
ChatGPTは基礎科学論文まで押し寄せる!?

2022年末にリリースされた対話サービスChatGPTが今でも話題です。
科学研究の分野にも影響を与えており、とある研究でChatGPTによる要約かどうかを見分けられるかを試した記事がNatureに載っています。
ようは、
人間かChatGPTかを見分けることは難しいので、インセンティブ設計など他の要素で対策を講じる必要がある、
という話です。
専門性がある分野でもやはり難しいみたいです。ただ今の基礎科学は専門性が高すぎて、例えば同じ分野の数学者でもちょっと違うと理解が難しくなるとは以前に聞いたことがあります。
それはまた別の話ですが、興味深いのは、これに対してChatGPT自体を問題視するというよりは、論文数だけで安易に評価しない制度にするなどを提案しています。
実は既に一部ではChatGPTを禁止しているところもあります。
Stack Overflowというサービスでは不正確な回答があったらしく暫定的な処置のようですが、結構考えさせられるのはニューヨーク市の学校での使用禁止です。
行政側の主張では、問題解決スキル育成につながらない、ということです。
表面的には賛成ですが、ここまでAIが進化し見極めが難しいといたちごっこにならざるをえないのだろうと想像します。
宿題の在り方を、AIを使うことも織り込んだうえで問題解決スキルを学べる、という流れもあるかもしれません。
そのときには、問題設定から考えさせて、その仮説に対してどのAIを使ったのかも記載させるというイメージです。いずれはそういった学校・授業も登場するかもしれませんね。
ただ、上記の行政コメントで、ChatGPTの背景技術を学ぶことはアクセスしてもOKとしており、これは意義深いと思います。
例えば、OpenGPTは下記でその技術的な方法論を公開しています。
ようは、
人からのフィードバックによる強化学習を中心に設計している、
という話です。
和訳版だと下記のサイトが分かりやすかったので紹介しておきます。
最近AIの分野では、この強化学習をRLHF(Reinforcement Learning from Human Feedback)と総称しています。
上記図にあるChatGPTのフローを引用しておきます。
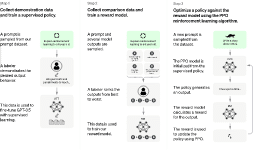
報酬モデルとしては、アルゴリズムとしては以前より知られているPRO((Proximal Policy Optimization))が使われています。
で、それもたどっていくと既存アルゴリズムの応用で、根っこを辿る方策交配法が基本になっているようです。
例えば下記サイトで技術的に説明されています。名前の通り「方策」を先に決めておいて、価値を最大化する最適解を探ってくるようです。
ここまでくると、なかなか技術的に追っかけていくのは困難です。
ただ、完全なブラックボックスだと冒頭記事のような問題提起は今後も出てくると思います。
そして2023年はGPT4もリリース予定で、さらに拍車がかかるかもしれません。
今回で言えば、強化学習の1パターンという程度でよいのかもしれませんが、今後も最低限知っておくべきラインは自分なりに持ち合わせて、常に疑いながら試行するしかないのかなと感じました。
この記事が気に入ったらサポートをしてみませんか?