
Google Colab でSAM:Segment Anything Modelを試す

「Google Colab」で「SAM」を試したのでまとめました.
1. SAM:Segment Anything Model
「SAM」は追加学習なしでどんな画像でも領域を塗り分けること(=セグメンテーション)ができます.また,プロンプトとして画像中の座標点や矩形領域(バウンディングボックス)を指定して,任意の領域だけをセグメンテーションすることもできます.
ただし,あくまでセグメンテーションのみを行うもので,どの領域がどのクラスを示す,というような分類は行いません.
また,サンプルとして次の3つが公開されています.
predictor_example.ipynb:座標を指定してマスクを生成するSamPredictorクラスを使うもの
automatic_mask_generator_example.ipynb:自動で全ての領域に対してマスクを生成するSamAutomaticMaskGeneratorクラスを使うもの
onnx_model_example.ipynb:ONNXモデルとしての出力などを操作するもの
2. インストール
このコマンドでインストールが可能.公式のインストールガイドはこちら.
pip install git+https://github.com/facebookresearch/segment-anything.git
要件はこの通り.
Python>=3.8
torch>=1.7
torchvision>=0.8
※torch,torchvisionはCUDAインストールが推奨されている
3. サンプルプログラムの内容
今回は3つのサンプルのうち,自動で全ての領域に対してマスクを生成するSamAutomaticMaskGeneratorを試してみました.
日本語用にカスタマイズしたものがこちらです.
本家のプログラム内での処理を見出しごとにざっくり書いてみます.
(1)Environment Set-up
segment_anythingのインストール,デモ用の画像とモデルのチェックポイントのダウンロードを行います.
(2)Set-up
ここではライブラリのインポートとマスク画像の描画を行う関数の作成を行います.
(3)Example Image
デモ用の画像をopencvで読み込んでmatplotlibで表示させます.
マスク生成の説明で変数を使うので読み込み部分のコードを載せておきます.
image = cv2.imread('images/dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)(4)マスク生成:Automatic mask generation
SamAutomaticMaskGeneratorクラスを使ってマスクの生成を行います.
モデルの読み込み→GPUへの転送を次のコードで実行します.
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)マスクの生成にはgenerateメソッドを呼び出して画像のデータを与えます.
masks = mask_generator.generate(image)masksにマスクの情報が含まれています.
マスクごとに次の項目の情報が辞書型配列でまとまっていて,
[{マスクAの辞書}, {マスクBの辞書}, …, {マスクAAの辞書}, {マスクABの辞書}]という形式で返ってきます.
segmentation : マスク
area : マスク領域のピクセル値
bbox : バウンディングボックス(XYWH形式)
predicted_iou : マスク領域のIoU値
point_coords : マスクの生成に使った座標(SAMでは座標を指定してマスクを推論するため)
stability_score : マスク精度評価用の追加指標
crop_box : マスク生成のために切り取った入力データ(XYWH形式)
(5)オプションの紹介:Automatic mask generation options
モデルを読み込む時にオプション引数を与えると,マスク生成の条件を指定することができます.
points_per_side:サンプル点の密度
pred_iou_thresh:IoUの低いマスクを削除するためのIoUに対する閾値
stability_score_thresh:マスク推論値における2値化の閾値
crop_n_layers:画像のクロップを実行する回数,2の「レイヤー層数」乗だけ実行される
crop_n_points_dwonscale_factor:クロップ実行時のスケールダウンの係数
min_mask_region_area:マスクの最小サイズ
次のようにして与えることができます.当然ですが,マスク生成の方法や戻り値は変わりません.
mask_generator_2 = SamAutomaticMaskGenerator(
model=sam,
points_per_side=32,
pred_iou_thresh=0.86,
stability_score_thresh=0.92,
crop_n_layers=1,
crop_n_points_downscale_factor=2,
min_mask_region_area=100, # Requires open-cv to run post-processing
)
masks2 = mask_generator_2.generate(image)4. モデルの違い
モデルの違いについて,サイズ,ローディング,推論の速度を記載します.
なかなかモデルが大きいので使用には注意が必要です.
モデルを読み込んだ時のGPU使用率を見てみます.
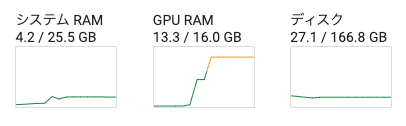

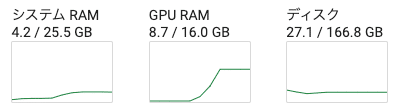
モデルごとに出力されるマスクの違いを見てみます
色の違いはランダムなのでさておき,マスクされている領域の違いに注目ですかね.

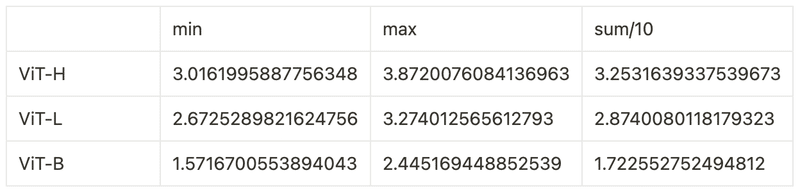
モデルごとの推論速度を見てみます.
画像1枚を推論させたときの時間を10回計測して,最小(min)・最大(max)・平均(sum/10)したものです.
モデルごとのGPUへの転送時間を見てみます.
この3行の実行時間を計測しました.
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)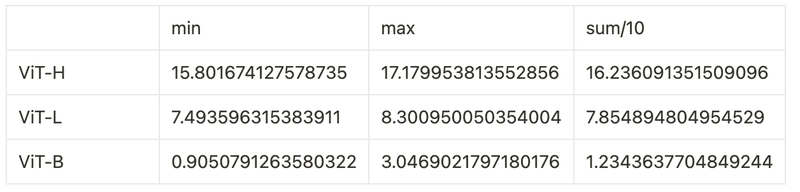
関連
Today we're releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation.
— Meta AI (@MetaAI) April 5, 2023
SAM is capable of one-click segmentation of any object from any photo or video + zero-shot transfer to other segmentation tasks ➡️ https://t.co/qYUoePrWVi pic.twitter.com/zX4Rxb5Yfo