
ジェネレーティブAIにクリエイターとしての不安を感じたので、Stable Diffusion環境をPCに構築してみた。

Blenderを使って映像制作の素材を作っていた際、フィードやニュースでChatGPTやStableDefusionがもたらす世の中へのインパクトを見る機会が増えました。テキスト、イラスト、グラフィック、そして楽曲まで、デジタルコンテンツのすべてがジェネレーティブAIによって自動生成されるのを見て、驚愕し、不安と虚無感を感じました。
「今、BlenderやUnityを学んでいることは、数年後には無駄になってしまうのだろうか?」「数年後には誰もが簡単にオリジナルの3Dモデルを作り、デジタルアニメーションや映画を作れるようになるのだろうか」
このような不安と希望が入り混じった感覚になり、いちクリエイターとして強烈な危機感を感じました。
むしろ、このままジェネレーティブAIに触れずにいると、余計に不安になる気がしました。その悩みをChatGPTに問いかけると、こんな答えが帰ってきました。
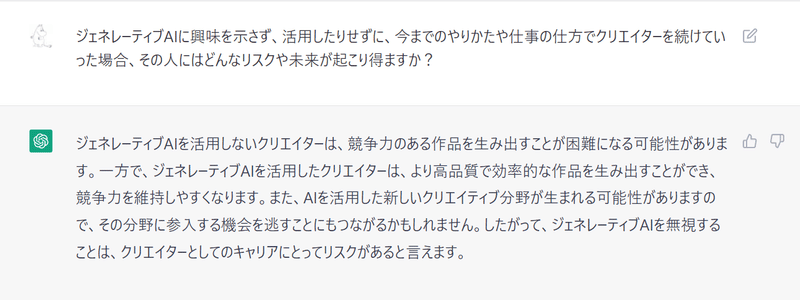
そこで、いっそのことStableDiffusionを自分のPC環境で動かすことにしてみました。環境を構築して、自分で画像合成してみれば、そのメリット・デメリットなどを実感でき、技術を知ることで不安が解消されるのではないか?と思ったのが動機です。
※ 下記のトラブルのログは、備忘録なので、正確なトラブルシューティングではありません。リンクをはった先の記事で、詳しく対応策が書かれているのでそちらを参考ください。
WindowsPCにStable Diffusionをインストールしようとして挫折
こちらの「窓の杜」の記事に従ってWindowsPCにStableDiffusionの環境を構築しました。「txt2img.py」でプロンプトを実行しましたが、ライブラリ不足でエラーになりました。必要なライブラリを「pip install」でインストールしますが、次々と不足ライブラリが出て、その度に調査して解決することの繰り返しになりました。
次第にPython3でのprint構文のエラーを解決するために、anacondaのソースを修正していました。といってもprint文の構文変更なので()を追加するなどでした。
しかし、再現なく続く煩雑なエラー解決をしているうちに途方に暮れてしまいました。進む方向をあきらかに間違えていることに気づき、はやくも挫折しました。
Gitをあらためてインストールしなおす
こちらのサイトに「窓の杜」の記事どおりにやってもうまくいかなかった事例が書いてあるのを発見しました。記事の内容に従って、一度構築した環境を削除します。
Gitをあらためてインストールしました。
前の環境が残っていて
conda env create -f environment.yamlが実行できなかったので、下記のサイトを見て削除。
更にエラーが出たので、下記のサイトを見て解決しました。
ImportError: cannot import name 'SAFE_WEIGHTS_NAME' from 'transformers.utils' (/usr/local/lib/python3.8/dist-packages/transformers/utils/__init__.py)
ちょっとづつ進めていくも、GPUのメモリが足りない問題が出ました。こればかりはPCに投資が必要なので、断念しようと思いました。
スペック不足のPCでもなんとか動かす方法もあった
自分のPCは4年くらい前に買ったPCなので、グラボのメモリが5GBで、StableDiffusionを動かすにはあきらかにスペック不足でした。
ここで諦めようかと思ったのですが、最初に参考にした「窓の杜」の記事の最後の方に
VRAMが10GB未満の環境でも実行する方法
と書いてあったので、記事内のオプションを活用し、かつ「txt2img.py」のソースコードを記事のとおりに修正しました。
下記のコマンドで画像のサイズを落とすことで無事に画像を生成することができました。
python scripts/txt2img.py --prompt "photo of a …" --plms --W 384 --H 256
生成に成功したときは感動しました。画像が小さくて、Twitterなどで流れているアーティスティックなジェネレーティブAI画像とはほど遠いですが、自分のPCに生成されるのはちょっと嬉しかったです。

後からふりかえると、こちらのブログの記事が、自分が辿ったエラー解決と同じ感じで、かつ詳細に記載されているので、復習的に参考になりました。
ローカルPCにStableDiffusionをインストールして画像生成して得られたこと
Pythonの経験はほとんどないので、環境構築するだけでもヘトヘトになりました。でも、Webツールを活用して画像生成するのではなく、CUI上でインストールして環境構築したので、StableDiffusionがどのような構成で動いているのか、その一端に触れられて勉強になりました。
また、途中で道を間違えて「無数にpip installでライブラリをインストールし続ける」「エラーメッセージに言われるまま、pythonファイルを修正する」といった的はずれな作業も、機械学習用のライブラリの存在を知るきっかけになって、全くの無駄ではありませんでした。
ジェネレーティブAIに対する不安は解消されたか?
結論「不安は解消された」と思います。
理由は、プロンプトをいじって画像合成をしている感覚が、UnityやBlenderなどをいじっている時のような、ソフトウェア的な習熟さを求められるツールだと感じたからです。
ローカル環境に構築するのも、個人的にはハードルの高さを感じました。また、もっと高クオリティな画像を生成するなら、Stable Diffusion web UIやビジュアル系のモデルデータを活用して、リッチな環境を構築していく必要があると思います。なにより、GPUも10GBくらいないと高画質な画像は合成できない気がします。
もちろん、PCクライアントで環境構築せず、Webのサービスを利用するのが合理的で、サービス料金を支払って活用するのが生産的かと思います。しかし、Webサービスであったとしても、ソフトウェア的な習熟度は求めらると感じます。
ちょうど、ChatGPTに人生相談した時に、こういうアドバイスをもらっていましたが、ふりかえってみるとすごく説得力のあるアドバイスだった気がします。

不安が少し薄れ、やりたいことが見えてきた
個人的に、今までは「Webサービスに呪文を投げると、超美麗なCGが出力される。2D画像から、完成された3DのFBXファイルがエキスポートできる」という魔法のツールを想像していて、不安に感じていました。
環境構築して画像生成してみると、一般社会に溶け込んでコモディティ化するには、まだ発展途上のツールであると感じました。StableDiffusionがクリエイターの職業やポジションを奪うには、もう少し時間がかかりそうな気がします。
気持ち的には「不安」が「興味や好奇心」に変わったので、機会があればStable Diffusion web UIやビジュアル系のモデルデータを活用して、クオリティの高い画像生成にチャレンジしてみたいと思います。
あと、グラボのメモリがあきらかに足りないので、PCを買い替えるためにお金を稼がねばと思いました。
この記事が気に入ったらサポートをしてみませんか?