。
・インスタンスタイプ(CPU数とメモリ容量の組み合わせ)を選択して利用
・オンデマンド(時間単位料金)もしくはリザーブド(年単位等の事前支払い)の購入方法
・スタンドアロンの構成ではSLAが90%と定義
・Availability Zone※で冗長化した構成であれば、99.99%のSLAの提供
順を追って説明していきます。
インスタンス
EC2の利用には、CPU数とメモリ容量の組み合わせセットを選択する必要があります。以下のURLにあるような様々なファミリーに分かれています。
また、以下の表にあるように、CPU数とメモリサイズの組み合わせの中から選択することになります。VMwareの環境では、好きなCPU数とメモリ容量の組み合わせセットで仮想マシンを作成していたと思いますが、AWSでは用意されたものから選択することになります。そのため、CPUは4つでもメモリが32GB欲しいという場合においては、メモリの容量を得るために、m5.xlargeではなく、m5.2xlargeを選択する必要があり、CPU数を4つ追加せざるを得ないケースもあります。

また、4CPU 16GBメモリの構成は、m5.xlargeだけではなく、さらに良いCPUを使ったm5zn.xlargeといったインスタンスタイプも4CPU 16GBメモリとなり、同様のスペックとなります。つまり、実際に動いているハードウェアの性能によって、同じスペックだったとしても性能が異なることになります。そのため、既存の仮想マシンスペックと同じCPU数とメモリ容量のインスタンスタイプを選んだからといって、全く同じ性能が出るわけではありません。
我々の方でも具体的なベンチマークをしてみましたが、弊社もおそらくAWSさんも具体的なベンチマークテストのスコアを公開することは許されていませんので、こちらを読んでいる方の中でご興味ある方は、ぜひご自身で検証していただきたいとは思いますが、おおよその感覚をお伝えいたします。
物理サーバー上でVMware環境の4vCPU 16GBメモリの仮想マシンの性能を1とすると、以下のような感じでした。
・m5.xlarge(4vCPU 16GBメモリ): 0.7 (70%程度の性能)
・m5zn.xlarge(4vCPU 16GBメモリ): 1.0(同等の性能)
・t3.2xlarge(8vCPU 32GBメモリ) : 1.0(同等の性能)
このように、今までの仮想マシンと同等のスペックを出すためには、厳密には検証してみないとわからないということになります。こちらの結果の通り、同一スペックで同程度の性能が出るインスタンスもあれば、それに足りないインスタンスもあります。さらにスペックを上げたインスタンスでないと同等の性能が出ないケースもあります。これらを踏まえて、インスタンスの金額感を見ていきましょう。
購入方法
EC2の金額は、以下のURLから計算できますが、先の章で取り上げたインスタンスタイプの費用を見ていきましょう。
まずは、同じインスタンスでも、オンデマンド(時間課金)の場合と、リザーブド(事前支払い)の場合を見てみます。3年の場合で事前支払いのほうが65万円程度安価になります。時間ごとに課金している分、同一期間利用した場合にはリザーブドインスタンスのほうが安価になるような価格付けです。

次は、m5.xlargeと同一スペックながらも高性能なm5zn.xlargeの料金はリザーブドインスタンスでの比較ではおよそ20万円ほど高価です。やはり性能が出る分、コストも掛かるということになります。ここで言えるのは、同じスペックを持ったインスタンスの中で安い方を選ぶと性能が出ないケースがあるので、高くてもきちんと検証した上でインスタンスタイプを選ぶ必要があるということです。
続いて、以下の比較をします。
・m5.xlargeをリザーブドインスタンスとして2台常に動かしている
・m5.xlargeを1台リザーブドインスタンス、もう1台を必要に応じてオンデマンドで利用

結果としましては、6年(72ヶ月)で計算した場合は、後者においては、2台めを6年のうち3年以内しか動かさなければ、安価になります。1台めのEC2の使用率に応じてオンデマンドを立ち上げ、不要時には削除する仕組み(オートスケール)を設定すれば、性能不足時に時間利用をすることでコストが最適化されます。
ただし、オートスケール利用時には以下のことに留意しながら構成する必要があります。
・どのような条件でオンデマンドインスタンスを立ち上げるか
・どのような条件でオンデマンドインスタンスを削除するか
・インスタンスを追加する場合には、追加までの時間を想定して条件を設定する
・インスタンスを削除する際には、どのように負荷分散から外していくかを想定して設計する
このような料金体系を見ていると、どちらかと言えば、事前に性能を検証して準備するというよりは、利用しているインスタンスタイプで性能が足りなければオートスケール等でインスタンスを追加しながら、求める性能を得られるような構成に改良していくようなことが求められるのかもしれません。
SLA(可用性)
AWSのサービスにはSLAが設定されていることがほとんどです。このSLAをクリアしなければサービスクレジットとして返金しますという仕組みになっています。そのため、必ずSLAが守られるというよりは、返金をするかの判断基準としての意味合いが強いのかもしれません。先の章では、可用性に関するEC2の特徴として、以下を挙げました。
・スタンドアロンの構成ではSLAが90%と定義
・Availability Zoneで冗長化した構成であれば、99.99%のSLAの提供
EC2のSLAについて書かれた資料は以下になります。
その中から抜粋したものが以下になります。

こちらには99.99%と記載がありますが、あくまで複数のAZ(Avalilability Zone)にEC2を配置した場合に得られるSLAとなります。単一のAZでのSLAは以下の記述に従います。

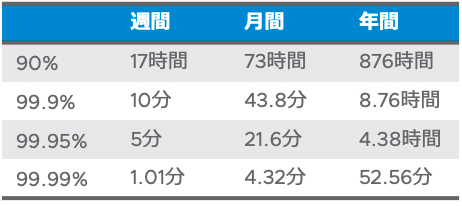
90%のSLAがどれくらいの停止が想定されているかについて、以下の表にまとめてみました。つまり、SLAが90%だと週に17時間止まることを許容するということになります。
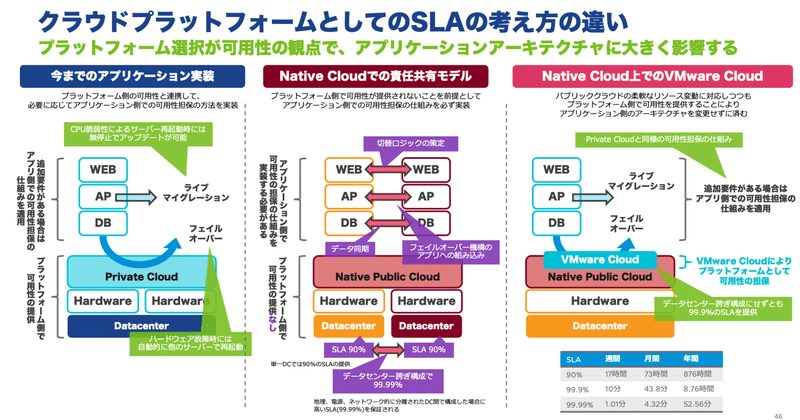
一般的にオンプレミスの場合は、プラットフォーム側で可用性が提供されます。更に追加要件がある場合は、仮想マシン間でクラスタを組むなどしてきました。そのため、サーバー障害の際には、別のサーバーで仮想マシンが再起動してくれるようなフェイルオーバーをすることで、可用性が提供されていました。また、サーバーのCPU脆弱性に対応するためファームウェア更新をする際には、サーバー再起動が必要になります。このような場合には、ライブマイグレーションにより、仮想マシンを止めずに別サーバーに避難させ、対処後に元の場所に止めずに戻すといったことが可能でした。

一方、AWSを始めとするNative Cloudは、責任共有モデルと言われるアーキテクチャで構成されています。ハードウェアは箱として扱われ、最低限のSLAのみが提供されます。システムとしての可用性は、ユーザー側のアプリケーション側で担保するように分担するという考え方です。複数AZにEC2を配置する構成にすることで、提供されるSLAを99.99%まで上げることができますが、AZ間のデータ同期や切り替えロジックをアプリケーション側に実装するか、クラスタソフトウェアを利用するなどが求められます。それだけでなく、複数AZにEC2を配置するため、今まで1台で可用性が提供されていた仮想マシンを冗長化する必要があり、コスト的にも2倍必要になっていきます。
複数AZ構成を検討する際にも、考慮点が存在します。単に複数AZ構成にするだけだと、SLA90%のEC2(WEB)に障害が起きると、AZ切り替えが発生することになります。そんなに頻繁に起こることが問題であれば、AZ内での冗長化を検討する必要があります。また、2つのAZを合わせて100%の性能を提供している場合には、片方のAZに障害が起きると縮退運転になってしまいます。それが許容できない場合は、それぞれのAZで100%の性能が発揮できる構成にするためにEC2仮想マシンが増えていきます。

このようなことを考慮していくと、元々1台だった仮想マシンをSLA担保のために2,3,4台構成と増やしていくため、コストが増加するだけでなく、システム構成に考慮が必要となります。さらに、EC2以外にもSLAを考慮する必要があり、RDSというデータベースサービスは複数AZ構成にしても99.95%のSLAになり、微妙にEC2とは異なります。また、AZ切替の基準を判断するようなCloudWatchという監視サービスのSLAは99.9%のため、切替判断をする際に監視側が利用できない状態に陥っているということも理論的には起こりえます。このようにコンポーネントごとのSLAを加味しながら、複数AZの構成を組んで行く必要があります。
ここまでのお話は、プラットフォームとしてのSLAの話です。アプリケーション観点でも考えないといけないことが出てきますので、例を見ていきましょう。
アプリケーションサーバーでは、負荷分散の都合上、セッション情報をお互いに共有しあっていて、急な障害が起きてもユーザーが操作をやり直す必要がないようにしていることが多いと思います。そのために、アプリケーションサーバー間をマルチキャスト通信をすることで、セッションを複製しているケースがあります。しかしながら、AWSのVPC内ではマルチキャスト通信が許可されていません。つまり、別のセッションレプリケーション方式の実装や、memcachedやElastiCacheといった実装をアプリケーション側に組み込む必要が出てくるため、アプリケーション観点でも改修をしながらSLAを担保するための仕組みに介入しなければなりません。

長くなりましたが、ここまでが最も利用されるであろうAWSにおける性能と可用性に関する要件をクリアするための考慮点となります。これらを意識しながらシステムを組むことが、後々のトラブルに繋がらないためのポイントとなります。
性能と可用性に関するVMware Cloudのアプローチ
ではAWS上で利用できるVMware Cloud on AWSを利用した場合、性能と可用性についてはどのように考えればよいのかを整理します。

VMware Cloud on AWSは、AWSのデータセンターに存在する物理サーバー上にプライベートクラウドと同様のアーキテクチャの仮想化インフラストラクチャを提供するサービスです。そのため、1物理サーバーが購入単位となります。AWSのデータセンターに構築されるため、Native Cloudとの連携・使い分けも密接におこなうことができます。また、利用する物理サーバーのスペックが非常に高いため、オンプレミスと同じスペック以上の性能を期待できます。

また、仮想環境のバージョンアップや障害対応もVMwareが提供されるサービスに含まれるため、運用のための料金も考慮が不要です。
可用性に関しては、先程整理した図に追加する形で説明します。Native AWSの環境では単一AZ内でのSLAは90%でしたが、VMware Cloud on AWSの場合は、VMware Cloudが提供するプラットフォーム側でのフェイルオーバーやライブマイグレーションといった可用性向上の仕組みが利用できるため、単一のAZで構成された場合でも99.9%のSLAを提供します。そのため、標準非機能要件(99.5%)を超えることが可能です。こちらにより、今まで1台構成だった仮想マシンも、複数台立てることなく、クラウド上で稼働させることができるようになります。
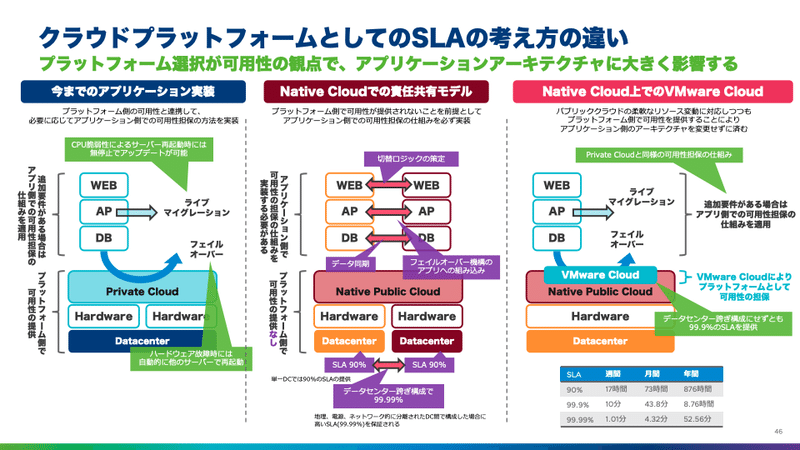
もちろん、複数AZ構成を組むことも可能です。その場合は、SLAが99.99%まで上がります。
まとめ
ガバメントクラウドを利用したシステム構成を検討する際には、以上のような考慮点を踏まえて試算することをお勧めします。どちらかの仕組みに寄せることが意味のあることかもしれませんし、使い分けることも可能なソリューションなので、クラウドを利用することのメリットを最大化できるかもしれません。
個人的には、Native CloudはEC2単位で仮想マシンを追加できるので、追加単位ごとの価格上がり幅が非常に少なくて済みます。逆に、VMware Cloud on AWSは購入単位が物理サーバーとなるので、上がり幅が大きいです。そのため、少ない仮想マシン数の場合には、EC2のほうが価格的に有利になっていると思います。ただ、EC2は使っても使っていなくても稼働していれば、利用率に関わらず課金されてしまうので、今回の対象とならない業務システムや、17業務以外もガバメントクラウドに載せていくと、仮想マシンが多くなっていくことが想定されますが、物理サーバーに性能の許す限り仮想マシンを立てられるVMware Cloud on AWSのほうが価格的有利になっていくと思います。

いずれにせよ、性能と可用性はクリティカルにシステムの稼働に影響する要素のため、慎重に構成していただければと思います。あくまでここでの費用感は、インフラとしての費用だけを勘案した場合について、コメントしておりますので、その他の要素も含めてコスト試算をしてみていただければと思います。
Native AWS構成における、乱暴な試算という意味では、以下の手順は有効です。
・既存のスペックから、スペックアップしたインスタンスもしくは同一スペックでも良い性能が出るインスタンスタイプを選ぶ
・SLAを考慮して複数AZ構成にするために、必要インスタンス数を倍にして試算する。
パブリッククラウドサービスは、インターネット上に価格が公開されていますので、サーバー一覧をお持ちの方は、構成をしてみることで金額感を掴んでみることをお勧めいたします。
次回は、移行性やバックアップについて、整理していきたいと思います。