
【米国株】Groq半導体はエヌビディアの脅威となるのか。技術面、コスト、電力消費、ビジネスモデルを掘り下げる。

4月19日、メタ(旧フェイスブック、META)が高パフォーマンスの最新AIモデルLlama3を無償で利用可能にしました。ほぼ同時にリリースされた、GPUとは異なるLPUという種類のGroq半導体を使った、Llama3による推論サービスが、爆速かつ低価格であることから、開発者コミュニティーで大きな注目を集めています。
真面目にgroq + llama3がゲームチェンジャーすぎるし、「〜が欲しい」っていって一瞬で目の前に書籍現れたらもうそれは厳密な定義としても魔法と言って差し支えないように思える。
— 元木大介@生成AI塾&Arbor言語開発者 (@ai_syacho) April 21, 2024
いよいよ「現代魔法理論」の始まりか。…
このGroqは、AI半導体業界にゲームチェンジャー的な影響を与える可能性があります。特に、現在AI半導体市場で圧倒的なシェアを誇るエヌビディア(NVDA)にとっては、無視できない存在となるかもしれません。
本記事では、Groqについて技術面、ビジネスモデル、そして競合としてのエヌビディアへの影響など、様々な角度から深掘りしていきます。Groqの優位性と課題を明らかにすることで、AI半導体業界の今後の展望について考察したいと思います。
結論を先取りすると、現時点でGroqの登場によって影響を受ける可能性があるのは、エヌビディアのデータセンター向けAI半導体事業のうち、推論用途の一部、具体的には新規AIアプリ開発者や個人利用者向けの部分で、全体の10%程度ではないかと推測されます。
ただし、LPUであるGroqの仕組みはGPUとは大きく異なるもので、スピード・電力消費など独自の大きな優位性があり、ソフトウェア面(CUDA)への対応もできています。推論分野では今後シェアを拡大していく可能性があります。現時点ではエヌビディアにとって大きな脅威とはならないものの、Groqの動向には要注目です。
LPUとは
LPU(Language Processing Unit)は、Groq社が開発した大規模言語モデル(LLM)の推論に特化した専用半導体です。LPUは、GPUとは異なるアプローチで設計されており、以下のような特徴を持っています。
Groq = LPUです。
大容量のオンチップメモリ(SRAM)による高速なモデルパラメータアクセス
高速なチップ間通信による大規模モデルの分散処理
決定論的な実行による推論結果の再現性とデバッグ・最適化の容易さ
高い電力効率による低消費電力
LPUは、自然言語処理タスク、対話システム、情報検索など、大規模言語モデルの推論の用途に特化しています。
一方、AIモデルの学習には適していません。学習には、大容量のメモリと高い汎用性が求められるため、GPUが主に使用されています。
Groqをもし試されたことが無ければ、こちらで試してみることをお勧めします。登録不要ですぐ使えます。
https://groq.com/
Groq CEOインタビューから論点抽出
この動画は、4月5日に公開されたGroq CEO Jonathan Rossのインタビューです。
略歴
グーグルで、機械学習用半導体TPU (Tensor Processing Unit) のコア要素を設計・実装
その後、グーグルXの迅速評価チームに参加し、新事業を考案・育成
2016年にGroqを設立
非常に示唆に富んだインタビューです。ハイライトは下記の点です。
Groqの性能への驚き
Groqを実際に使用した人からも、その速さがあまりにも驚異的で信じられないという声がある。
Groqのような企業が次々に現れる訳ではない
AI半導体スタートアップ100社ほどがファンディングを受けたが、GPUの5-6倍のスピードを達成可能な企業は、もう現れないだろう。
Groqは自動最適化コンパイラ(Automated Compiler)を有しており、AIモデルを自動で最適化できる。一般的にAIモデルはエヌビディアのCUDAに最適化されているが、Groqはソフトウェアのアドバンテージも含めて対応している。
LPUの仕組み
GPUは実は25%以下しか使われていないと言われている。75%のGPU時間は無駄になっている
自動車生産に例えると、GPUは狭い工場で以下のように非効率的な作業を行っているようなもの。
①車を1台ずつ倉庫から運び出す。➁各工程で必要な作業を行う。③作業が終わったら、車を倉庫に戻す
これらのステップを繰り返すため、効率が悪く、コストが高い
一方、LPUは大規模な効率的な自動車生産ラインのように動作する。
長い生産ラインを用意し、各工程に十分なスペースを確保。車が生産ラインを流れる際、各工程で素早く作業を完了
一度に大量の車を処理できるため、1台あたりのコストが安い
LPUを使ったサービスがなぜ安いのかというと、チップを使う時間が短いから。次々に処理が可能。これは、車が生産ラインの各工程にいる時間が短いことに似ている。
製造コスト、消費電力の優位性
半導体の製造コストはGPUよりも低く、消費電力も1/10。
開発者からの注目
Groq Cloudのローンチから4週間で、7万人の開発者が登録し、1.8万のAPIキーが発行された。
推論スピードの重要性
推論スピードは非常に重要であり、人は少しずつ出力される結果を追うのを好まない。
グーグルは検索結果の表示速度を絶え間なく改善してきた。それは、人が認知できないほどの差でも、速い方がより多くのユーザーに見てもらえるというA/Bテストの結果があるためである。
ビジネスモデル
Groqは半導体の販売もしなくはないが、サービスにフォーカスしている。
Groq導入は大規模な半導体からなる構成が前提となり、大きな投資が必要というデメリットがある。Groqがそれを引き受けて、サービスとして提供する。
ユーザーは作成したAIモデルをアップロードすれば、Groqが推論をサービスとして行う。
生成AIのウーバー(UBER)を目指す。
Groqのような企業はもう現れないだろう、ということから、Groqの様なスタートアップをどう認識しておけばよいか、ではなく、Groqに絞ってどう見るべきか検討すれば良さそうです。
重要なポイントを考察していきます。
LPUの仕組み
下の図は、LPUとGPUによるAI推論処理のイメージを示しています。
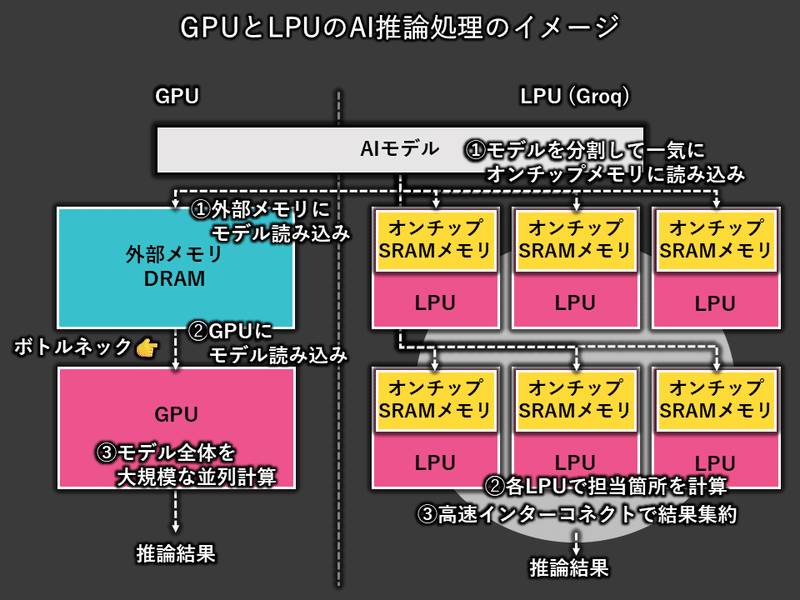
GPUとLPUの大きな違いは、AIモデルの読み込みと推論の実行方法にあります。
GPUは、推論リクエストごとに大規模なAIモデル全体を外部メモリ(DRAM)から読み込む必要があります。この読み込み処理の時間がボトルネックとなり、GPUの演算リソースが有効活用されず、使用率は25%程度にとどまるとされています。
一方、LPUは、AIモデルを複数のLPUに分割し、各LPUが担当する部分のみを高速なオンチップメモリ(SRAM)に一気に読み込みます。これにより、読み込み時間が大幅に短縮され、LPUの演算リソースを効率的に活用できます。
以下では、GPUとLPUの推論処理の流れを詳しく見ていきます。
AI推論処理のプロセス
GPUの場合:
大規模なAIモデルを外部メモリ(DRAM)に保存。
GPUは、モデルのパラメータをDRAMから読み込む。
DRAMからの読み込みは、オンチップメモリと比較すると時間がかかる。
読み込みが完了すると、GPUは処理を開始します。
大規模な並列計算の結果を集約し、推論結果として出力。
LPUの場合:
大規模なAIモデルを複数のLPUに分割。
各LPUは、担当するモデルの一部をオンチップメモリ(SRAM)に読み込む。
オンチップSRAMへの読み込みは高速で行われます。
読み込みが完了すると、各LPUは同時並行で処理を開始。
高速なインターコネクトを介して各LPUの計算結果を集約し、推論結果として出力。
LPUは、DRAMからの読み込みというGPUによる処理のボトルネック回避と、複数のLPUが同時並行で各担当部分を計算すること、によってその推論スピードを実現しています。
コスト、消費電力の優位性
機器の購入コスト
このポストを参考にさせて頂きました。https://x.com/jiayq/status/1759858126759883029
前提:LLaMA 70bモデルを用いた推論
Groqのコスト:約$11.4M
Groqカードはそれぞれ20,000ドル
一枚の搭載メモリが230MBなのでざっくり572枚のGroqカードが必要。合計約$11.4M
エヌビディア H100のコスト:約$0.3M
8枚のH100カード(1ボックス)で対応可能
1ボックスの価格は約$0.3Mドル
外部からの試算ですが、Groqの購入コストはエヌビディアH100と比較して非常に高額と試算されます。但し、これは上記で検討した、LPUは推論あたりのチップの使用時間が非常に短いため、同じ時間でより多くの推論を処理できることが加味されていない可能性がある点には留意が必要です。
また、市場での価格と製造コストは異なり、CEO Jonathan Rossは半導体の製造コストはGPUよりも低い、と言っています。
消費電力
Groqは以下のように主張しています。
https://www.prnewswire.com/news-releases/demand-for-real-time-ai-inference-from-groq-accelerates-week-over-week-302105117.html
LPUは、現在最も省エネのGPUよりも10倍エネルギー効率が良い。
これは、LPUのハードウェアとソフトウェアがデータの行き来を最小限に抑える設計になっているためである。
GPUはデータをチップとHBMメモリ間で常に行き来させる必要があり、そのためエネルギーを多く消費する。
LPUのようなトークン生成ファクトリーのアプローチにより、オフチップデータ転送を最小限に抑えられる。
この効率的な設計により、LPUは優れたユーザー体験と生産性を実現しながら、低炭素フットプリントの要件を満たせる唯一の解決策である。
消費電力に関しては、現在最も省エネのGPUよりも大幅に効率が良い、ということの様です。
開発者からの注目
Groqに質問してみるとその速度は一目瞭然ですが、推論サービスとしてのコスト競争力も注目されています。
API利用料
OpenAI
ChatGPT 4 Turbo:$15.00 / 1Mトークン
GPT-3.5 Turbo:$0.75 / 1Mトークン
Claude 3
Opus:$30.00 / 1Mトークン
Sonnet:$6.00 / 1Mトークン
Haiku:$0.50 / 1Mトークン
Groq・Llama3 (70B):$0.64 / 1Mトークン
https://artificialanalysis.ai/leaderboards/providers
Llama3という無償モデルを使っていることもあり、スピードを実現しながらも低価格で提供されています。AIアプリケーション開発者は、AIを使うにあたり、APIの呼び出し先を変更すれば良いだけなので、コスト・速度を検討して機動的に使用するAPIを選択すると考えられます。
Groq・Llama3の組み合わせは非常に競争力が高く、CEO Jonathan Rossが言うように対話アプリのみならず文字ベースのサービスにおいても、Groqの推論サービスが、ローンチから4週間で7万人の開発者が登録し、1.8万のAPIキーが発行されるなど、人気を得ています。
ビジネスモデル
ここまでのポイントをまとめると:
良い点
LPUはその仕組みから、AI推論処理スピードにおいてGPUに優位性を持つ場合が多い
Groqは自動最適化コンパイラにより、エヌビディアのCUDAに最適化されたAIモデルを自動で最適化できる。エヌビディアのソフトの強みにも対応
電力消費の優位性あり
Groqは非常に競争力の高いAI推論サービスを提供し、AIアプリ開発者に人気を得ている
悪い点
LPUは大規模な構成が必要なことから、機器購入コストはGPUと比較して非常に高い
悪い点、LPUは大規模な構成が必要で初期費用が大きい、という点を補うために、AI推論サービスにフォーカスするビジネスモデルを選択したと考えらえます。また、そのことから、LPUの価格を大量生産・販売を前提として設定しておらず、機器購入コストはあまり意味がないデータポイントかもしれません。唯一のオーダーができそうなサイトを見ると、納期は16ヶ月後、とありました。
まとめ:エヌビディアへの示唆
GroqはAI推論をサービスとして提供するため、主に半導体を販売するエヌビディアにとっては直接の競合にはなりません。しかし、エヌビディアのデータセンター向けAI半導体の40%は推論関連が占めています(前回の決算説明会でのコメント)。もし推論需要がGroqに向かえば、結果的にエヌビディアの顧客であるクラウド・サービス・プロバイダ(アマゾン、マイクロソフト、グーグル)の推論需要が減少し、GPU投資の減少につながる可能性があります。
現状、Groqに向かう推論需要は、UIやコストを重視して自由に選択できる新規AIアプリ開発者や個人利用者に限定されていると考えられます。一方、クラウド・サービス・プロバイダの主要な顧客である企業は、セキュリティー上の懸念などから、直ちにGroqへの切り替えは難しいでしょう。
そうすると、現時点で影響を受ける可能性があるのは、エヌビディアのデータセンター向けAI半導体事業のうち、トレーニング用途の60%を除く40%の一部分、つまり企業利用を除く部分で、全体の10%程度ではないかと推測されます。
ただし、Groqの推論スピード、電力消費の優位性、ソフトウェア面の対応、を考慮すると、推論分野では今後シェアを拡大していく可能性があります。また、セキュリティー等も考慮した企業向けの新サービスを提供していく可能性も。現時点ではエヌビディアにとって大きな脅威とはならないものの、Groqの動向には要注目です。
米国株インサイト
2024に始動。米国株に特化した【無料note】で、独自視点の投資判断の材料を、図表を多用し簡潔かつ深度を持ってご提供します。note🗒️更新はXでも共有いたします。Xかnoteでフォローお願いいたします🙏
Note: https://note.com/tender_deer595
X: https://twitter.com/invest_us_jp
この記事が気に入ったらサポートをしてみませんか?