製造業のIOT技術の勧め

0. はじめに
半導体製造で培われてきたIOTシステムを参考に、製造業へのIOT技術導入の参考にして頂ければと言うことで、事前に検討すべき内容から導入ステップまでをまとめてみました。
1.事前検討
1.1 IoT技術のバックグラウンド
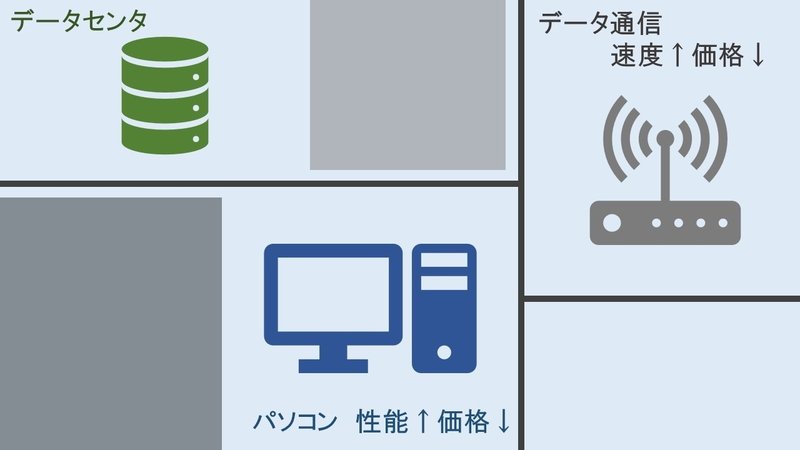
IoT技術の進化により、十分なCPU処理スピードおよび機器間での高速通信が安価に実現可能となったことから、大容量のデータ取得とその利用が、産業全般へ大きな波となって押し寄せています。まず、大手IT巨人がクラウドサービスを整備し、世界各所に巨大なデータセンターが構築されています。次に、インタネット速度の向上、移動体通信技術の革新とWiFiの普及に伴い、インタネットに繋がる利便性が飛躍的に向上しました。その次に準備されたのが、IT技術を利用するための通信モジュールです。これを、業界では、IoTユニットとか、IoT通信モジュールとかと称しています。即ち、この端末は、複数のセンサー信号をユニットに取込、無線Lanもしくは有線Lanで、データ処理を行う場所に転送するものです。この様なハード的な部分の準備は、2017年までに完了しています。
これと並行して、得られたセンサー信号の処理技術として目覚ましい進歩を達成したのが、人工知能です。一般的には、アルファ碁や将棋のponanzaが、知られています。また、顔認証等の画像処理のための人工知能の性能向上も目覚ましい。産業の中では、センサー信号の処理が大きな期待であり、機械学習や強化学習の適用が進められています。各所で、研究が進み、データマイニングの方法やアルゴリズムの整備も進んできており、一般的利用の一歩手前まで来ています。
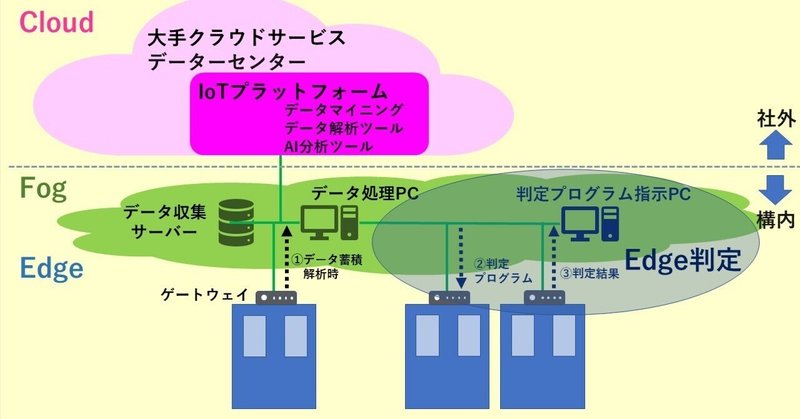
2017年後半から注目を集めたのは、IoT機器、クラウドサービスと人工知能のデータ処理を組み合わせてオペレーション出来るプラットフォームソフトです。大手IoTベンダーが、各社独自のプラットフォームをリリースし、産業界の顧客囲い込みに入った感がありました。製造業者が、IoT技術を導入しようとした場合、このIoTベンダー大手のプラットフォームを利用した方が、導入の早道であることは間違いのないところでありますが、費用対効果が求められる産業応用であり、特に、中小の企業では、この様なプラットフォームの導入は、金額的に負担が厳しいと考えられます。
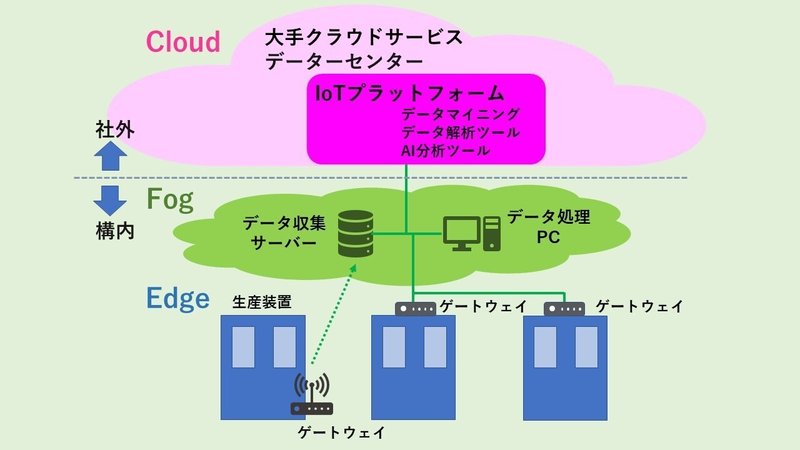
IoT利用形態として、大手ITベンダーが提唱するクラウドを利用する形態と、これに対し、フォグまでの構成で済ます形態が考えられます。生産現場で稼働する装置をエッジと呼び、ここから取集されたセンサー情報を、プラットフォームで集積し、クラウドへ送り込み、各種処理、分析から判断までを実行するのがクラウドの構成です。一方、フォグでは、生産ライン毎に処理サーバーを立てて、プラットフォームを、このサーバーで運用します。対象装置からのセンサー信号は、このサーバーに集約されて、分析から判断まで実行されます。サーバーでの処理能力は限られるため、処理すべき項目は事前に開発されている必要があります。一方、フォグ形態では、ITベンダーで開発された多くのツールを利用可能であり、汎用性が高いが、すべてのデータをリアルタイムでフォグに送り込むことは出来ず、巨大な生産ラインや、高い時間分解能が必要な信号には不向きです。中小企業を考えた場合、監視すべき信号が少ないのであれば、扱う信号毎に必要とされるPCを準備して、個別に監視する仕組みが、ひとつのソリューションと言えます。
1.2 何のために導入するのか?
IoTベンダーの営業職の方から度々聞いた話として、IoT技術花盛りの波を受けて、会社トップから、『IoTを導入して何か出来ないか?提案しろ!』と指示された社員さんから相談を受けるのですよとの声が聴かれます。会社トップは、IoTの波に遅れないように、焦っている方が多いとのこと。業務改善にIoT技術導入をすれば、株主や銀行関係者、強いては、顧客の受けが良いことは、間違いのないところでしょう。とは言っても、IoT技術、人工知能は、万能では無いわけで、只の電子回路であり、ソフトウェアです。本当は、利用者の意思が重要です。
まず、重要なことは、経営課題がどこにあるのかを把握することです。対象である課題が、IoT技術で解決される可能性があるのであれば、検討をスタートすべきです。超高齢化社会を迎える日本では、若年層の減少による労働人口の減少とともに、日本の産業を支えてきたベビーブーム世代の高年齢層の急激なリタイアに対応しなければ成りません。労働人口減少には、ロボットの導入による労働生産性の向上が必須となります。移動や加工の自動化を担う、物理的な自動化ロボットはもちろん、電話応対や、Web問い合わせに対応する人工知能も大きな効果を生み出すことになります。
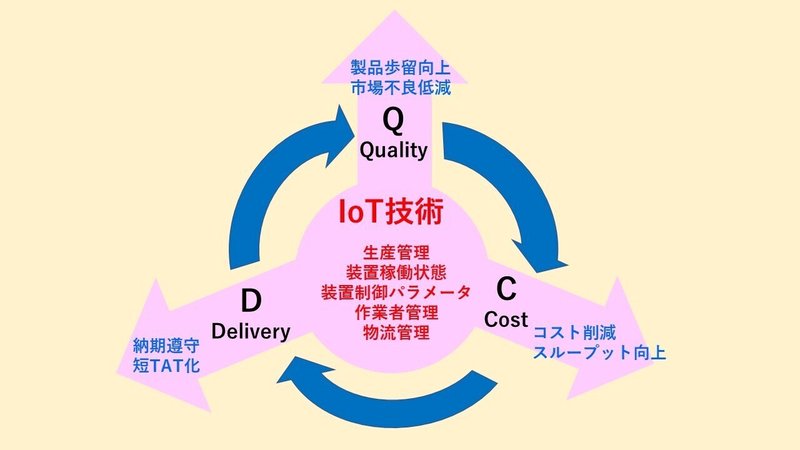
これに対し、製造業では、その重要な経営KPIは、Q(Quality:品質)、C(Cost:コスト)、D(Delivery:納期)であるはずですので、この内の何が課題で、その問題点を把握し、何に手を打っていくのかを考えなくてはなりません。一方で、Q、C、Dは、相互に強い関係性も持っています。品質が悪ければ、歩留まりが低下して、結果として、コストと納期が悪化するでしょう。コストを優先しすぎると、品質が悪化し、納期も長くなることが予想されます。納期重視のため仕掛を減らせば、コスト増を招くでしょう。顧客の要求に十分答えることが出来て、かつ、他社との競争に勝てるQ、C、Dを設計し、ギャップの存在するポイントに対策を打って行くことは、経営そのものであると考えられます。
1.3 どのレベルを目指すのか?
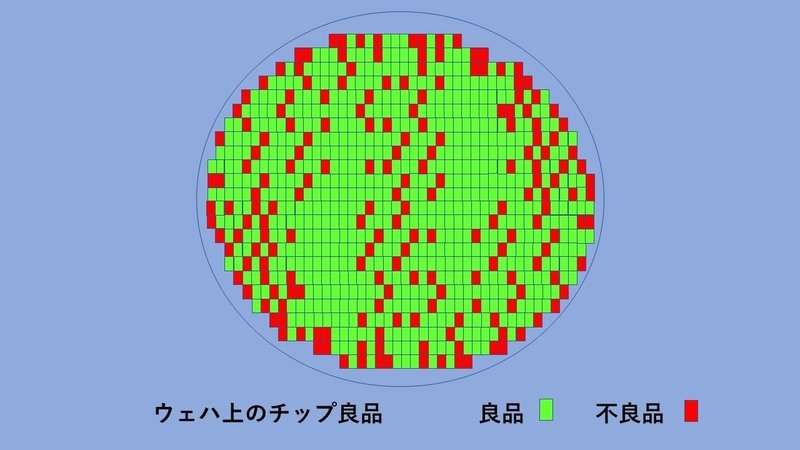
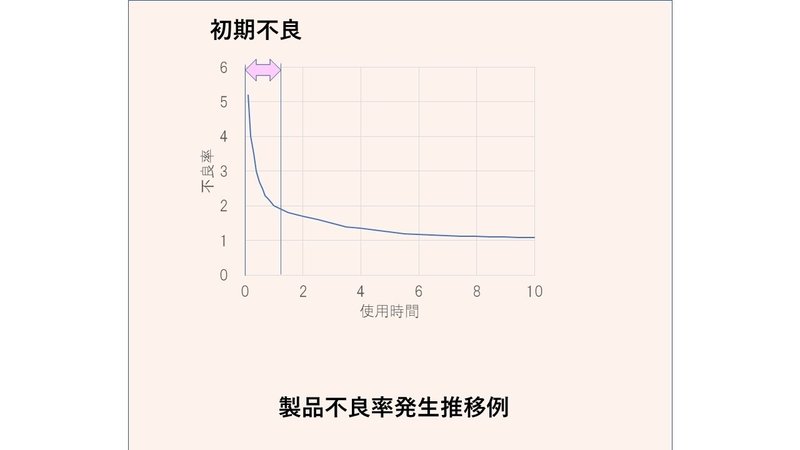
対象が、QであれCもしくはDであれ、目標とする数字が必要です。品質Qをターゲットにする場合、まず、良品率もしくは不良率がターゲットとして選ばれることになるであろう。半導体生産の場合、数百工程を数ヶ月掛けて流動した後に実施させる電気特性検査で、設定さえた電気特性が得られない場合、不良として、出荷出来ないことになります。1枚のウェハには、数百個の半導体デバイスが形成されていますが、この内、90%程度良品であれば、御の字で、70%台と言うことも、ままあり得ます。例えば、この歩留まりを10%改善出来れば、コストも10%改善出来ることも意味しており、改善のターゲットを何処にするのかにより、効果金額が決定され、おのずとそれに釣り合った投入すべき資源の大きさも決まって来ます。
半導体製品では、製品出来栄えを保証する電気特性の測定に問題の無い場合でも、稼働状況により、劣化が進み、市場不良を生み出すこともしばしば発生します。これが、社会インフラを支える機器であったり、自動車制御機器であったりする場合、市場での不良は、大きな問題となります。市場での故障発生状況を市場不良率として把握し、不良品の解析から、故障の原因を突き止めて、量産ラインの改善を日々図って行くことが、市場不良撲滅の最も確実な方法であると信じています。しかしながら、日々数万個レベルで出荷される半導体製品の記録とどの製品が市場不良を発生したのかを計数把握するのは、容易なことではないですが、それぞれの製品の量産ラインでの流動記録とあわせ、不良品の突合せが出来る体制が必要となります。自動車メーカーから要求される不良率は、1ppmを下回ることは必須であり、即ち、100万個の出荷製品に対して、一つの不良発生が許されない状況です。
コストCを対象とした場合、コスト構造を把握する必要があります。人件費、材料費、電気ガス等の用力費、修理費、償却費と言った項目に分けて、生産している製品毎に分解して、把握する必要があります。この分析結果から、支配的もしくは効果が期待出来る費用にターゲットを絞り、改善項目の洗い出しを行うべきです。Qの所でも述べましたが、歩留まりを向上させることは、ボトムアップに効果的であることは間違いが無いのです。人件費が課題の場合、徹底した作業分析を実施して、人生産性の向上を図ることが常道手段です。自動機の導入により、直接的に作業者人数を削減することも、費用対効果で判断出来るでしょう。また、最近注目されているのが、人の測位システムです。これにより、作業者の位置、行動を随時トレースすることが可能で、作業者配置の適正化、人の稼働状況の分析だけでなく、このシステムを通して、必要とされる現場への行先指示も可能となって来ています。
納期Dでは、ライン内で流動している各製品の納期の紐付けと日々の進捗状況の把握が重要です。自動車生産ラインに代表される一筆書きの生産ラインでは、スループットで納期が決まるので、ライン上でトラブルが無い限り、納期が予想できますし、完全に守られます。一方、半導体生産ラインでは、同じ装置で、同じ製品が何度も繰り返し処理される事となり、おおよそ1万m2のライン内を、数百工程にわたり、行ったり来たりする非常に複雑な生産であることから、納期管理が容易ではありません。通常は、FIFO(First in First out)の原則で生産されますが、数百工程の間に数か所の関所を設け、納期が遅れている場合には、FIFOを崩して、遅れ製品の優先を上げて、先に処理するような制御も実施しています。単純に工期を短縮するためには、ライン内の流動数を減らし、棚卸を少なくすることが常道手段です。ターゲットは、納期遵守なのか?工期短縮なのか?をキチンと設定してやる必要があります。
2.導入ステップ
2.1 対象信号の絞り込み
改善のターゲットとすべき経営指標が決定された後、次にやるべきことは、ボトルネックの抽出です。歩留まりであれば、不良を起こしている原因工程、原因装置の洗い出しが必要です。市場不良であれば、不良品の故障解析から、原因工程を突き詰めて、その問題を引き起こしている真の原因を特定する必要があります。半導体生産の場合は、この原因は、多くの場合、ゴミ=パーティクルである場合が多い。原因工程や原因装置が判明することにより、原因を引き起こす問題点も明確化するハズです。次に、特定された問題点を監視出来ることが期待される信号を、一つ以上選定する必要があります。温度、電圧、電流、材料供給量であったり、圧力等の物理量が想定されます。対象信号が一つの場合は、単変量監視で、以後のアプローチも比較的簡単ですが、複数の場合、個別に単変量の監視で十分な場合も想定されますが、そのプロセスに化学反応が伴う場合には、多変量解析が必要となり、相当に厄介となります。
改善対象がコストの場合は、コスト構造の把握が必要です。償却費に関しては、IoT技術では手の付け様がありません。但し、スループット向上に関しては、対象と成り得ます。装置の稼働状況、動作スピードを把握、分析して、装置・時間当たりの作業数量を向上させることは、直ちにコストに効いて来る課題です。搬送系やバルブのスピードや動きを監視して、遅れを是正することは、非常に有効です。時には、制御系の時間ロスがある場合も有り得ます。人がプロセス処理に関係する場合、作業分析が必要となります。稼働状態は、生産装置に稼働状況の出力機能が無い場合、機械動作の電気信号を横取りするか?動作モニターのセンサー情報を出力させるか?等の工夫が必要となります。最悪、ビデオカメラでモニターすることにより、状況監視が可能です。人が介在する場合、他者によるストップウォッチを用いた作業動作記録も有効であり、ここでもビデオ画像が大きく役立つでしょう。
納期が問題の場合は、生産管理の側面では、仕掛工程位置の把握、トレースが最大の問題でしょう。期待される工程進捗に対し、遅れを把握し、作業調整を行うことが、納期遵守の常道手段です。生産ラインが、一筆描きで構成される場合には、工程進捗の把握や納期管理は、比較的に容易であると言えます。一方、半導体の様に複雑な生産システム構成の場合は、仕掛工程位置や工程毎の仕掛量を把握するのが、容易ではありません。これを容易にするのは、製品毎、ロット毎にRFタグを装着し、自動的に位置確認を把握する方法が広く使われています。
2.2 センサー選定
IoT技術導入が急がれる中、センサーについては、車の両輪として、制御プログラムや人工知能の反対の側の車輪として、注目されて来ています。因みに、センサーとは、自然界における物理的現象や化学的状態を電気信号に変換するものであり、まさに、人間の五感に相当するIoTシステムの触角となるべきものです。

センサーからの出力結果は、IoTの世界では、すべてデジタルである必要があり、アナログ信号として得られた情報も、最終的にデジタル信号に変換する機能が必要となります。さて、センサーは読み取るべき情報によって、さまざまな種類があります。近年、センサーの需要は爆発的に増えており、さまざまな種類のセンサーが市場に出回っていますが、日本製のセンサーは、世界市場の大きなシェアを有しており、今後さらなる拡大が期待されています。IoT技術を生産現場で利用するために、どのようなセンサーを採用すべきか、どのような活用が期待されているかを知ることが、IoT技術導入で成功するために非常に重要なポイントとなります。
機械制御で最も広く用いられているのが、物体の存在を検知するセンサーであると思います。物体の通貨を検知するセンサーとして古くからあるのが、光電管を使ったセンサーであり、光を出す蛍光部と、この光を受ける受光部から構成され、その間を通過した物体が、この光を遮ることで検知します。また、物理的動作を、物理的なピンの接触で検知するマイクロスイッチというセンサーは、安価で動作の信頼性が高く、相当広く、機械制御に用いられています。その他に、静電誘導を利用して検知する静電容量型近接スイッチや、磁気の有無を検知してモノの有無や形状を認識するセンサーなどがあります。この手のセンサーは、通常可動部の動作完了の監視に使われていますが、それをIoT用のセンシングとして利用する場合には、動作指示後に指定センサーを動作せせるための時間を監視するというレベルの使い方になると思われます。
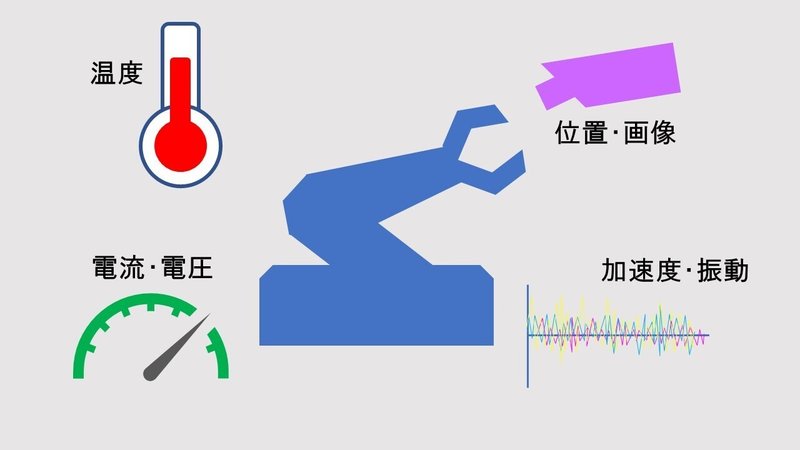
生産装置の搬送系や駆動モータの監視は、最も期待される部分です。自動製造装置では、搬送系や駆動モータの数は、膨大で、この劣化状況を把握することは、非常に大きな効果を生むものと期待されます。この監視には、加速度、回転数及び振動を検知できるセンサーが有効です。加速度センサーは半導体製造技術を応用したMEMS(Micro Electro Mechanical Systems)技術を使ったものが主流となって来ました。MENSセンサーでは、多軸方向に可動部を有した静電容量を形成し、可動部でのわずかな位置変化を静電容量の変化として捕らえ、電気回路によって増幅・出力します。また、ピエゾ抵抗素子を半導体の製造技術によって形成し、加速度によるピエゾ素子の変位を検出する種類のセンサーも広く用いられています。また、ガス温度分布型空洞部中央で暖められ、軽くなったガスが加速度によって移動程度を、周囲の温度計測抵抗ブリッジの抵抗変化で検出するタイプのセンサーも高性能です。機械的な可動部分がないため加工工程の歩留まりが良く、結果として安価に製造可能とされています。
変位を微分すると速度に、速度を微分すると加速度になることは、お分かりいただけることと思います。即ち、逆に、加速度を積分すると速度に、速度を積分すると変位として観測が可能です。駆動機械に多く用いられるベアリングの劣化には、振動信号の周波数スペクトルにより診断可能であることが知られています。即ち、駆動装置に対して選定されるべき振動センサーは、振動の高周波領域まで検出可能なものが要求されます。単なる信号値の大きさだけでなく、フーリエ変換を用い周波数成分に分けてそのプロファイルをもって判断するという方法も、より高い精度が期待できます。
温度センサーもまた重要です。生産装置や駆動機械も、異常電流が流れたり、可動部分が劣化によりこすれたり、これらの現象により熱が発生し、温度上昇を伴う劣化の発生が、簡単に想像出来ると思います。一般に温度センサーは、バイメタルによって作られ、温度によって膨張係数の異なる2つの金属を接合して、温度の変化を物理的に検知します。最も一般的な温度センサーが「サーミスター」で、温度の変化によって電気抵抗が変化する金属を組み合わせて温度を測定します。
生産装置では、燃料や冷却水をはじめ原料等を流量と言う形で、制御、管理しているものも多いと思います。流量の制御や管理は、製造対象物の出来栄えに直接影響することも多く想定され、流量の監視は、生産現場で大きなインパクトを有すると考えられます。この流量を検知するセンサーには、羽根車や浮き子式の様な機械式の物から、電磁気、渦電流や超音波を用いた電気信号を代用値として検知するものまで、多種多様です。それぞれ対象とする物質の性質と精度とコストから選定すべき方式のセンサーを決めて行く必要があります。しかしながら、IoT信号として扱うためには、電気信号として取出し可能である必要があることから、また、検知対象としての物質制約が少ないという理由から、超音波式が広く用いられています。水や油の様な液体は、もちろん、気体も検出可能であり、設置も既存の配管直線部に外から装着可能で、工事も不要な場合が多く、特に、後付けの場合には、広く用いられています。
スマートフォンの爆発的な普及によりその付随効果で、高精度なイメージセンサーが、以前と比較にならない低価格で入手可能となっています。製造業でも出来栄え検査に、画像を導入する欲求が高まってきています。即ち、人が目で見て判断する様に、イメージセンサー画像で、欠陥を検出しようと言う物です。イメージセンサーの画素数も十分増加し、また、画像処理技術も大きく向上してきたことから、キヅや欠陥に関しては、検出が可能となって来ています。色むらや表面状態の違い等は、もう少しレベルが高く、機械学習等の人工知能による画像判断の開発が必須ですが、可能な場合が多くなっています。判定速度も十分高く、人が目で見ての検査を置き換えることも可能となり、今後、導入事例も爆発的に伸びてくることも予想されます。
2.3 データ収集・蓄積方法の選定
単純な電気信号を出力するセンサー信号は、ADコンバータを介して、直接にでも接続することにより、PCにデータを収集・蓄積することが可能です。制御系を有したセンサーモジュールを用いた場合、古くから用いられているシリアル通信を用いるものであれば、PCで処理可能です。RS-232CやRS-422、RS-485、USB、シリアルATA、CC-Link等ですが、現在のPCでは、RS-232C等の接続仕様が準備されていないものも多く、USB接続が一般的となっています。現在のPC通信仕様で広く対応しているのがインサーネットと無線LANでしょう。センサーモジュールが、この通信仕様を満足していれば、接続も容易でしょう。
イントラネットの伝送速度は、高速化が目覚ましく、今では10Gbpsまで高速化された規格が標準化されています。以前は10Mbps、100Mbpsが主流でしたが、1Gbpsの通信を可能にするGigabit Ethernetが登場し、1000BASE-Tが現在最も普及しています。
無線LANは、ケーブルを使用しない無線ネットワークであり、物理的な制約を受けないことから、汎用性が高く、レイアウト変更にも容易に対応できるため、導入が容易と言えます。また、ケーブル断線等のトラブルも回避可能であり、データ収集環境の立ち上げも早期に確立出来ます。一方、無線通信であるため、電波状態によっては通信が不安定になります。さらに他のネットワーク機器と使用するチャンネルが重なった際には、動作が低下する等の欠点もあります。
一方、複数のセンサーを取りまとめて、信号を中継するためのゲートウェイモジュールが多く発売されています。IoTモジュールとかIoTユニットもしくはM2Mモジュールと称されています。ゲートウェイはいわゆるルーターのようなものです。 ゲートウェイはこうした機器とインサーネットを中継する役割を担う機器をいい、一般的なゲートウェイはLinux等のOSが搭載され、インターフェイスも私たちが良く知っているUSBやWi-Fi、Bluetoothが広く採用されています。一つのゲートウェイには、複数個のセンサーもしくはセンサーモジュールが接続され、得られた情報を、蓄積もしくは解析すべきネット上の機器へ転送するのが役割になります。通信を司るプロトコル仕様が重要です。IoTで主に利用されるプロトコルは、HTTP、Web Socket、MQTTなどがありま。 HTTPは、Webの標準的なプロトコルです。また非同期通信などでおなじみのWeb SocketもWebではよく使われるプロトコルです。
一方、半導体生産の現場では、SECSやGEMと言ったプロトコルが、世界共通で用いられています。SECSは、「SEMI Equipment Communications Standard」の略称で、またGEMは、「Generic Model For Communications and Control of Manufacturing Equipment」 の略称です。SECSもしくはGEMを用いれは、既に、IoT技術で制御されている半導体生産現場での財産を利用可能と成る分けです。生産装置には、装置一台毎に一台の通信用PCが準備され、SECSもしくはGEMに準拠した通信仕様に基づき、使用者側により決定された項目を、イントラネットに送り込む、もしくは、受け取る制御を実施します。生産装置からは、使用者が必要でない情報・信号も送り出されており、必要の無い信号は、このPCで切り捨てられています。また、生産装置から出力されない信号でも、必要に応じて、他の関連信号から補完的に、通信用PC内部で生成することも可能でしょう。
生産装置に装着されたセンサーから直接PCに蓄積される場合は、別として、IoTユニットや通信用PC経由でイントラネットに配信された信号は、それらの信号を効果的に利用するためには、得られた信号を蓄積する必要があります。信号を効果的に利用するためには、少なくとも、信号取得日時、取得時の処理製品の特定情報、処理条件が必要です。蓄積される信号には、これらの情報が付随した形で、登録されなければなりません。この考え方は、デジタルデータの一般的なデータベース構築と同じ考え方です。
データベースで、手軽に使えるのが、マイクロソフト「Access」でしょう。一方、大規模データを扱う場合、SQL Serverを使うのが一般的です。Accessは、ファイル共有型のデータベースシステムです。クライアントの要求はすべてクライアント側で処理され、その結果をファイル更新という形で保存します。一方、SQL Serverは、データベースシステムをネットワーク上に提供するという形でサービスを行っています。 クライアントの要求はすべてサーバー側で行われ、データベースの更新状況をトランザクションログとして保存しています。 サーバーのダウンなどの障害に対しても、一貫性のあるデータが保証されているわけです。SQL Serverのようなデータベースサーバでは、クライアントはサーバーに対して、必要な行を得るためのコマンドを指定し、サーバー側でクライアントの要求するコマンドを実行し、ネットワークを通してその結果を返すものです。
2.4 解析
信号データの取得、蓄積は、取得することが目的ではなく、それらのデータを利用して、『管理に使用する』もしくは『解析により改善効果を得る』ことが、真の目的でしょう。即ち、一番重要なことは、得られたデータの解析であると言えます。まず、何を目的に分析をするかということや解析対象の問題点について、正しい現状認識をする必要がります。数学や統計学の知識を有した者ならば、データさえあれば何らかの手法や複雑な処理計算によって、それなりの結果を導き出すことが出来ると思います。しかしながら、そもそもそのデータの意味やその背景にある状況などがわかっていなければ、意味のある結果を導き出すことは出来ません。企業の課題は、いかなる優秀な分析者より、その企業の問題点を明確に記述出来ているかが重要です。その上での解析アプローチとなるでしょう。
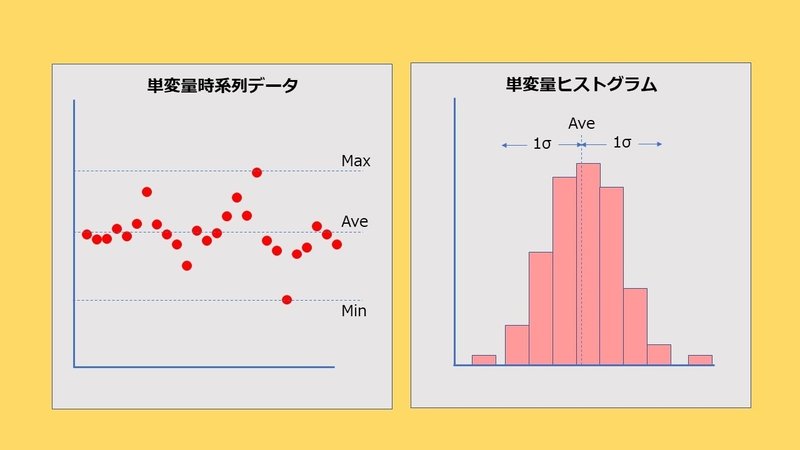
最初のアプローチとしては、単変量解析だと思います。データの持っている意味の全体像を掴むためのアプローチとなります。使い古された解析ですが、あえて、度数分布とヒストグラム、平均と標準偏差、正規分布と言った解析を実施することが、まず、必要であると思います。まず、フォーカスしたいところを特定するために、度数分布とヒストグラムを描いて、データの状況を把握することが必要でしょう。これと併せて、抽出された領域が、どのような状況になっているかを特定するために、注目領域の平均と標準偏差に着目します。対象のデータ分布が、正規分布をしていることが想定できる場合、平均値と標準偏差値がわかれば、対象データの存在するポテンシャルが理解され、問題とされるデータの出現を推定することが出来るでしょう。
次のアプローチとしては、相関関係解析となります。単変量の分析では、事象が追いきれない場合には、多変量の相関関係から、解析のアプローチが持たれます。まずは、理解の容易な2変量による相関関係解析が俎上に上るでしょう。相関関係とは、一方の値が変化すれば、他方の値も変化するという、2つの値の関連性を論じるものです。正の相関とは、2つのデータのうち一方が増加すると、もう一方も増加ものです。また、負の相関とは、2つのデータのうち一方が増加すると、もう一方が減少するという場合です。相関係数は-1から1までの値を取り、0に近いほど相関が弱く、絶対値が、1に近いほど相関が強くなります。この場合に、現象の予測が、精度よく可能になる訳である。具体的には、回帰分析を実施しることであり、「原因となる数値」と「結果となる数値」の関連性を、統計的手法を用いて特定します。原因となる数値(説明変数)の変化によって、結果となる数値(目的変数)が変化することを推測します。これによって仮説を立てることが可能になります。
次に複数の説明変数を利用する重回帰分析は、多変量解析のための分析手法のひとつです。多変量解析とは、複数の変数を持つデータの関連性を明らかにする統計手法のことで、重回帰分析以外にも、幾つかの分析手法があります。これら手法の中から、解析の目的や、扱う対象となるデータの種類によって、選定すべきでしょう。重回帰分析では、予測したい変数を目的変数と言います。これに対し、目的変数に影響を及ぼす変数を、説明変数と言います。重回帰分析では、目的変数、説明変数どちらも数量データが対象です。重回帰分析は、目的変数と説明変数の関係を関係式で表し、その関係式を重回帰式といいます。典型的には、y=a×x1+b×x2+・・・・・+n×xn+zと表現されます。この重回帰式の係数を回帰係数とされています。この式が得られると、任意の説明変数 x の値に対し、目的変数 y が予測できるということとなります。要するに目的変数と説明変数に、現象的に関係性が無ければ、この分析は成り立たず、説明変数の選び方が、分析の成否を大きく左右することは言うまでもありません。
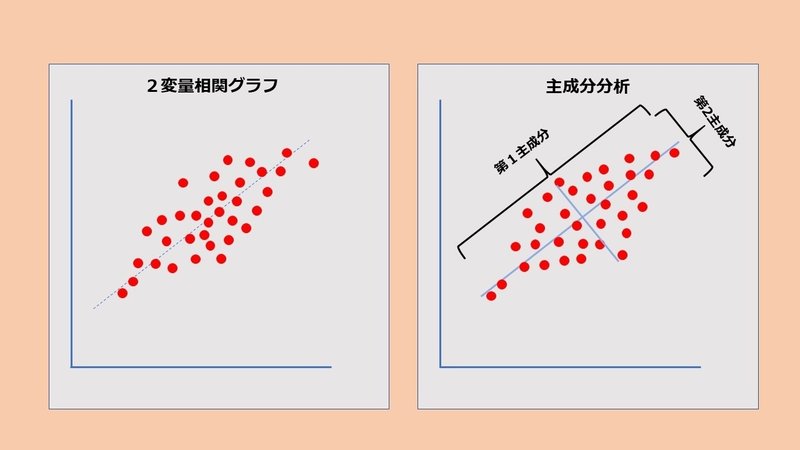
主成分分析は、重回帰分析から更に複雑な系の解析に用いられます。即ち、多くの種類のデータを要約するための強力なツールです。例えば3次元のデータ(x,y,z座標)を二次元のデータ(l,m座標)に要約(圧縮)する様なイメージを持って下さい。主成分を見つけるためには,分散が最大になるような軸を探します。最大となる分散を探すと言うことは軸から最も離れた確率変数を探すということになります。次に分散が大きくなる方向に軸を取り、これを第2主成分とします。第2主成分の軸は第1主成分の軸に直交します。主成分分析を行うと、各主成分に対応した固有値が求まります。この固有値は主成分の分散に対応しており、その主成分がどの程度元のデータの情報を保持しているかを表します。元の変量の分散が1に標準化されていれば、固有値は元の変量何個分の情報量を持つかを表します。ある主成分の固有値が表す情報が、データのすべての情報の中で、どの位の割合を占めるかを寄与率で表します。各主成分の寄与率を大きい順に足しあげていったもので、そこまでの主成分で、データの持っていた情報量がどのくらい説明されているかを示すことになります。
2.5 機械学習の導入
コンピュータの性能向上とこれに合わせて達成された低価格化に加え、インタネット通信速度の飛躍的な高速化により、機械学習の利用が、製造業の間にも飛躍的に浸透して来ています。機械学習に代表される人工知能も、私たち人間と同様に、学習しなければ役に立つことは出来ません。我々人間は、学校に通い、先生からの講義を受け、はたまた、何冊もの参考書を読んで知識を蓄積します。一方、プログラミングである人工知能は、人間が手打ちで整備したプログラミングとして与えるのか、データベースもしくは繰り返しによる機械学習により、プログラミング実行結果を向上させていくかと言う2通りの方法となります。既に使い古されているプログラミンで与える知識習得に関しては、ここでは触れません。
機械学習とは、コンピュータに存在するアルゴリズムが、データから反復的に学習し、そこに潜むパターンを見つけ出すことと言えるでしょう。そして学習した結果を用い、新たなデータを与えることにより、学習したパターンに従って、そのデータを判定したり、将来を予測することが出来るというものです。これまでは、人手によるプログラミングで実装していたアルゴリズムを、大量のデータから自動的に構築可能となるため、製造業の様に、繰り返し多量の作業の発生する現場での、利用が期待されています。
この様な機械学習は、学習の仕方で大別すると、教師あり学習と教師なし学習の2つに分けられます。但し、現状では、精度及び学習のスピードという点で、教師あり学習が、広く用いられています。そのほか、半教師あり学習、強化学習という手法も使われています。教師あり学習では、既知の望ましい出力が決まっている入力データを準備し、これを使って、事前学習を実行します。例えば、ある装置に故障のデータまたは正常といった入力データが準備できたとします。この機会学習アルゴリズムは、これらの入力データとそれらに対応する出力を受け取り、自信のアルゴリズムの出力と正しい出力を比較してエラーを検出します。これにより学習を進めて行きます。そして、自力でアルゴリズムに適切な改良を加えます。教師あり学習では、分類、回帰、予測、勾配ブースティングなどの選択された手法により、アルゴリズムが構成され、学習した結果である学習済みのアルゴリズムを結果として排出します。この学習済みアルゴリズムを用い、未知の入力データを判断もしくは予測することになります。
一方、教師なし学習は、実際現場で入手可能なデータを用い実行されます。この手法では、学習アルゴリズムに、事前に「正しい答え」が与えられません。アルゴリズム自身が、データの意味を突き止めて行くことになります。この手法の目的は、データを探索してその内部に何らかの構造を見つけ出すことです。現在、この手法に用いられるのは、自己組織化マップ(SOM)、近傍法マッピング、k平均法クラスタリング、特異値分解などがあります。これらのアルゴリズムは、テキストトピックのセグメンテーション、商品のレコメンド、データの外れ値の特定などにも利用されています。
十分に理解されているデータに理論分布を当てはめる統計モデルと同様に、機械学習も、データの構造を把握することですが、両者には大きな違いがあります。統計モデルの場合は、数理論的に実証済みのモデルをベースとして検討されるため、対象データがこの理論を適用するに十分な前提条件を満たしていることが必須となります。一方、機械学習では、データの構造に関する数理論の存在が前提では無く、コンピュータを使って、そのデータの特徴を探り、モデルを構築するものです。また、機械学習には、テスト・検証が必須であり、モデル作成に使用したデータとは別の新たなデータにより、作成されたモデルの確からしさを検証するアプローチが取られます。また、機械学習では、上述の特徴から、確固としたモデルを構築するまで、何度でもデータ処理を繰り返すことが出来る点で、汎用性に富んでいるとも言えます。即ち、教師あり機械学習は、不確実さがあっても証拠に基づいて、モデルを構築することが出来ます。学習のアルゴリズムは、すでにある一連の入力データとそれに対する出力結果を用いてモデルを学習し、新たなデータへの出力を機械的に予測出来る様にするものです。
教師あり学習の方法を大別すると、分類と回帰の二つに分類されます。分類手法では 、離散的な出力結果を予測します。有名な応用例が、電子メールのスパムメール検知です。分類手法は、データをカテゴリーに分類するための学習を行います。まず、入力データをタグ付け、カテゴリー化、または特定のグループやクラスに区分されている場合は、この分類手法が有効です。分類を実行するための一般的なアルゴリズムには、 サポートベクターマシン(SVM)、ブースティングおよびバギングされた決定木、k 最近傍法、単純ベイズ、判別分析、 ロジスティック回帰、およびニューラルネットワークが含まれます。
回帰手法では、温度の変化や電力需要の変動など連続的な応答を予測するものです。一般的な用途としては、電気負荷予測とアルゴリズム取引が含まれます。一定のレンジを有するデータの場合や、入力と出力の関係が比較的強く、教師データとして準備できる場合は、回帰手法を使用します。一般的な回帰アルゴリズムには、線形回帰、非線形回帰、ステップワイズ回帰、決定木、 ニューラルネットワーク、適応ニューロファジー学習などが含まれます。
2.6 自動判定導入
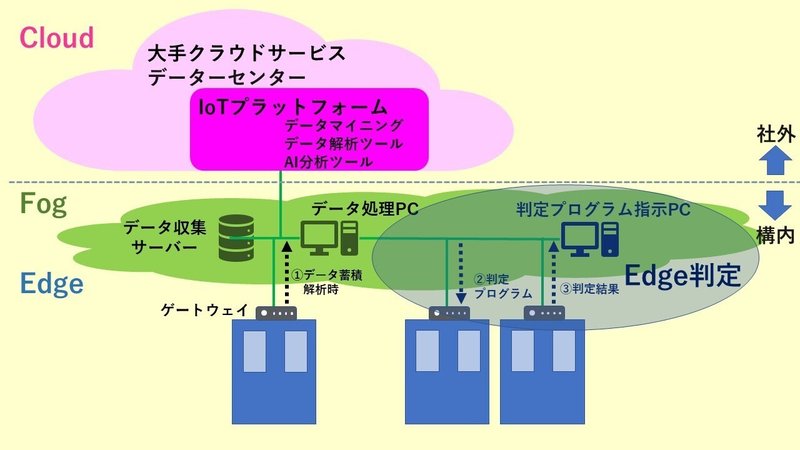
得られたデータを活かし効果を得るためには、これまで触れた単変量解析、多変量解析や機械学習で得られた結果を、実際の生産現場に持ち込み、判定結果を得られる仕組みが必要です。生産サイクルがゆっくりしている大型プラントでは、センサーデータをクラウドに上げ、クラウド上で分析した後に、その判定結果を、再び、製造現場に送り返し、生産装置を制御することが可能であると思われます。この様な場合でも、信号によっては、msecオーダーのセンシングが必要となり、相当大きなデータ量とリアルタイムの判定が必要な場合も想定されます。これに対し、一般消費財の生産現場では、相当大きなスループットが実現されており、即ち、分単位、秒単位での繰り返し動作が、生産装置では実行されており、遅くとも分単位での判定が求められて来ます。この様な判定を実現するために注目を集めているのが、エッジでのセンサーデータの取扱いとその場での判定実行です。
エッジでのセンサーデータの取得と判定を行うためには、データ記憶と判定プログラムの格納及びそれを用いた判定を実行出来るCPUを有しているゲートウェイモジュールが必要となります。もちろん、生産装置毎にパソコンを準備してしまえば、同じことが実現される訳ですが、これも費用対効果のバランスで判断されるべきです。この考えに基づき、Windowベースでプログラミング可能なゲートウェイモジュールも市場にリリースされており、最も一般的なC言語やLinuxでの制御も可能なモジュールも発売されています。これらのモジュールは、数万円~数十万円のものまで様々ですが、消費財生産現場では、やはり、数万円レベルのものが普及して行く様に考えられます。
ゲートウェイモジュールもしくはパソコンが準備されて、信号が取得可能となり、また、これに加えて、何らかの手法で判定プログラムが創出される環境を準備します。生産装置で、ただひたすら同じプロセス、作業を繰り返す場合には、これで判定が可能となります。一方、一般の生産現場では、複数の製品を同じ生産装置で生産することが、想定されます。この場合には、生産する品種もしくはプロセス、作業により、判定プログラムを変更する必要があり、厄介です。また、同じプロセスの繰り返しであっても、生産装置の摩耗劣化や使用部品の変動により、徐々に信号データが変化して行き、これにより同一の判定プログラムでは、検知が不可能になることも十分予想されます。これらの問題を解決するためには、判定プログラムを、生成したり、生成されたプログラムを格納やゲートウェイモジュールに送り込む仕組みが必要になります。もちろん、これらの作業を人が実行することは可能ですが、やはり、生産性を追求するためには、この場面でも、自働化が望まれます。即ち、必要な作業レシピにより、判定プログラムを自動で送り込むシステムの実現が必須となります。現在、残念なことにこの部分の汎用的なプラットフォームは無いことより、その業界や生産装置の仕様に従って、個別の開発が必要であると考えられます。
第1話
第3話
第4話
第5話

この記事が気に入ったらサポートをしてみませんか?