情報と理解

2019年に「自分はいったい何デザイナーなのだろうか?」という問いに答えるために、その当時読んでいた論文や書籍を参考にこの記事を書いた。
この記事の中でも400文字くらいで今回の記事のタイトルである「情報」という概念の定義にさらっと触れてみていた。その中ではざっくり情報とは、「我々になんらかの意味を伝えるもの」という定義を引用し、その構成要素として文字や数字などの記号を含むものであるという解釈をしていた [1]。
今年になって改めて「情報」という存在にとても興味が湧いてきている。なぜなら普段何気ない会話の中で
「情報が足りていないので判断ができない」
という発言をよく耳にすることがあるからだ。
これはよくよく考えてみると非常に不思議な現象だと個人的には感じている。現代社会は「情報社会」と呼ばれ、私たち人間が生み出すデータや情報は、IoTデバイス、スマートフォン、クラウドなどテクノロジーによって日に日にその情報量を増やし続けている [2]。つまり、情報は溢れかえっているはずなのである。にも関わらず「情報が足りていない」とはいったいどういうことなのか?
おそらくこの状況こそ、情報アーキテクチャ分野の父であるRichard Saul Wurmanが"Information Anxiety"という言葉で説明したかった現象なのではないだろうか [3]。実際に、私個人が遭遇する「情報が足りていない」という状況は、よく見渡してみると、プロジェクトを説明する分厚いドキュメント、クライアントとのミーティングで交わした会話の内容を記載した議事録、各種ログデータなど必要そうなものはすでに十分なほど提供されている場合が多い。そこに情報と呼べそうなものは存在している。にも関わらずそれを受け取った私たちは、うまく理解することができていない。情報があっても必ずしも理解が進むわけでないらしい。
今回は、情報と理解に焦点を当てながら考察を進め、情報を活用して自分が置かれている環境や文脈に対する理解をどのように深めていくことができるかという戦略について検討をしてみたい。
情報の本質
そもそも現代社会において有り余っているこの「情報」とは、私たち人間にとって一体どういう存在なのだろうか?単純に「我々になんらかの意味を与えるもの」という定義でもわかりやすくて構わないが、もう少しだけその輪郭を明らかにするような解釈を深掘りする必要があるように思える。
情報デザイナーであり、教師であるJoel Kanzは、”Designing Information — Human factors and common sense in information design”の中で「情報」という概念を、その真偽性に関するスペクトルに分類した定義で示している [4]。
1. Information (情報):
Definitely true
2. Uninformation (不情報):
Probably not untrue, probably not important, possibly interesting
3. Noninformation (非情報):
Possibly true, possibly not true, probably not important, possibly confusing
4. Misinformation (誤報):
Definitely not true
5. Disinformation (偽情報):
Deliberately not true
情報の「正しさ」を客観視に判断する唯一の指標を個人的には持ち合わせてはいない。また、「真実性」という概念については認識論的な立場を取れば当然変化してくるものではある。ただ、昨今問題となっている「フェイクニュース」に関しては、上記の4と5の特性が当てはまっているだろう。また、私たちの普段の生活の中で1に遭遇することはごくわずかであると思う。なぜなら、通常は2や3の状態で伝達されるからだ。そのような状態の「情報」を器用に解釈しながら意思決定を行っているために「情報が足りない」という状況が発生しているのではないかということを想像することができる。
同様なスペクトルという観点から「情報」の特性について説明しているのが、Seed Valut Ltdの取締役であり、California College of the Arts (CCA)のデザインMBAのプログラム創設者であるNathan Sedroffである。彼は、2000年に発表した"Information Interaction Design: a Unified Field Theory of Design"というタイトルの論文の中で、「理解のスペクトル(The Understanding Spectrum)」というモデルを提示している [5][6]。
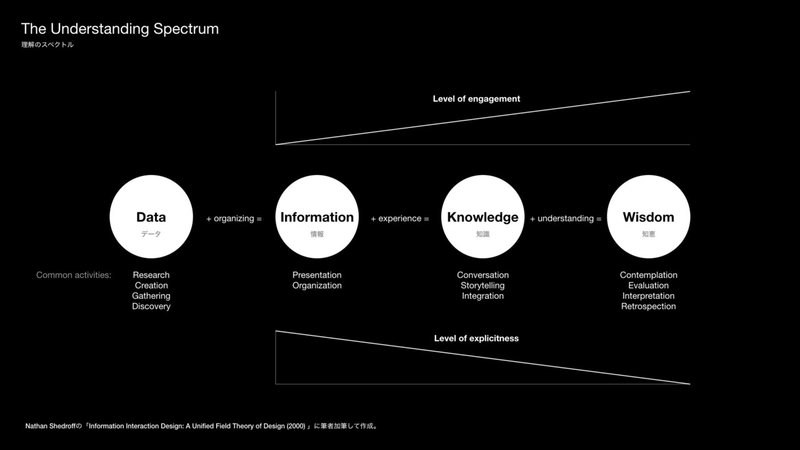
"Data is the product of research, creation, collection, and discovery. It is the raw material we find or create that we use to build our communications. "
「データ」は、研究・創作・収集・発見の産物であり、コミュニケーションを構築するための原材料である。
"Information is the first level at which it is appropriate to communicate with audiences. It represents the transmission of thoughtful messages that reveal the relationships and patterns (the context) among the data presented. Transforming data into information is accomplished by organizing them into a meaningful form, presenting them in appropriate ways, and communicating the context around them. "
データは「情報」になってはじめてユーザや聴衆に伝達するのにふさわしい形になる。データ間の関係やパターン(コンテキスト)を明らかにしたものがメッセージであり、考え抜かれたメッセージを形にしたものが「情報」である。データを整理して意味のある形にまとめ、適切な方法で提示し、それを包むコンテクストを伝えることで、データは「情報」に変わる。
"Knowledge is the pay-off of any experience. It is the understanding gained by building through experience, whether bad or good. Knowledge is communicated by building compelling interactions with others, or with systems, so that the patterns and meanings of the information can be assimilated. "
「知識」は、"体験"から得る報酬、体験(よい体験であれ悪い体験であれ)を通じて得る理解である。情報が提示されただけでは知識の伝達は起こらない。ほかの人やシステムと相互作用せざるを得ない関係性を構築し、情報のパターンと意味が同化されると、「知識」の伝達が生じる。
"Wisdom is the most vague and intimate form of understanding. It is much more abstract and philosophical than the other levels, and we know less about how to create or affect it. Wisdom is a kind of metaknowlege, a blending of all the processes and relationships understood through experiences."
「知恵」は、最も漠然とした、最も個人的な理解である。他のどのレベルよりも抽象的かつ哲学的であり、知恵の創造の仕方や内容にどのように影響を及ぼせるかについて、わかっていることは少ない。「知恵」は一種の"超知識"であり、体験から理解されたすべてのプロセスと関係の混合物である。
このモデルは、いくつかの点において興味深いと感じる。まず第1に「情報」の原材料は「データ」であると明らかにされている点である。そこら中に転がっている不完全で、意味がない「データ」をその関係性やコンテキストを考慮した形にすることではじめて「情報」へと変化する。わかりやすい例で考えれば、ある会議の中で発話された内容をすべて記録したメモはまだ「データ」であり、それを読む人を意識して要点を理解しやすいように組織化・構造化した議事録は「情報」であるということだろう。
第2に、「知識」は体験を通じて得る理解であるという点である。よく耳にするフレーズとして「本に書いてある内容は知識ではない」というものがある。これは半分正解だが、同時に半分不正解だと思う。本に書いてあるのは、Nathan Shedoffのモデルによれば「情報」である(もしかしたら「データ」の可能性もある)。つまり、確かに本に書いてあるのは「情報」であり、「知識」ではない。しかし、本を「読む」という体験をした人にとっては、その「情報」は実際にその人の「知識」へと変化したと捉えることができる。さらに言えば、その情報を本という形に具現化した著者にとってその内容は間違いなく知識でありさらには知恵でもある。したがって、先ほどのフレーズは、体験を通じた理解の有無によってその真偽が分かれることになる。この「体験を通じて得る理解」という考えこそ、この記事を書くきっかけになった疑問と深い関連があるように感じている。本質的に私たち人間はそこに情報が存在しているだけでは、それを知識へと昇華できないし、理解が進まないのかもしれない。
最後に、「理解のスペクトル」全体を通じて起こる変化についてである。「データ」→「情報」→「知識」→「知恵」とスペクトルの右へと進むにつれて、文字や絵といった外の世界において表現可能な形から個人の理解というコンテキスト内の見えない形へと変化していく。ここで示されている「知識」や「知恵」は、個人の中に存在するものであり、それらが獲得された体験の種類、頻度、練度、場所、時間といった変数によってそれらの在り方は変容すると考えることができる。「情報」という概念は、このモデルにおいてはスペクトルの1つとして表現された。一方で、それぞれの段階を一貫して存在するメッセージやパターンなどの本質と呼べるようなものがあるようにも感じている。
その本質についての解像度を上げるために、”Abyy the IA”で知られる情報アーキテクトのAbby Covertが、"How to Make Sense of Any Mess"を題材にした2017年のkeynoteスピーチの中で紹介している「情報」の説明を見てみたい [7]。
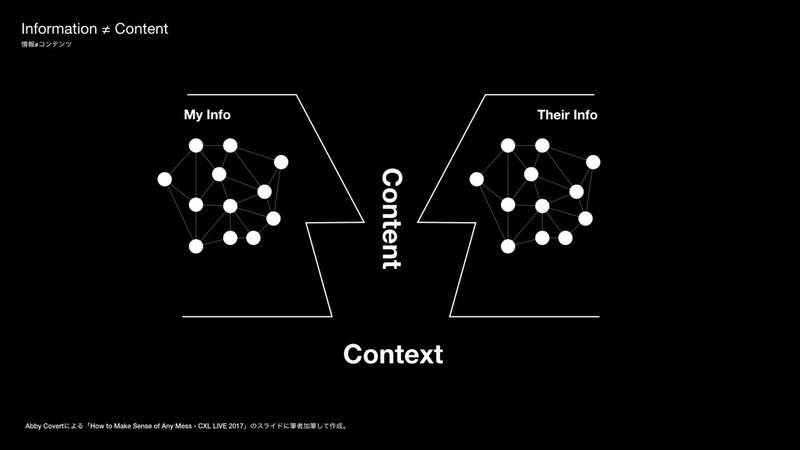
"...information is not the same as content and the most important thing to note about this is those people who make experiences we can't make information. Our users actually do that for us. Now what this also means is that truth really has no place here... so this idea that we can sort of put information into people's brains the way we'd like it to be just doesn't exist. That's a fallacy of what we do. So it's really important thing for us to understand that the content we provide mixed with the context that they're in and the data that they have access to from their past experiences is what results in their information."
情報は、コンテンツと同じではありません。そして、このことに関して最も大切なことは、体験を作っている人たちは、情報を作ることはできないということです。私たちのユーザが実際はそれを私たちのためにやってくれるのです。さて、これが意味することは、真実という概念は本当にここには場所がないということです。つまり、私たちの思い通りに人々の頭の中に情報を入れることができるというような考えは、本当は存在しないのです。それは、私たちの行いの誤りです。ですから、彼らがいるコンテキストと彼ら自身の過去の体験からアクセスできるデータが混合された私たちが提供するコンテンツこそが、彼らの情報につながるということを理解することが重要です。
ここで語られている内容の微妙なニュアンスの違いを捉えることは難しいが、彼女の説明における「コンテンツ」は、「理解のスペクトル」における「情報」と同じような意味で使われているように解釈することができる。そして、彼女が説明する「情報」は、「理解のスペクトル」における「知識」や「知恵」もしくは「体験を通じて得る理解」として読み取ることができると思っている。
また、彼女は実際にhowtomakesenseofanymess.comの中で、「情報」を次のように定義している [8]。
"Whatever is interpreted from a particular arrangement or sequence of things."
特定の配置または一連の事柄から解釈されたすべてのものやこと
このことからAbby Covertにとって「情報」とは、どちらかといえばコンテンツに触れた人が個人的な体験を通じて得る理解や解釈に重きを置いたものであるというように読み取ることができると思う。
一方で、同じ情報アーキテクチャに関する書籍で白くま本"の別名を持つLouis Rosenfeld、Peter Morville、Jorge Arangoが共著した「情報アーキテクチャ:見つけやすく理解しやすい情報設計」の中では、次のような説明がされている [9]。
データには事実と数字が関わります。リレーショナルデータベースは高度に構造化されており、特定の質問に対してそれに適合した特定の回答を作り出します。知識とは人の頭の中にある「もの」です。ナレッジマネージャーはその「もの」の共有を促進するためにツールやプロセス、動機を開発します。厄介なことに、情報はそれらのまんなかに存在します。情報システムでは「唯一」の正解などは存在しないのです。私たちはありとあらゆる形や大きさの情報に関係があるのです。またメタデータにも関係があります。
単純に読めば、この説明は「理解のスペクトル」と同様の着眼点で「情報」を捉えていると考えることができる。しかし一方で、「『唯一』の正解などは存在しない」といったAbby Covertの説明とも呼応するような一文もまた存在する。おそらくここには、「情報」のその本質を捉えようとするときに2つの側面があることを示唆しているのではないかと感じている。
情報に関する2つの概念的定義
上田修一と倉田敬子らが編著した「図書館情報学」では、情報に関する定義は大きく2つあるとされている。1つ目は、民俗学者の梅棹忠夫が1963年に発表した「情報産業論」の中で定義したものである [10]。
人間と人間のあいだで伝達される一切の記号系列
この定義は、先ほどまでの「情報の本質」のセクションにおいて考察してきた外部メディアを使ってコンテンツなどとして表現可能な存在としての情報を取り扱っているように読み取ることができる。アナログであろうが、デジタルであろうが情報の物理的な性質を示唆していると思う。加えて、その情報を取り扱う存在として少なくとも2人以上が参加していることが書かれている。つまり、情報にはその送り手がいて、受け取り手が存在するということである。
2つ目の定義は、情報科学者であるBertram C. Brookesが1977年に発表した"The Developing Cognitive Viewpoint in Information Science"の中で定義した次の基本方程式である [10]。
K[S] + ΔI = K[S +ΔS]
ここでは、K[S]は知識構造、ΔIは情報、ΔSは効果、そしてK[S + ΔS]は情報が既存の知識構造に組み込まれたことで新しく変化した知識構造を意味している。この情報が知識構造に変化を与えるという考え方は、Abby Covertの情報に対する定義と非常に近い。そして、この定義における最も重要な点は、情報であるΔIが、その観察者の知識構造に組み込まれた際には、その効果であるΔSとして表現されていることにあると考えている。なぜなら、これは情報という存在は完全な客観性を持ったものではなく、その観察者による主観的な解釈によってその効果が変化することを強調しているからである。つまり、Nathan Sedroffの「理解のスペクトル」で示されていた通り、情報が知識へと変化する、または、人が情報を理解する際には、それを実行する個人の体験とその知覚に左右されるということになる。
「情報が足りない」を捉え直す
さて、ここまで様々な情報の本質と私たち人間への関係について考察を進めてきた。ここで出発点に立ち戻ってみたいと思う。私自身が「情報」という概念について最近になってとても深掘りしてみたいと思うきっかけになったのは「情報が足りないので判断ができない」という状況からだった。情報社会と呼ばれ日々の莫大な量の情報を生み出しているこの世の中で、この状況が示唆するのは一体どういうものなのか?
おそらくここでいう「情報が足りない」とは、そこに存在しているデータや情報の量そのものが不足していることにのみ言及しているわけではないと思っている。Richard Saul Wurmanが"Information Anxiety"というフレーズで表現したように情報の量は、その内容に対する私たちの理解度の向上にあまり効率的に貢献しない。認知心理学者であるGerge A. Millerが1956年に発表した”The Magical Number Seven, Plus or Minus Two: Some Limtis on Our Capacity for Processing Information.”の中では、人間の短期記憶はおおよその場合、7つ程度のアイテムまたは情報チャンクしか同時に保持することはできないとされている [11]。つまり、私たちが受け取る情報の「量」を単純に増幅させるだけでは、対象となる情報への理解は深まらない。さらに極端な言い方をすれば、単なる情報量の増加は私たちの理解を促すのではなく、逆に妨げてしまう可能性すらある。
ということは、問題の本質は「情報量の不足」ではなく、「そこに存在する情報そのものを理解できていないこと」ということなのだろう。このような着眼点で最初の状況を観察し直すと、次のように分類することができると思う。

1. 情報は存在し、理解もしている
つまり、判断ができて、次の行動もできる
2. 情報が存在していないことを、理解している
つまり、まだ判断はできないが、次の行動はできる
3. 情報は存在するが、理解していない
つまり、判断ができないし、次の行動もできない
4. 情報が存在せず、理解もしていない
つまり、まず行動から(最初の情報収集から)
1が最も理想の状況であり、情報を活用した行動の目指すべき姿だと考える。2も実はそこまで悪い状況ではない。「あとどんな情報があれば、判断を下すことができるか」ということが分かっている状態なので、次に必要な情報探索行動が明確になっているからだ。4に関しては「まだ何もしていない」状況であり、一番最初のヒアリングや情報収集をするところから1ー2ー3のいずれかへと移行できるという意味で最悪からは一歩外れている。
私が違和感を感じた最初の状況は、まさに3の状況だと思う。「情報は存在するにもかかわらず、それを理解できない」というこの状況こそが個人的に最も興味がある問題であり、解決するための方針を考えたいと思った対象である。この3の状況に陥ってしまう原因はいくつかあると思う。例えば次のような原因を考えることができる。
1. そこにあるのは情報ではなくデータである
2. 情報の量が膨大である
3. 情報そのものが専門的知識や新たな概念を要求するものである
ここからはそれぞれの原因に対する戦略について考えてみたい。
1. そこにあるのは情報ではなくデータである
データは、Nathan Sedroffの「理解のスペクトル」で説明されたように情報を構成する要素であるが、情報そのものではない。また、私たちはこの原材料の状態であるデータのままでは、それが示唆するインサイトを適切に理解することができない。結果として、円滑なコミュニケーションに繋がらなかったり、必要な行動を実行することができないといった状況を生み出すことになる。このような状況において私たちがまずとるべき戦略は「整理する(Organization)」ということである。
具体的には、情報の適切な粒度レベルを調整してそれぞれの関係性を考慮する「構造化(Structuing)」、それらを観察者が置かれた環境や状況に合わせて区別可能で意味のあるカテゴリーへとグループ化する「組織化(Organizing)」、さらにそれらのナビゲーション構造要素をどのように呼ぶかを決める「ラベリング(Labeling)」といった活動を行う [9]。また、上記の活動はLATCH:Location - Alphabet - Time - Category - Hierarchyと呼ばれるRichard Saul Wurmanによって提唱された情報整理の原則によって実現することができる [12]。LATCHの項目は、1つだけ利用することも、複数を組み合わせて多重な整理を実行することもできる。加えて、ここで説明している「整理する」という戦略には「分類する(Classification)」という行為も含まれている。この「分類」には、既存で存在する区分や分類の枠組みの構成にしたがって対象を分けていく「仕分け(Classify)」と似た特性持っているもの同士を集めていく「クラスタリング(Clustering)」という活動に分けることができる [10]。
私たちはこのように、様々な整理の方法を活用しながらデータに私たち自身のコンテキストから読み取った意味を付与し、それが示唆することを理解する。つまり、「整理すること」はそのまま「理解すること」につながるのである。
2. 情報の量が膨大である
「整理する」とは言ったものの人間が処理できるデータや情報の量には限りがある。100行を超えるくらいのエクセルシートに記載されたデータならなんとか気合いを入れれば整理しきれる自信はあるが、1万行を超えるとどうだろうか?とてもじゃないがそんな作業やるをやる気も時間もないと感じるだろう。他にも長すぎて一度も読み終えた記憶のないサービスの「利用規約」や「プライバシーポリシー」なども同様の例として考えることができる。
このような状況において、私たちが理解を深めるためにとることができる戦略は大きく2つある。1つ目は、その膨大な情報を「理解する作業を誰かにサポートしてもらう」というものである。情報アーキテクトであるStephen P. AndersonとKarl Fastは、共著 "Figure It Out: Getting from Information to Understanding"の中でこの戦略における2つの異なるアプローチを先ほどの「利用規約」と「プライバシーポリシー」の例を使いながら説明している [13]。
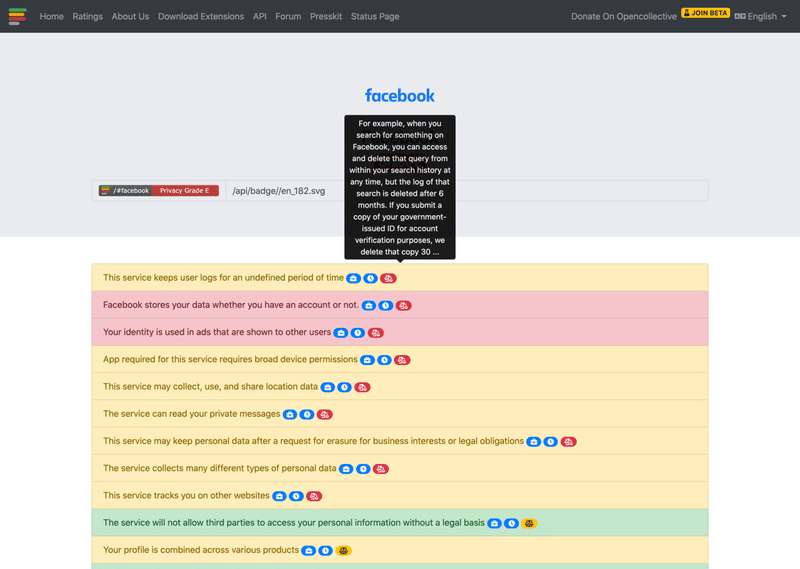
Terms of Service; Didn't ReadによるFacebookのプライバシーポリシー要約
1つ目のアプローチは、「誰かが膨大な情報を読み込み、利用者のために要約する」というもので、ここでは"Terms of Service; Didn't Read"というプロジェクトが紹介されていた。これは、2012年から始まったインターネットのサイトおよびサービスの利用規約とプライバシーポリシーを分析・評価することを目的としたコミュニティプロジェクトである [14]。実際にこのウェブサイトにアクセスするとFacebookやAmazonなど私たちが普段利用しているサービスの利用規約やプライバシーポリシーが要約され、しかもグレードをつけた評価を確認することができる(英語のみ)。
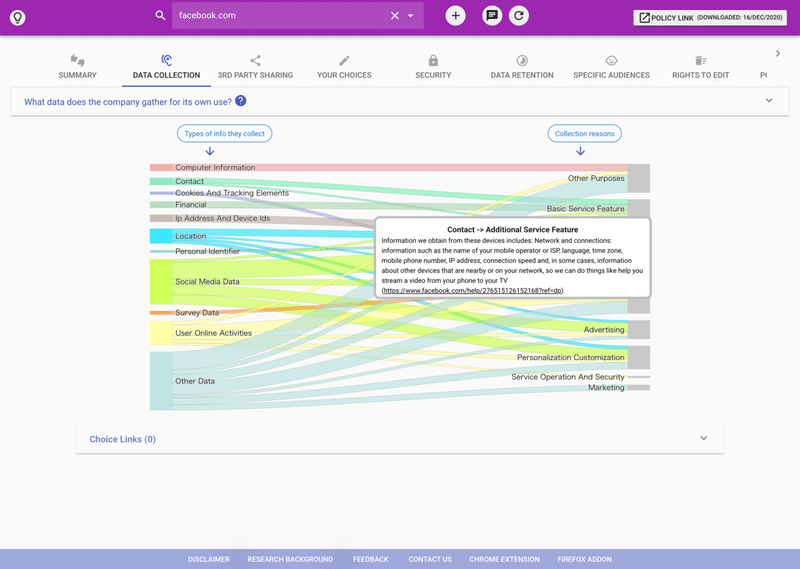
PolisisによるFacebookのプライバシーポリシー記載情報の明確化
もう1つのアプローチは、「利用者が理解しやすい形に情報を変換する」というものである。"Polisis"は、"Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning"という論文を元にしたサービスで、論文タイトルにもあるように深層学習のアルゴリズムを利用してプライバシーポリシーを整理している [15]。
1つ目と2つ目のアプローチが対照的なのは、後者ではプライバシーポリシーの内容が一切削ぎ落とされていないという点にある。Terms of Service; Didn't Readのアプローチでは、利用者はその分析、評価、要約を実施した作業者に理解に必要な工程・労力を完全に委託しているため、作業過程の中で削ぎ落とされた情報については、その人を信用するほかない。一方で、Polisisのアプローチでは、複雑で膨大な情報をAIを利用した深層学習に加えて、「視覚化(Visualization)」というテクニックを用いることでありのまま理解しやすい形に変換している。加えて、利用者はPolisisが提供しているインタラクティブなウェブサービスを通じて、自らの理解を深めることもできる [13]。
私個人も含めたデザイナーはしばしば「要約する」というアプローチを「ユーザのため」と呼んで肩代わりし過ぎてしまっているのではないかと感じている。このこと自体は1つの立派なアプローチであり、必ずしも悪いと断定されるようなことではない。しかし、日常の中で情報探索活動を行い、自らを取り巻く環境や情報と触れながら「意味付与(Sense-making)」 [10]を無意識レベルで行っている利用者に対して、本当の意味で理解を手助けしエンパワーするためには、Polisisのようなアプローチをとる必要があるのではないかと思っている。そして、これはこのセクションで紹介する2つ目の戦略とも関係性している。
2つ目の戦略とは、膨大な情報を「感じとれるようにすること」である。これは多摩美術大学の永原康史教授のオンライン講座を受講した際に発見した戦略であり、平たく言い換えると「データビジュアライゼーション(Data Visualization)」のことである [16]。先ほど紹介したPolisisはこれと近い方法を採用していた。
これまでも見てきたように、私たち人間は膨大なデータを1つずつ読み込み、それらを短時間で正確に理解することに適した脳を持ち合わせていない。それを得意とするのはコンピュータである。一方で、そういったデータは、視覚化することで単純な形や線を使ったグラフに何百万ものデータポイントを凝縮して表示することができる。わかりやすい例で言えば、株やFXなどの金融サービスで使われるグラフなどがあると思う。そして、このような形で表現することで、私たちは文字通りそこに凝縮されたデータを意味のある情報として感じることができるようになる。しかも、そこで扱われているデータは、その内容を一切削ぎ落とすことなく、別の形で忠実に表現される。
ここで紹介しているのは、情報デザインやデータビジュアライゼーション界隈で「最も優れたデータビジュアライゼーションの例」として取り上げられるHans Poslingによる "The best stats you've ever seen"というタイトルのTed Talkである [17]。彼のプレゼンのスタイルからもわかるように、膨大なデータは「感じること」で理解への変化するのである。
3. 情報そのものが専門的知識や新たな概念を要求するものである
私たちが日常生活の中で触れるデータや情報の中には、より専門的知識を要求するものや、これまでには見たことも聞いたこともない全く新しい概念が含まれていることがよく含まれている。このような種類の情報は、主に受け取る側が持つ既存の知識構造で理解可能な範疇を大きく超えている場合に起こる。言い換えると、既に知っていることと新しく提示された情報との間のギャップが大きいような状態において発生する問題である。
この問題に対応するための戦略を単純に羅列することは簡単だが、それらのテクニックのベースとなっている人間の認知に関する特性について見てみることでより本質的なアプローチをとることができると感じている。
人間の脳は、史上最高峰のパターンマッチングの機械であり、五感を通じて新たにインプットされた情報と既存の知識構造 —— 記憶の中に存在する体験や情報 —— と照らし合わせながらマッチングすることで新しい知識や概念を獲得していると言われている。Stephen P. AndersonとKarl Fastは、人間の理解が起こる過程を次のように説明している [13]。
"We all — whether we're consciously aware of it or not — make sense of any new information by likening it to some other familiar concept. To understand, we link the unknown to what is already known.
・・・
Association among concepts is thinking."
私たちは皆——意識的に気がついているかどうかにかかわらず——どんな新しい情報も他の慣れ親しんだ概念とそれをなぞらえることで理解している。理解するために、私たちは未知を既知とつなぐのです。
<中略>
概念間の連想こそが思考なのです。
この説明におけるポイントは2つあると思う。1つ目は、新しい情報と個人が脳内にもつ既知の概念や体験との関わりである。これは、情報の定義について考察した際に紹介したBertram C. Brookesが提唱した情報に関する方程式の知識構造の部分と深い関わりを持っている。インプットされる情報が同じだとしても、それを解釈する人が持ち合わせている知識構造は異なるためそこで起こる変化には差が生まれるということになる。そして2つ目は、連想という思考における重要な機能についてである。連想とは、Wikipediaによれば、「人間の心ないし精神の働きのうち、見聞きするなど五感から得た情報や観念から、他の物事や概念を思い浮かべることである。」とされている [18]。言い換えれば、ある任意の概念を他のものとつなげている(リンク)状態を指している。
話は少し脱線してしまうが、このような人間の思考の本質の特に「リンクする」という部分は、Vannevar Bushによる「人の思考のように(As we may think(1945)」の論文にて提唱された人の記憶・思考能力に拡張性を与える「メメックス」から始まり、GUI、LAN技術、ワードプロセッサ、ダイナブック、ハイパーテキスト、デモ、ハイパーカード、WWW、インターネットへと繋がる壮大な歴史的・技術的発展の基礎へとつながっていることもとても興味深い事実である [10]。
田浦俊春らによる「デザインにおける創造的思考の構成的研究の試みー概念生成プロセスの構成的シミュレーションー」の論文の中では、実際の観測が困難な人間の概念生成プロセスを、それとは異なる機構における働きの特性から観察し推測する方法である「構成的シミュレーション」を用いて実験している[19]。
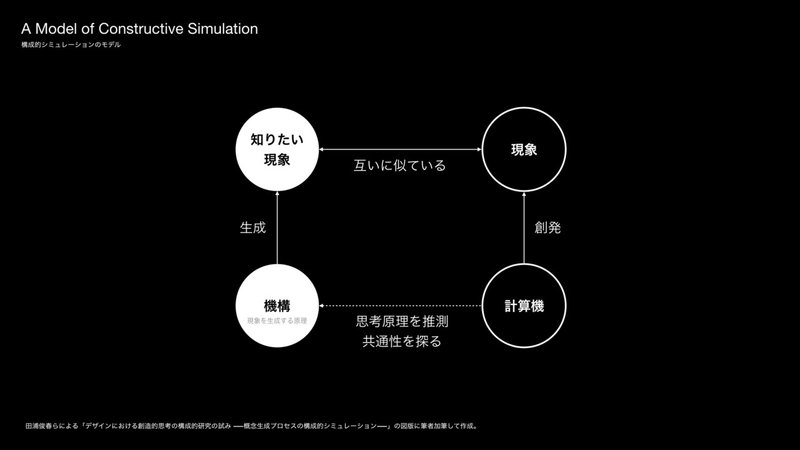
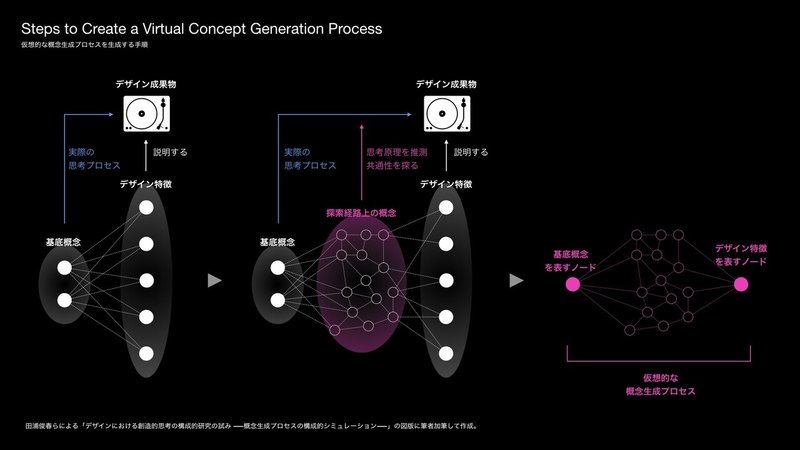
実験の詳細には詳しく触れないが、ここでは概念生成の始点(発想の始まりの単語)と終点(最終的な成果物)の間にある経路が、どのような単語間における意味的関係(ネットワーク)を成しているかを仮想的に表現することでその特性の分析を試みている[19]。つまり、先程紹介していた概念同士にリンクはどのように起こっているかを見ようとしているのである。
この論文は、

その仮想的な概念生成プロセスが実際の概念生成プロセスと相似であったことは、創造的なデザイン成果物を導く思考原理が、基本的には、概念の逐次的な連鎖(連想プロセス)であることを示唆している。
<中略>
本シミュレーションの結果より、「デザインにおける創造的な思考プロセスが非連続的に見えるのは、本来は連続的であるプロセスが、部分的に潜在化してしまうためである」という仮説が導かれる。
と観察の結果から得られた発見を元にした仮説に対する考察で締め括られている [19]。
この研究は「創造的な概念がどのような思考プロセスを経て形作られているのか?」という問いを明らかにしようと試みている。少し視点を変えて見れば、概念生成プロセスの構造的特性に関する理解は、この記事で現在取り扱っている「3. 情報そのものが専門的知識や新たな概念を要求するものである」という問題の原因に対する戦略としても有効であると捉えることができる。つまり、情報が専門的であったり、既知の概念から相当かけ離れた全く新しいものである場合、私たちはまずそれらに関係する諸概念を分解してそれぞれの構成要素として理解を進める。そして、さらにそれらが持つ意味ネットワークについて理解を進めることで、対象となる情報そのものについて理解を深めることができるということだ。
私は仕事でモデル(ダイアグラム)という手法をよく利用する。複雑に絡み合った要素を出来るだけ忠実な形で理解し、表現することで、問題に対する効果的なアプローチを検討するためだ。モデルを丁寧に検討する場合は、私個人でその制作を進める。そうして出来上がったものは、私個人は理解できる状態にあるが、初見の人からすると複雑なスパゲティのようなモデルがそこに現れることになる。私以外のメンバーに対して、モデルが表現している概念の理解を促進するために利用するアプローチが「積み上げ」式の説明である。全体像のモデルを複数枚に分解し、構成要素同士の関係性をストーリーとして積み上げながら、全体像への理解を手助けするのである。そうすることで、私以外のメンバーもそれぞれの視点や解釈をそのモデルに持ち込み建設的な対話をすることができるようになる。
もう1つのアプローチとして、いわゆる「メタファー」を利用するというものがある。これは任意の概念が持つ意味ネットワークを、その構造特性が類似している別の概念を比喩的に足場かけとすることで、それが持つ本質的意味と可能性を瞬時に理解することができるというものである。例えば、私が勤めている株式会社ゆめみは、他社と比較した時に全く新しい組織構造とプロセスを取り入れているため、入社してまもないメンバーは、よくゆめみの組織構造を「細胞」や「生命体」のメタファーを利用して理解しようと試みているのをしばしば見聞きする。
他にもわかりやすい例を挙げると、スティーブ・ジョブズが2007年に最初のiPhoneをリリースした際のプレゼンテーションがある[20]。このプレゼンテーションの中では、先に紹介した積み上げとこのメタファーを上手く利用されており、iPhoneという全く新しいプロダクトカテゴリーを人々に一気に理解させることに役立っている。
iPod(ミュージックプレイヤー)
+
Phone(携帯電話)
+
Internet (インターネット)
=
iPhone(3つが1つになったデバイス)
ただ、メタファーにおいて気をつけなければならないのは、それによって得られる理解は、本来の対象概念とは別の足場かけとして利用した概念の意味ネットワークを通して得たものであり、その理解は正確なものではないということだ。例えば、コンピュータ上に存在する様々な形式の電子ファイルやデータを整理するために、「フォルダ」という概念が物理的な紙のフォルダをメタファーとして導入された。これは人々にGUIを通じて、フォルダにファイルを整理できることを理解させることに成功した。一方で、フォルダのメタファーは、物理的制約に則した階層構造のみに人々の理解を縛ってしまうことになった。GmailやDropboxは、ソフトウェアだからこそ可能なファイル整理の新しい方法を機能として提供している。しかし、それを正しく理解して効果的に利用できているユーザーは多くはない [21]。
このように専門的知識を求められる概念や全く新しい概念に対する理解の戦略は、人間の思考プロセスを理解し、それに対応するアプローチを採用して時間をかけて試行錯誤しながら正確な理解に至るという割と地道なプロセスである。
終わりに
今回「情報と理解」というタイトルで記事を書き進めた。調査を進めながら、時間をおいてその時々の関心ごとと絡めながら書いたので思ったよりも時間がかかり、合わせて文字量も膨大になってしまった。
今回の学びを実践で活かせるほどに理解できたかというとまだ不安ではあるが、情報とそれが私たちにもたらす変化、情報の概念的定義、体験を通じて身につける知識、情報を活用する上で避けなければならない状況、情報に対する理解を促すための戦略、概念生成におけるプロセスなど幅広い知識を得ることができた。
今後は、日々の生活や業務の中で「情報をいかに生み出し、体験し、適切に理解し、活用する」ということを意識していきたい。また、ユーザー調査やUX調査から抽出されるインサイトやステークホルダーとの対話から得られるフィールドバックなどをより適切にアウトプットや形に落とし込む実践をしていきたいと思う。
そして、実践の中で見えてきた知恵は、なんらかの体験としてインストールできる情報へと整理したい。
---
記事内に設定している資料の画像が粗いので、SpeakerDeckに載せています。
---
参考・引用文献
[1]
本村章.
"何のデザイナーか?(2019)"
https://note.com/akiramotomura/n/n7e815b50778d
[2]
Hugh Dubberly.
"'Datafication' — the rise of big data and the application of AI to everything (2017)."
http://presentations.dubberly.com/datafication.pdf
[3]
Los Angeles Times
"INFORMATION OVERLOAD: What to Do When Anxiety Cripples You (1989)."
https://www.latimes.com/archives/la-xpm-1989-01-22-tm-1044-story.html
[4]
Joel Katz.
Designing Information: Human Factors and Common Sense in Information Design (2012).
https://www.amazon.co.jp/Designing-Information-Factors-Common-Design/dp/111834197X
[5]
Nathan Sedroff.
"Information Interaction Design: a Unified Field Theory of Design (2000)."
Robert Jacobson.
Information Design (2000).
https://mitpress.mit.edu/books/information-design
[6]
ロバート・ヤコブソン(編集), 篠原稔和(翻訳), & 食野雅子(翻訳).
情報デザイン原論:「ものごと」を形にするテンプレート(情報デザインシリーズ)(2004).
https://amzn.to/3bGjMw2
[7]
Abby Covert.
"How to Make Sense of Any Mess (2017)."
https://www.youtube.com/watch?v=s6lXWgnTmRE
[8]
Abby Covert.
HOW TO MAKE SENSE OF ANY MESS (Website)
http://www.howtomakesenseofanymess.com/
[9]
Louis Rosenfeld(著), Peter Morville(著), Jorge Arango(著), 篠原稔和(翻訳), & 岡真由美(翻訳).
情報アーキテクチャ 第4版—見つけやすく理解しやすい情報設計(2016).
https://amzn.to/3fsed5D
[10]
上田修一(著)& 倉田敬子(著).
図書館情報学 第二版(2017)
https://amzn.to/3yiL1qt
[11]
George A. Miller.
"The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information (1956)."
http://www2.psych.utoronto.ca/users/peterson/psy430s2001/Miller%20GA%20Magical%20Seven%20Psych%20Review%201955.pdf
[12]
Richard Saul Wurman.
Information Anxiety (1989).
https://amzn.to/3f11xDL
[13]
Stephen P. Anderson & Karl Fast.
Figure it Out: Getting from Information to Understanding (2020).
https://amzn.to/2QAu2yO
[14]
Terms of Service; Didn't Read (Website).
https://tosdr.org/
[15]
Polisis (Website).
https://pribot.org/
[16]
永原康史.
"インフォグラフィックス概論 (2020)"の講義メモより
[17]
Hans Rosling.
"The best stats you've ever seen.
https://www.ted.com/playlists/474/the_best_hans_rosling_talks_yo
[18]
Wikipedia
「連想」に関するページ(Website)
https://www.google.com/search?q=%E9%80%A3%E6%83%B3&oq=%E9%80%A3%E6%83%B3%E3%80%80&aqs=chrome..69i57j0j69i59j0l4j69i60.5433j0j7&sourceid=chrome&ie=UTF-8
[19]
田浦 俊春, 山本 英子, Yusof Nor Fasiha Mohd, 伍賀 正典, 永井 由佳里, 中島 秀之.
"デザインにおける創造的思考の構成的研究の試み―概念生成プロセスの構成的シミュレーション―(2011)"
https://www.jstage.jst.go.jp/article/jcss/18/2/18_2_329/_article/-char/ja/
[20]
Steve Jobs.
"Introducing The Phone At MacWorld 2007"
https://www.youtube.com/watch?v=x7qPAY9JqE4&ab_channel=superapple4ever
[21]
Daniel Jackson.
Design by Concept: A New Way to Think about Software.
https://www.goodreads.com/book/show/45029338-design-by-concept
基本的に今後も記事は無料で公開していきます。今後もデザインに関する様々な書籍やその他の参考文献を購入したいと考えておりますので、もしもご支援いただける方がいらっしゃいましたら有り難く思います🙋♂️