
16章 BERT:映画レビュー感情分析が感動のフィナーレへ!

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第16章 Transformer-Attentionメカニズムによる自然言語処理の改善」の「16.5 PyTorchでのBERTモデルのファインチューニング」で遂に踏み出したGoogle ColabのGPU使用によるBERTのファインチューニングを紹介します。
16章のダイジェスト
16章では、Attentionメカニズムに着目して、自然言語処理の領域で現在主流のTransformerアーキテクチャにチャレンジします。
まずは、AttentionメカニズムとSelf-Attentionメカニズムについて、理論的な基礎を図解などで学びます。
続いて、次の2つのケースについて、PyTorch等で実装します。
・GPT-2で簡単な英語文章の自動生成
・BERTモデルのファインチューニング(IMDb映画レビューデータセットによる感情分析)
なお、この章で扱う文章データは「英語」です。日本語を取り扱う際の処理、たとえば形態素解析などは取り扱っていません。
GPU非搭載コンピュータの限界
1. ミッション
今回のミッションは、BERT事前訓練モデルを感動分析のためにファインチューニングすることです。
BERTって?
BERTは2018年にGoogleの研究チームによって開発された自然言語処理のモデルです。分類タスクに強みがあると言われています。
ファインチューニングって?
BERTはすでに事前訓練済み(学習済み)の言語モデルです。
このモデルに追加的な訓練を行ってカスタマイズすることをファインチューニングと呼んでいます。
基本型にタスクの特徴を付け足すような感じです。
実際には、通常の訓練と同じような処理を行います。
感動分析って?
過去に2回登場している、おなじみの「IMDb映画レビューデータセット」を学習して、レビュー文章が「肯定的か否定的か」を予測する二値分類タスクです。
IMDbは映画等の総合サイトです。機械学習の領域では、IMDbの映画レビュー文章とその評価分類(肯定的/否定的)を活用しています。
IMDbの映画レビューデータによる感情分析については過去の記事にさまざま書いていますので、ぜひお読みください!
2. ファインチューニング処理
処理の詳細
Hugging Faceが開発したオープンソースのtransformersライブラリから、DistilBERTモデルを利用します。
・モデル:DistilBertForSequenceClassification.from_pretraind
・トークナイザ:DistilBertTokenizerFast
ファインチューニングに利用するデータセットは次のようになりました。
・訓練データ:35000個
・検証データ:5000個
・テストデータ:10000個
バッチサイズ16、エポック数3で実行します。
なお、テキストの実行例では、62.15分かかっています。
GPU非搭載パソコンの処理時間
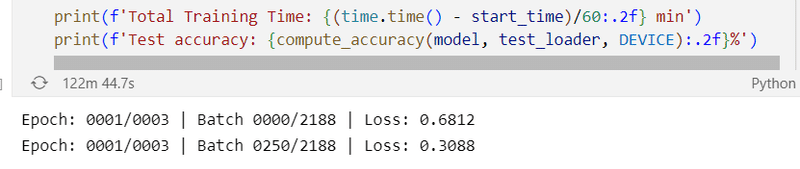
最初のエポックの1/8の段階で122分かかっています。
成り行きでは48時間かかる見込み。。。
「もう無理です」とパソコンが悲しげに告白しました(空耳)
Now the time has come…
Google ColabのGPUに頼るときがきました。
Google Colab、始動
1. Google Colabのファインチューニング処理
では、Google Colabで感動分析(感動分類)の訓練を行いましょう!
「所要時間」は各処理に実際にかかった時間です。参考にどうぞ。
①Googleドライブと接続
from google.colab import drive
drive.mount('/content/drive')②Googleドライブの作業フォルダに移動
cd /content/drive/MyDrive/pmlp/ch16_bert # MyDriveより後ろは各自環境のフォルダ③transformerのインストール:所要時間 56秒
# transformersのインストール
!pip install transformers④必要パッケージのインポート:所要時間 7秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :必要パッケージのインポート
import gzip
import shutil
import time
import pandas as pd
import requests
import torch
import torch.nn.functional as F
import torchtext
import transformers
from transformers import DistilBertTokenizerFast
from transformers import DistilBertForSequenceClassification⑤初期値の設定:所要時間 1秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :初期値の設定
torch.backends.cudnn.deterministic = True
RANDOM_SEED = 123
torch.manual_seed(RANDOM_SEED)
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
NUM_EPOCHS = 3⑥IMDb映画レビューデータセット取得:所要時間 5秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル:IMDb映画レビューデータセット取得
url = ("https://github.com/rasbt/machine-learning-book/raw/main/ch08/"
"movie_data.csv.gz")
filename = url.split("/")[-1]
with open(filename, "wb") as f:
r = requests.get(url)
f.write(r.content)
with gzip.open('movie_data.csv.gz', 'rb') as f_in:
with open('movie_data.csv', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)⑦訓練・検証・テストデータセット分割:所要時間 0秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :訓練・検証・テストデータセット分割
train_texts = df.iloc[:35000]['review'].values
train_labels = df.iloc[:35000]['sentiment'].values
valid_texts = df.iloc[35000:40000]['review'].values
valid_labels = df.iloc[35000:40000]['sentiment'].values
test_texts = df.iloc[40000:]['review'].values
test_labels = df.iloc[40000:]['sentiment'].values⑧単語トークンに変換:所要時間 51秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :単語トークンに変換
tokenizer = DistilBertTokenizerFast.from_pretrained('distilbert-base-uncased')
train_encodings = tokenizer(list(train_texts), truncation=True, padding=True)
valid_encodings = tokenizer(list(valid_texts), truncation=True, padding=True)
test_encodings = tokenizer(list(test_texts), truncation=True, padding=True)⑨IMDbデータセットクラスの定義:所要時間 0秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :IMDbデータセットクラスの定義
class IMDbDataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx])
for key, val in self.encodings.items()}
item['labels'] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.labels)⑩データローダーの作成:所要時間 0秒
※テキストのコードを一部改変しました。
# 感情分析 BERTモデル :データローダーの作成
batch_size = 16
train_dataset = IMDbDataset(train_encodings, train_labels)
valid_dataset = IMDbDataset(valid_encodings, valid_labels)
test_dataset = IMDbDataset(test_encodings, test_labels)
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset,
batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(test_dataset,
batch_size, shuffle=False)⑪DistilBERTモデルの読み込み:所要時間 14秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :DistilBERTモデルの読み込み
# DistilBERTモデルのダウンロードの実施を含む
model = DistilBertForSequenceClassification.from_pretrained(
'distilbert-base-uncased')
model.to(DEVICE)
model.train()
optim = torch.optim.Adam(model.parameters(), lr=5e-5)⑫分類正解率計算関数の定義:所要時間 0秒
※テキストのコードを引用しました。
# 感情分析 BERTモデル :分類正解率計算関数の定義
def compute_accuracy(model, data_loader, device):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for batch_idx, batch in enumerate(data_loader):
# データの前処理
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs['logits']
predicted_labels = torch.argmax(logits, 1)
num_examples += labels.size(0)
correct_pred += (predicted_labels == labels).sum()
return correct_pred.float() / num_examples * 100⑬訓練(ファインチューニング):所要時間 121分
※テキストのコードを引用しました。
# 感情分析 BERTモデル :訓練(ファインチューニング)
start_time = time.time()
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, batch in enumerate(train_loader):
# データの前処理
input_ids = batch['input_ids'].to(DEVICE)
attention_mask = batch['attention_mask'].to(DEVICE)
labels = batch['labels'].to(DEVICE)
# フォワードパス
outputs = model(input_ids, attention_mask=attention_mask,
labels=labels)
loss, logits = outputs['loss'], outputs['logits']
# バックワードパス
optim.zero_grad()
loss.backward()
optim.step()
# ロギング
if not batch_idx % 250:
print(f'Epoch: {epoch+1:04d}/{NUM_EPOCHS:04d} | '
f'Batch {batch_idx:04d}/{len(train_loader):04d} | '
f'Loss: {loss:.4f}')
model.eval()
with torch.set_grad_enabled(False):
print(f'Training accuracy: '
f'{compute_accuracy(model, train_loader, DEVICE):.2f}%'
f'\nValid accuracy: '
f'{compute_accuracy(model, valid_loader, DEVICE):.2f}%')
print(f'Time elapsed: {(time.time() - start_time)/60:.2f} min')
print(f'Total Training Time: {(time.time() - start_time)/60:.2f} min')
print(f'Test accuracy: {compute_accuracy(model, test_loader, DEVICE):.2f}%')GPUを利用したファインチューニングに約2時間かかりました。
テキストの実行例の約2倍の時間です。
なお、平日19時ごろに処理を実行しています。
【注意】
Google Colabの90分ルールに抵触してセッションが切断され、ファインチューニングの途中で処理が強制中断される可能性があります。
こまめに画面に触る、自動で画面を更新するツールを導入するなどの対策が必要です。
ファインチューニングの性能評価
次の図がファインチューニングによる性能値を示しています。

最終的な正解率は、訓練データで99.4%、検証データで92.2%、テストデータで92.9%です。
かなり高い正解率になったのではないでしょうか。
なお、テキストの実行例では、訓練データで99.1%、検証データで91.8%、テストデータで92.5%です。
テキストよりも少し数値が高い結果になりました。
2. チューニングモデルで感情分類を行ってみる
じつは、テキストはファインチューニング処理までを取り扱っており、育てたモデルで予測を実行するコードがありませんでした。
時間を掛けて育んだモデルで映画レビューの感情分析をしない手はありません!
文章を与えて、その文章が肯定的か否定的かを予測する分類タスクを実行しましょう!
transformersライブラリのBERTモデルで二値分類タスクを実行するコードについては、次のサイトを参考にしました。
ありがとうございました!
まず、レビュー文章をインプットして予測を行い、ポジティブかネガティブかをアウトプットする関数を定義します。
pred(text)で呼び出し、positive/negativeが返り値です。
# 感情分析 BERTモデル :感情分析推論関数(pos/neg)
import numpy as np
def pred(text):
label_dic ={0:'negative', 1:'positive'}
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(
inputs["input_ids"].to(DEVICE),
inputs["attention_mask"].to(DEVICE),
)
pred = int(np.argmax(outputs.logits.to('cpu').detach().numpy().copy(), axis=1))
return label_dic[pred]では、映画レビュー文章っぽい英文を使って予測してもらいましょう。
text = のところに映画レビュー文章を記載します。
# レビュー文章
text = "This movie is amazing. I have never seen it. I moved that story."
print("'",text, "'\nThis review is ", pred(text), ".")
出力イメージ
' This movie is amazing. I have never seen it. I moved that story. '
This review is positive .肯定的と判定したようです。
物語に感動した、といった部分に反応したようです。
では、次にいきましょう。
# レビュー文章
text = "That movie was a little scary."
print("'",text, "'\nThis review is ", pred(text), ".")
出力イメージ
' That movie was a little scary. '
This review is negative .否定的と判定されました。
「少し怖い」だけでは判断材料が少ないのかもしれません。
文章をいじってみましょう。
# レビュー文章
text = "That movie was a little scary but was very interesting."
print("'",text, "'\nThis review is ", pred(text), ".")
出力イメージ
' That movie was a little scary but was very interesting. '
This review is positive .「でも面白かった」を付け足すと肯定的へと予測が変わりました。
最後に、『神秘の島』を学習して自動生成した文章を与えてみましょう。
この記事に詳細を書いています。ぜひご覧ください!
# レビュー文章
text = "They were the piece of the water.\n\n“Nothing,”\
said the engineer; “Neb,” replied the engineer, \
“but I am on the horizon,” said Cyrus Harding, \
“but I do not think that the matter?”"
print("'",text, "'\nThis review is ", pred(text), ".")
出力イメージ
' They were the piece of the water.
“Nothing,” said the engineer; “Neb,” replied the engineer, “but I am on the horizon,” said Cyrus Harding, “but I do not think that the matter?” '
This review is negative .否定的でした。。。
こうして、手塩にかけてチューニングしたモデルで感情分析・感情予測できることは、我が子の成長を見届けているようで、胸にこみ上げるものがあります。
3. モデルを保存する
大切に保存しましょう。
# 感情分析 BERTモデル :訓練したモデルの保存
path = '/content/drive/MyDrive/pmlp/ch16_bert/model'
tokenizer.save_pretrained(path)
model.save_pretrained(path)保存したモデルを再度読み込む際のサンプルコードを置いておきます。
# 感情分析 BERTモデル :訓練したモデルの読み込み
path = '/content/drive/MyDrive/pmlp/ch16_bert/model'
new_tokenizer = DistilBertTokenizerFast.from_pretrained(path)
new_model = DistilBertForSequenceClassification.from_pretrained(path)GPUならではのディープラーニング~言語モデルのファインチューニング~を楽しく実行できました。
文章生成の仕組みをぜひ体感してみてください。
まとめ
今回は、Google Colab環境でGPUを利用して、BERTによる感情分析(分類)のファインチューニングに取り組みました。
IMDb映画レビューデータセットによる感情分析がフィナーレを迎えたのです。
この感情分析との間のさまざまなエピソードを思い出して、とても感慨深いです。
さて、遂にGPU非搭載パソコンでは太刀打ちできないステージになりました。
また、GPUを利用しても処理に時間がかかる状況になりました。
残り3章のディープラーニング(GAN、GNN)と強化学習について、時間とリソースの配分を考えて取り組む必要がありそうです。
# 今日の一句
print('深層学習モデルに対する感情移入とは')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回は第2章の線形代数の基礎:行列の転置とドット積の式を紹介します。
2つの列ベクトルがあります。
$$
\boldsymbol{a}=
\begin{bmatrix}
a_1\\
a_2\\
a_3
\end{bmatrix},
\boldsymbol{b}=
\begin{bmatrix}
b_1\\
b_2\\
b_3
\end{bmatrix}
$$
ベクトル$${\boldsymbol{a}}$$の転置を$${\boldsymbol{a}^T=[a_1, a_2, a_3]}$$と記述します。
ドット積を次のように記述します。
$$
\boldsymbol{a}^T\boldsymbol{b} = \sum_i a_i b_i =
a_1\cdot b_1+a_2\cdot b_2+a_3\cdot b_3
$$
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「AI・データサイエンスのための 図解でわかる数学プログラミング」
ビジネスの現場では今後、数学的知識の必要度が高くなると言われています。
この書籍は、図解によって数学的な考え方を直感的に説明し、Pythonのコードを動かしてみて計算を体感することを目的に書かれています。
カバーする領域は、確率統計、機械学習、数理最適化、数値シミュレーション、深層学習です。
なんとか数学的な知識を獲得したくて、現在、ゆっくり読んでいます。
Pythonコードを動かして数式の気持ちに迫ってみたいです。
特に、テキストの範囲外である数理最適化・数値シミュレーションに取り組もうと思っています。
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?