
【3分で理解】ディープラーニングとは?その手法を入門者向けに解説!

こんにちは、村田泰祐です。サイバーエージェントのAI事業本部というところで働いています。「AIをビジネスに応用できるプロダクトマネージャー」を目指しています。
今回はディープラーニングがどのタイミングで世の中に広く知られたのか、そしてどのようにしてディープラーニングというアプローチは成り立っているのかを説明していきます。
ディープラーニングがここまで発展できたのは過去の人工知能の研究があったからこそです。ディープラーニング以前の技術については以下の記事を読んでいただけると分かるかと思います!
【3分で理解】ニューラルネットワークを解説!前編「パーセプトロン」とは?
【3分で理解】ニューラルネットワークを解説!後編「多層パーセプトロン」とは?
上記の記事にもありましたが、ディープラーニングは頭打ちになっていた人工知能の研究を前進させます。その前身のタイミングがいつだったからかを見ていきましょう。
2012年に起きたディープラーニングの衝撃
ディープラーニングがなぜここまで世の中で大きく注目されているのでしょうか?
転換点は2012年の世界的な画像認識の大会「ILSVRC(Imagent Large Scale Visual Recognition Chaellenge)」でのことです。
この大会では、ある画像に写っているものがヨットなのか、動物なのか、花なのかなどコンピューターが自動で当てるタスクが振られ、その正答率の高さで争います。1000万枚の画像データを機械学習し、15万枚の画像を使ってテストします。
2010年から始まったこの大会では、エラー率26%台で数%の差を争ってきました。オックスフォード大学、東京大学などが出場していて1%を改善できるかでしのぎを削ってきたわけす。
しかし、2012年に初参加のトロント大学がエラー率15%台という圧倒的勝利を収めます。

引用:Review: AlexNet, CaffeNet — Winner of ILSVRC 2012 (Image Classification)
上の棒グラフは当時の大会のエラー率の結果です。縦軸がエラー率ですが、グラフのいちばん左のsuperVisionだけ他のものにくらべてエラー率が低いのが分かります。(ちなみに、ISIは東京大学)
トロント大学はわずか97文字で、どんな技術を用いたのか説明していました。それが「ディープラーニング(深層学習)」なのです。
2006年に発表されたオートエンコーダ
人工知能の研究者たちに衝撃を与えた2012年からさかのぼること6年前。優勝したトロント大学のジェフリー・ヒントン教授は「Reducing the dimensionality of data with neural networks.」という論文を発表しています。
以前のnoteで説明しましたが、ニューラルネットワークの多層パーセプトロンは①勾配消失による誤差が入力層までに正しく伝播されない問題②多層ニューラルネットワークの表現力が高すぎる問題を抱えていました。
これらの問題をヒントン教授はオートエンコーダ(自己符号化器)を利用して「一気に学習するのではなく、少しずつ学習を進めていく」方法を提唱しました。
オートエンコーダは「情報圧縮器」のようなものです。上の論文の英語タイトルも日本語訳すると「ニューラルネットワークを用いたデータの"次元圧縮"」です。
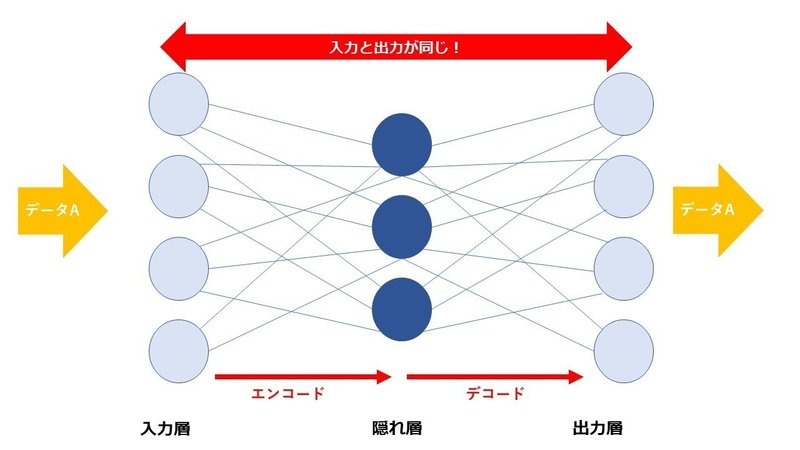
オートエンコーダーの図
オートエンコーダーは入力層と出力層に同じデータを与えて学習する方法です。図だと入力層にデータAを与え、出力層にもデータAを与えて答え合わせをします。
これに何の意味があるのか。入力層と出力層の情報が同じであることで「入力の情報が圧縮」されます。実は2004年にジェフ・ホーキンスという実業家が、このオートエンコーダの方式を予想していました。オートエンコーダを「八百屋に行って新しいバナナを買うときに古いバナナで支払うようなもの」という独特の表現で例えています。
入力層→隠れ層における処理をエンコード、隠れ層→出力層における処理をデコードといいます。
ヒントン教授はオートエンコーダを積み重ねていく「積層オートエンコーダ」を考えました。この積み重ねこそ、まさにディープと呼ばれる所以なのです。
入力層に近い層から順に学習を行うことが肝心で、オートエンコーダを順番に学習していくことを事前学習といいます。
最後の仕上げ「ファインチューニング」
オートエンコーダは入力データのみを使う教師なし学習で、出力データはありません。そこで、最後にロジスティック回帰層(シグモイド関数もしくはソフトマックス関数による出力層)を足すことで、教師あり学習を実現させます。
そして最後にディープニューラルネットワーク全体で学習させて、深層でも誤差が逆伝播します。これをファインチューニングといいます。
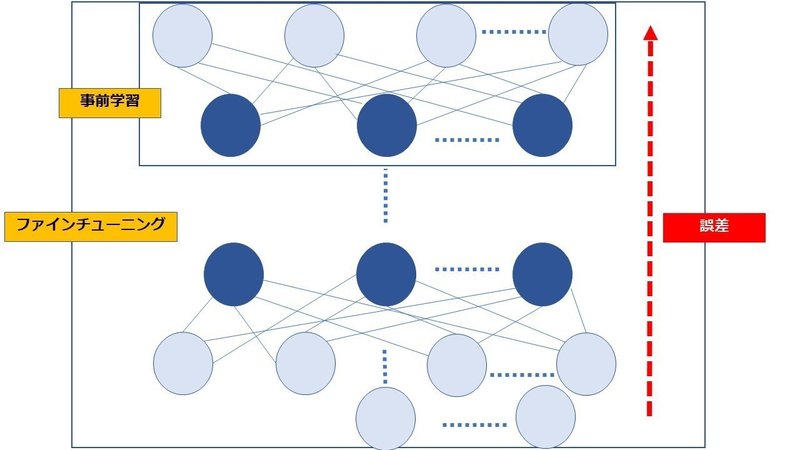
積層オートエンコーダの工程
積層オートエンコーダは、事前学習とファインチューニングの工程で構成されるのです。
ここまで、ディープラーニングがどいういった手法かを説明してきました。しかし、多層ニューラルネットワークの表現力が高すぎる問題をどう解決したのか、そしてヒントン教授が2006年に発表する以前から2004年にジェフ・ホーキンスや1980年代から日本では似たようなアイデアは昔からあったのになぜ実現されてこなかったのかの謎が残ったままです。
次回は、その辺りについて解説していこうと思います。
いただいたサポートは書籍購入費に充てます!